数据可视化-python
数据可视化
matplotlib,它是一个数学绘图库,我们将使用它来制作简单的图表,如折线图和散点图。然后,我们将基于随机漫步概念生成一个更有趣的数据集——根据一系列随机决策生成的图表。
Pygal包,它专注于生成适合在数字设备上显示的图表。通过使用Pygal,可在用户与图表交互时突出元素以及调整其大小,还可轻松地调整整个图表的尺寸,使其适合在微型智能手表或巨型显示器上显示。
1.生成数据
1.1matplotlib画廊
要查看使用matplotlib可制作的各种图表,请访问https://matplotlib.org的示例画廊。单击画廊中的图表,就可查看用于生成图表的代码。
中文文档地址:Matplotlib
1.2绘制简单折线图
1 | |
我们首先导入了模块pyplot,并给它指定了别名plt,以免反复输入pyplot。在线示例大都这样做,因此这里也这样做。模块pyplot包含很多用于生成图表的函数。
我们创建了一个列表,在其中存储了前述平方数,再将这个列表传递给函数plot(),这个函数尝试根据这些数字绘制出有意义的图形。
如何让显示中文
如何电脑已安装了相应的字体如‘微软雅黑’,则可以设置plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']指定字体,即可实现中文显示。
1 | |

1.3使用scatter()绘制一系列点
要绘制一系列的点,可向scatter()传递两个分别包含x值和y值的列表。
1 | |

1.4自动计算数据
手工计算列表要包含的值可能效率低下,需要绘制的点很多时尤其如此。可以不必手工计算包含点坐标的列表,而让Python循环来替我们完成这种计算。
matplotlib允许你给散点图中的各个点指定颜色。默认为蓝色点和黑色轮廓,在散点图包含的数据点不多时效果很好。但绘制很多点时,黑色轮廓可能会粘连在一起。要删除数据点的轮廓,可在调用scatter()时传递实参edgecolor=’none’
自定义颜色
要修改数据点的颜色,可向scatter()传递参数c,并将其设置为要使用的颜色的名称,如下所示
1 | |
你还可以使用RGB颜色模式自定义颜色:
1 | |
值越接近0,指定的颜色越深,值越接近1,指定的颜色越浅。
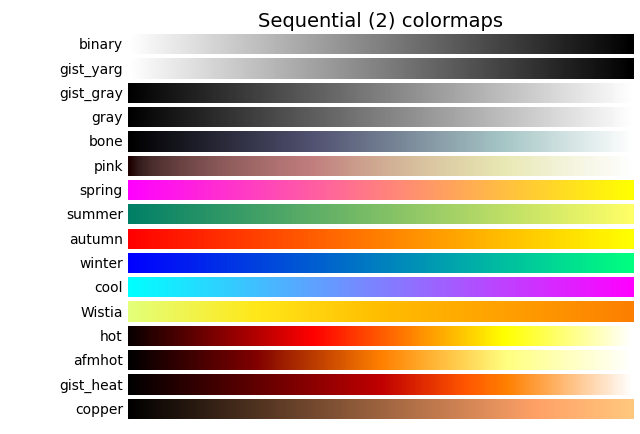
颜色映射
颜色映射(colormap)是一系列颜色,它们从起始颜色渐变到结束颜色。在可视化中,颜色映射用于突出数据的规律,例如,你可能用较浅的颜色来显示较小的值,并使用较深的颜色来显示较大的值
1 | |
我们将参数c设置成了一个y值列表,并使用参数cmap告诉pyplot使用哪个颜色映射。这些代码将y值较小的点显示为浅蓝色,并将y值较大的点显示为深蓝色.

注意:要了解pyplot中所有的颜色映射,请访问http://matplotlib.org/,单击Examples,向下滚动到Color Examples,再单击olormaps_reference。



1.5自动保存图片
要让程序自动将图表保存到文件中,可将对plt.show()的调用替换为对plt.savefig()的调用:
1 | |
第一个实参指定要以什么样的文件名保存图表,这个文件将存储到scatter_squares.py所在的目录中;第二个实参指定将图表多余的空白区域裁剪掉
1.6随机漫步
随机漫步是这样行走得到的路径:每次行走都完全是随机的,没有明确的方向,结果是由一系列随机决策决定的。
在自然界、物理学、生物学、化学和经济领域,随机漫步都有其实际用途。例如,漂浮在水滴上的花粉因不断受到水分子的挤压而在水面上移动。水滴中的分子运动是随机的,因此花粉在水面上的运动路径犹如随机漫步。我们稍后将编写的代码模拟了现实世界的很多情形。
RandomWalk类:
1 | |
图形化展示:
1 | |
给点着色
我们将使用颜色映射来指出漫步中各点的先后顺序,并删除每个点的黑色轮廓,让它们的颜色更明显。为根据漫步中各点的先后顺序进行着色,我们传递参数c,并将其设置为一个列表,其中包含各点的先后顺序。由于这些点是按顺序绘制的,因此给参数c指定的列表只需包含数字1~5000
1 | |

隐藏坐标轴
1 | |
为修改坐标轴,使用了函数plt.axes()(见Ø)来将每条坐标轴的可见性都设置为False。随着你越来越多地进行数据可视化,经常会看到这种串接方法的方式。为修改坐标轴,使用了函数plt.axes()(见Ø)来将每条坐标轴的可见性都设置为False。随着你越来越多地进行数据可视化,经常会看到这种串接方法的方式。
chatgpt解释plt.scatter与ax.scatter的区别:
plt.scatter和ax.scatter都用于绘制散点图,它们的区别在于使用的绘图方式和用法上略有不同。
plt.scatter是pyplot模块提供的函数,它是面向过程的绘图方式。你可以直接调用plt.scatter来创建一个散点图,并且在同一个函数调用中设置图形的各种属性,如点的大小、颜色、标签等。这种方式适合简单的绘图需求。示例:
2
3
4
5
6
7
8
9
10>import matplotlib.pyplot as plt
>x = [1, 2, 3, 4]
>y = [5, 6, 7, 8]
>plt.scatter(x, y, marker='o', color='blue')
>plt.xlabel('X')
>plt.ylabel('Y')
>plt.title('Scatter Plot')
>plt.show()
ax.scatter是使用面向对象的方式进行绘图,它需要先创建一个图形对象fig和一个子图对象ax,然后通过ax.scatter调用子图对象的方法来创建散点图,并设置图形的属性。这种方式更灵活,适合复杂的图形绘制需求,可以通过操作子图对象来进行更多的自定义设置。示例:
2
3
4
5
6
7
8
9
10
11>import matplotlib.pyplot as plt
>x = [1, 2, 3, 4]
>y = [5, 6, 7, 8]
>fig, ax = plt.subplots()
>ax.scatter(x, y, marker='o', color='blue')
>ax.set_xlabel('X')
>ax.set_ylabel('Y')
>ax.set_title('Scatter Plot')
>plt.show()总结来说,
plt.scatter是面向过程的方式,直接在当前图形上绘制散点图,而ax.scatter是面向对象的方式,需要先创建图形对象和子图对象,然后调用子图对象的方法来绘制散点图。使用面向对象的方式可以更灵活地控制图形的各个元素和属性。
1.7调整尺寸以适应屏幕
图表适合屏幕大小时,更能有效地将数据中的规律呈现出来。为让绘图窗口更适合屏幕大小,可像下面这样调整matplotlib输出的尺寸。
1 | |
可以增加分辨率参数:
1 | |
1.8使用Pygal模拟掷骰子
在数学领域,常常利用掷骰子来解释各种数据分析。
要了解使用Pygal可创建什么样的图表,请查看图表类型画廊:访问http://www.pygal.org/,单击Documentation,再单击Chart types。每个示例都包含源代码,让你知道这些图表是如何生成的
设置刻度标签中文
1 | |
zip()函数的使用:
可以使用
zip()函数将两个列表组合成一个元组列表。zip()函数将按索引位置将两个列表中的元素逐个配对,返回一个包含元组的迭代器。然后,你可以将迭代器转换为列表。以下是示例代码:
2
3
4
5
6>list1 = [1, 2, 3]
>list2 = ['a', 'b', 'c']
>combined_list = list(zip(list1, list2))
>print(combined_list)输出结果为:
>[(1, 'a'), (2, 'b'), (3, 'c')]在示例中,
zip(list1, list2)将列表list1和list2中的元素逐个配对,得到一个元组的迭代器。然后,通过list()函数将迭代器转换为列表,得到了一个包含元组的列表combined_list。
2.下载数据
要在文本文件中存储数据,最简单的方式是将数据作为一系列以逗号分隔的值(CSV)写入文件
csv模块包含在Python标准库中,可用于分析CSV文件中的数据行。
- enumerate():用来获取每个元素的索引及其值。
2.1模块datetime()
方法strptime()可接受各种实参,并根据它们来决定如何解读日期:
| 实参 | 含义 |
|---|---|
| %A | 星期的名称,如Monday |
| %B | 月份名,如January |
| %m | 用数字表示的月份(01~12) |
| %d | 用数字表示月份中的一天(01~31) |
| %Y | 四位的年份,如2015 |
| %y | 两位的年份,如15 |
| %H | 24小时制的小时数(00~23) |
| %I | 12小时制的小时数(01~12) |
| %p | am或pm |
| %M | 分钟数(00~59) |
| %S | 秒数(00~61) |
2.2fill_between()方法
fill_between(),它接受一个x值系列和两个y值系列,并填充两个y值系列之间的空间
1 | |
实参alpha指定颜色的透明度。Alpha值为0表示完全透明,1(默认设置)表示完全不透明。通过将alpha设置为0.5,可让红色和蓝色折线的颜色看起来更浅。
我们向fill_between()传递了一个x值系列:列表dates,还传递了两个y值系列:highs和lows。实参facecolor指定了填充区域的颜色,我们还将alpha设置成了较小的值0.1,让填充区域将两个数据系列连接起来的同时不分散观察者的注意力
3.人口地图数据
Pygal中的地图制作工具要求数据为特定的格式:用国别码表示国家,以及用数字表示人口数量。处理地理政治数据时,经常需要用到几个标准化国别码集。
我们的数据中,国别码是三位的,而pygal的地图工具使用两位国别码。要使用pygal绘制世界地图。需要安装依赖包。
1 | |
国别码位于i18n模块
from pygal_maps_world.i18n import COUNTRIES这样就导入了, COUNTRIES是一个字典,键是两位国别码,值是具体国家名。
1 | |
完整代码:
1 | |
1 | |

人口数据: