Python中文指南:从零到一的零基础 Python 教程
Python中文指南:从零到一的零基础 Python 教程
版权归iswbm所有


第一章:安装运行
1.1 【环境】快速安装 Python 解释器
Python 是一门解释性脚本语言,因此要想让你编写的代码得以运行,需要先安装 CPython 解释器。
根据你电脑的系统以及位数不同,安装步骤也有所差异。
- Windows 系统:系统无自带 Python 解释器,需要自行安装
- Mac 系统:系统自带 Python 2.7,需要自行安装 Python 3
由于 Python 2.x 已经不再维护了,因此本文会带大家安装CPython 最新版本: Python 3.9 (截止撰稿时最新:2020/12/16)。
同时本系列教程都将以 Python 3.9 版本进行讲解,不负责任的讲,可能是全网最新的 零基础系列教程。
1. 下载解释器
进入 Python 官网,目前 Python 最新 Python 稳定版为 3.9,点击如下链接
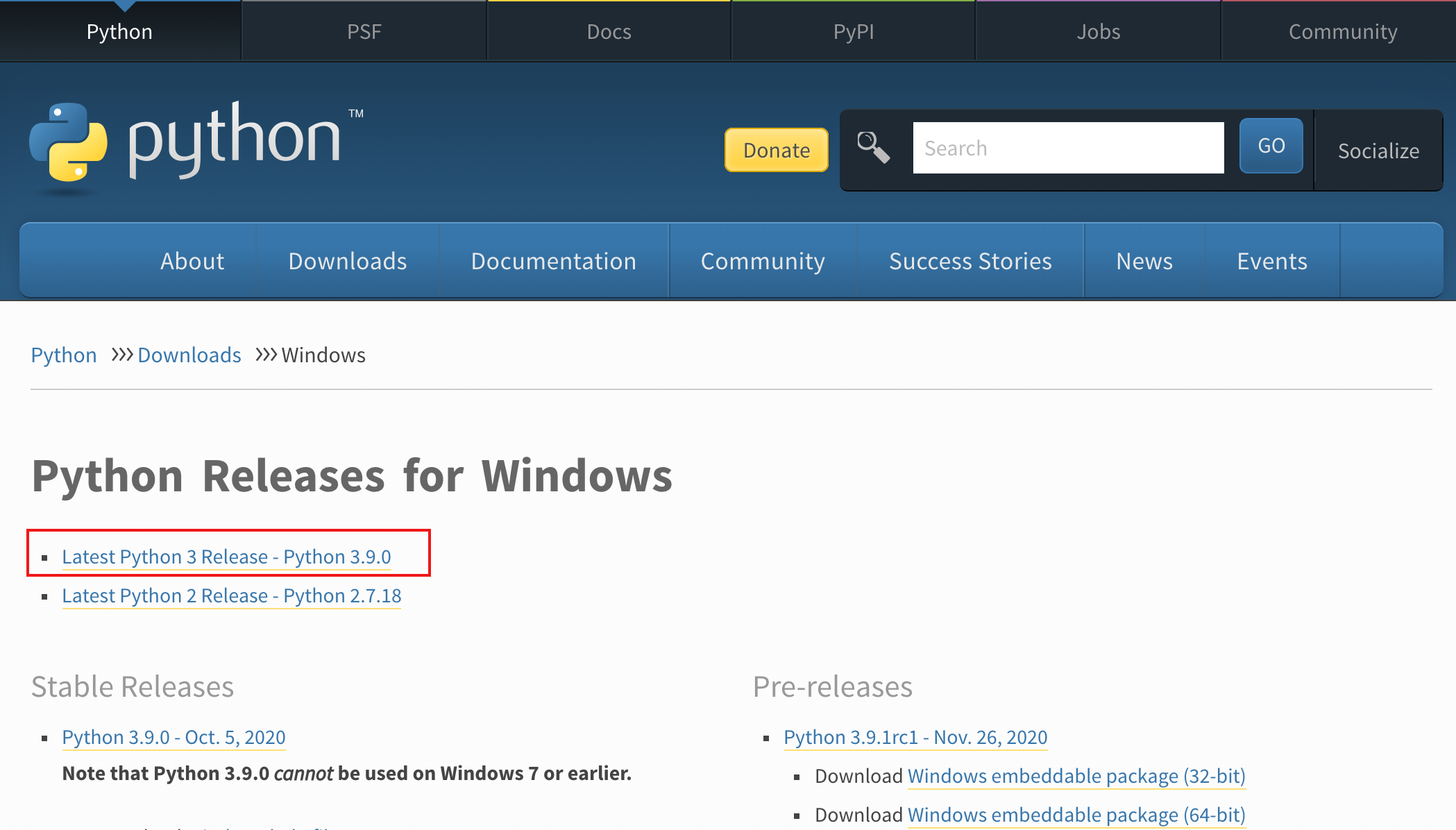
直接跳到最后,根据你电脑系统以及的位数
- Win 32 位:选择 Windows x86 executable installer
- Win 64 位:选择 Windows x86-64 executable installer
- Mac :Python-3.9.1-macosx10.9.pkg
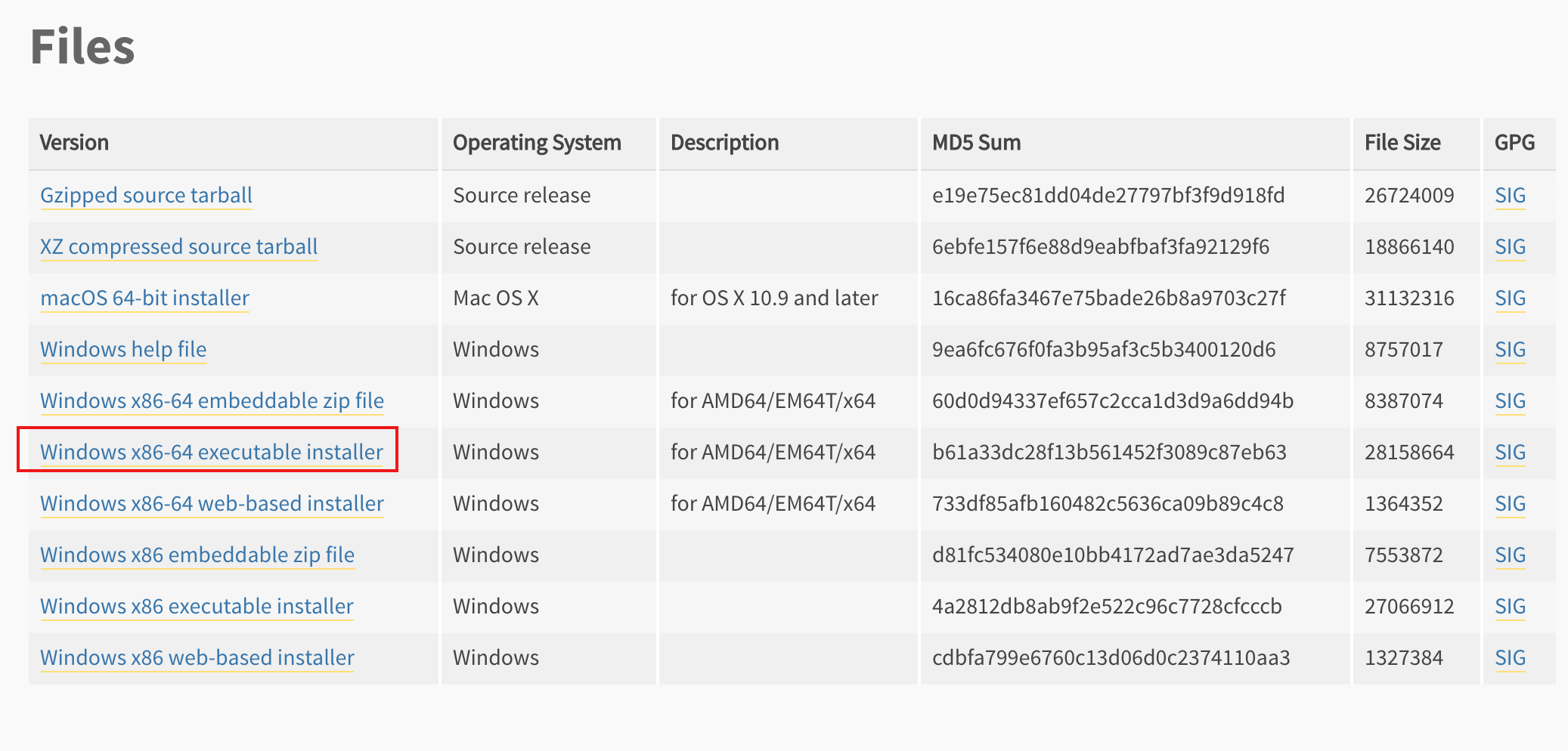
下载下来后,根据你的电脑系统选择后面的内容进行阅读。
2. Win 安装
下载到本地后,双击打开开始安装
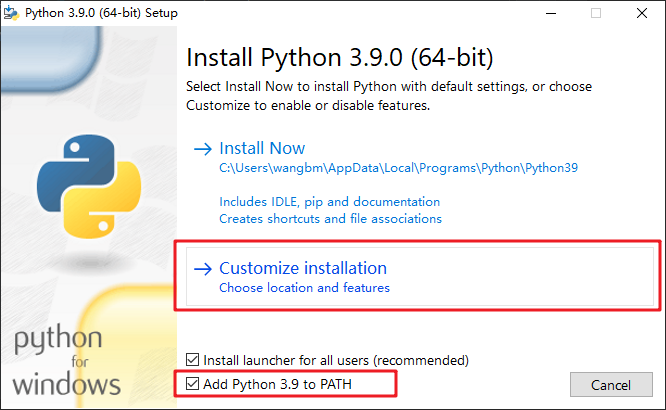
记得勾选 Add Python 3.9 to PATH,这是把你的 Python 路径加入到系统环境变量中。如果不想自定义选择安装路径,可以直接点击 Install Now,如果要选择安装路径,点击下图位置。
然后全部选上,然后点击 Next
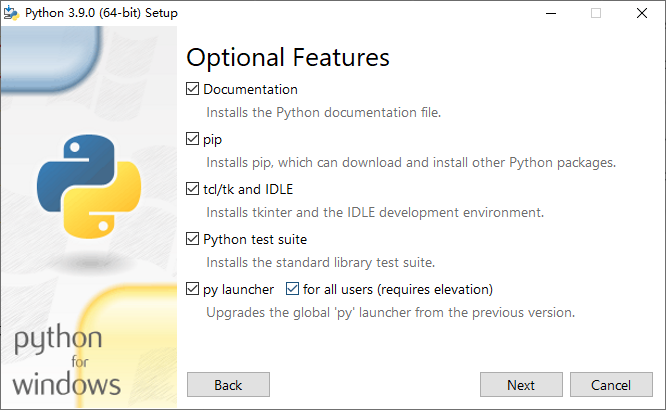
这里根据需要进行打勾,一般默认就行,然后点击 Browse ,选择你想要把 Python 安装到的哪那个目录里。
然后再直接点击 Install 开始安装。
安装过程只要几分钟就行
出现如下界面,说明安装过程已经结束。
安装是安装上了,那么如何验证呢?
使用 windows 搜索 cmd,选择 命令提示符 (我们把这个称之为你的终端)
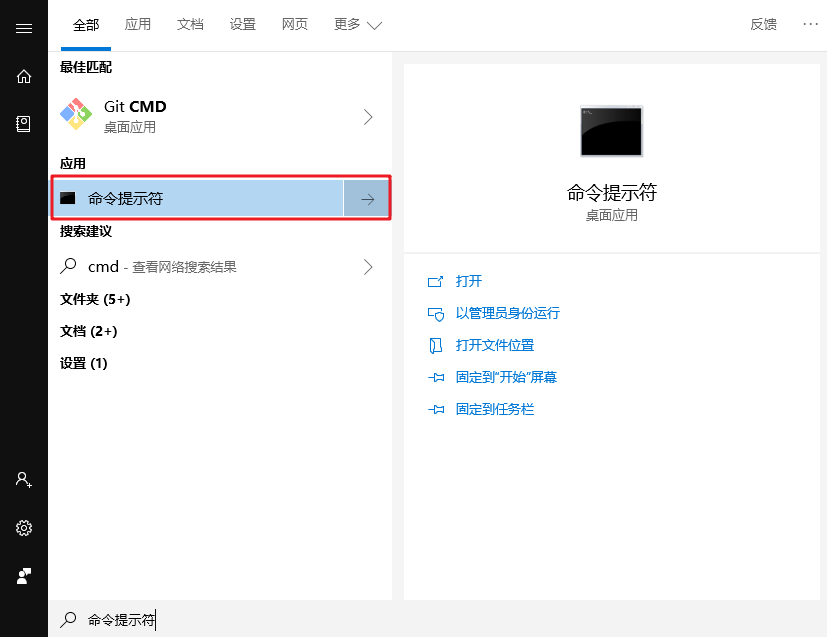
然后敲入 python ,若出现如下界面,则说明 Python 已经成功安装到你的机器上。
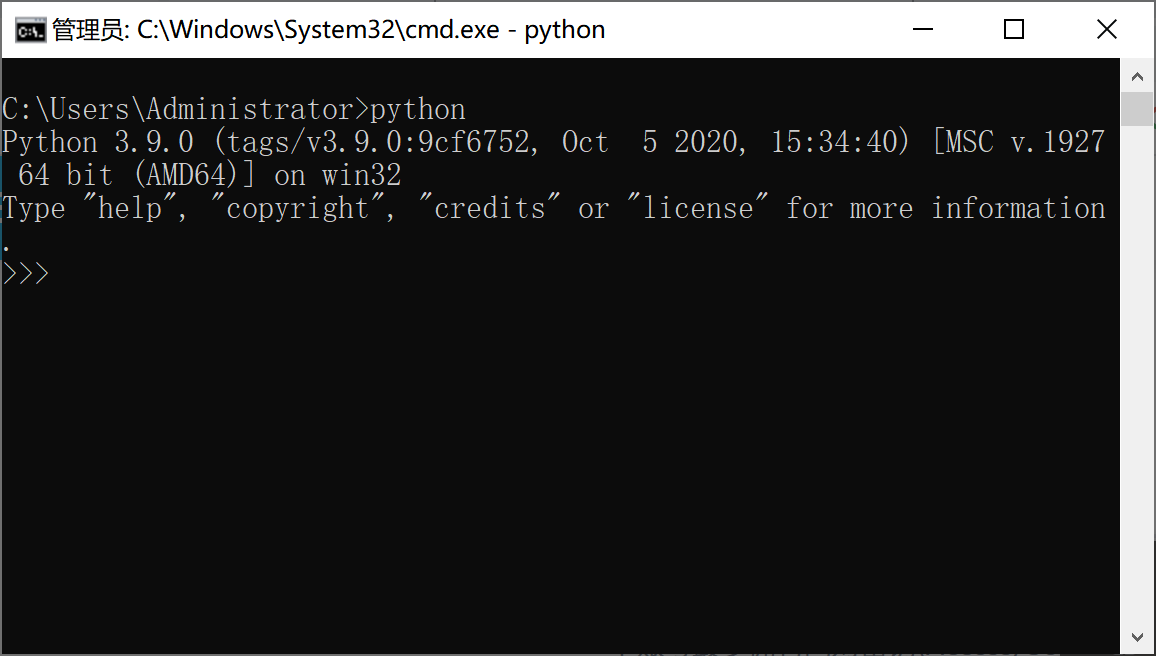
3. Mac 安装
下载到本地后,双击打开开始安装

出现如下界面,一直点继续
直到出现如下界面,输入密码开始安装
安装的速度非常地快,大概在一分钟左右
打开Terminal 或者 iTerm(同样我们把这个称之为你的终端),输入 Python 3 ,如果进入如下界面,说明 Python3 已经安装完成。
1.2 【环境】Python 开发环境的搭建
理论上只需要你安装了 CPython 解释器后,就可以开始写 Python 代码了。为了让你的在写代码时,有一个更加友好的编码体验。就有人开发了一堆的编辑器。
这些编辑器,具有代码高亮,代码提示自动补全的各种功能,如果没有这些编辑器,我想你没两天就会放弃编程这条路了。
因此在开始学习使用 Python 写代码时,首先要教大家搭建一个舒适的开发环境。
在这里我推荐大家使用 PyCharm 这个软件,它不只是一个简单编辑器,而是一个由 Jetbrain 公司为 Python 专门开发的 Python 语言集成开发环境。
也许你还不知道 Jetbrain ,我来简要介绍一下,Jetbrain 是一家专业的 IDE (Integrated Development Environment )生产商,只要是市面上主流的编程语言,Jetbrain 都有相应的产品。
比如:Python 对应 PyCharm ,Golang 对应 Goland,Java 对应 IntelliJ IDEA,C 语言对应 Clion 等等。
在这些众多的 IDE 中,有一些提供了多种版本:教育版、社区版 和 专业版。
PyCharm Edu is based on PyCharm Community Edition and comprises all its features, making it just perfectly suitable for writing professional projects with Python.
教育版:教育版是免费的,具备社区版的所有功能,除此之外,还提供有一个教学功能,因此它更适合学生。老师可以用它创建教学,学生可以通过他完成教学任务。
社区版:就是阉割版的专业版,它也是免费的,如果你并不需要使用专业版才有那些功能,可以选择社区版。
专业版:提供所有 PyCharm 的功能,虽然是收费的,但是可以试用一个月。
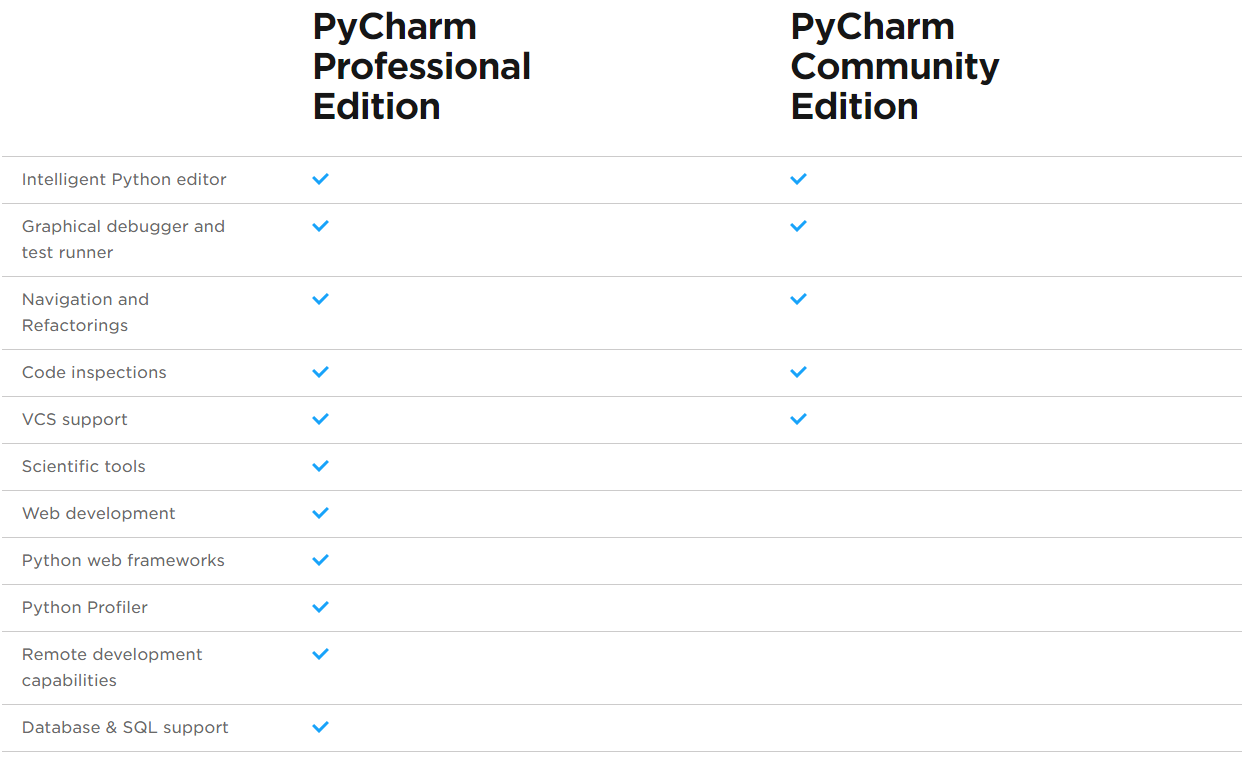
社区版和专业版在功能上有哪些区别呢?你可以看下面这个表格。
可以看出专业版比社区版多了 科学工具、WEB 开发、Python Web 框架、Python 代码分析、远程开发调试、数据库支持。
社区版的功能有限,有些非常好用的功能只有专业版才有,比如 远程调试。
如果你想使用到专业版,那有什么办法呢?
- 有钱的就是大爷,付费购买。
- 穷人自有穷活法,每次试用一个月,试用期到,卸载干净,再来一次。
- 利用学生与教师的特权,可申请免费使用
- 若你有开源项目,也可以申请免费使用
- 用一些
非寻常手段(也就是破解)来实现。
破解的方法,其实还分很多种:
- 可以使用注册服务器的方式,优点是非常方便,缺点是过一段时间就有可能失效,不稳定。
- 还可以使用破解补丁的方式,优点是永久破解(使用期限到 2099 或者 2100年,某种意义上算是永久了),缺点是对于最新版的 PyCharm 你可能找不到相应的破解补丁。如果要使用这种方法,就意味着你得使用旧版的 PyCharm 。
- 使用绿色免安装的 PyCharm 安装包,其实原理和第二种一样,这一种只是别人帮你破解好,你直接用而已。只适用于 Windows 。
那么这么多版本,该怎么选择呢?
一般来说:
- 如果你是学生,那么可以直接向 Jetbrain 免费申请专业版。
- 如果你是新手,直接安装社区版就行了,功能已经够用了。
- 如果你想使用更多好用的 专业版功能,那么花钱去购买吧。
如果你暂时付不起购买费用,可以加下面微信,我这有 绿色免安装的专业版,对,就是那种连安装都不用安装的 专业版。

1. 下载链接
PyCharm for Windows :https://www.jetbrains.com/pycharm/download/#section=windows
PyCharm for Mac :https://www.jetbrains.com/pycharm/download/#section=mac
PyCharm for Linux :https://www.jetbrains.com/pycharm/download/#section=linux
2. 安装步骤
下载完成后,双击 exe 文件
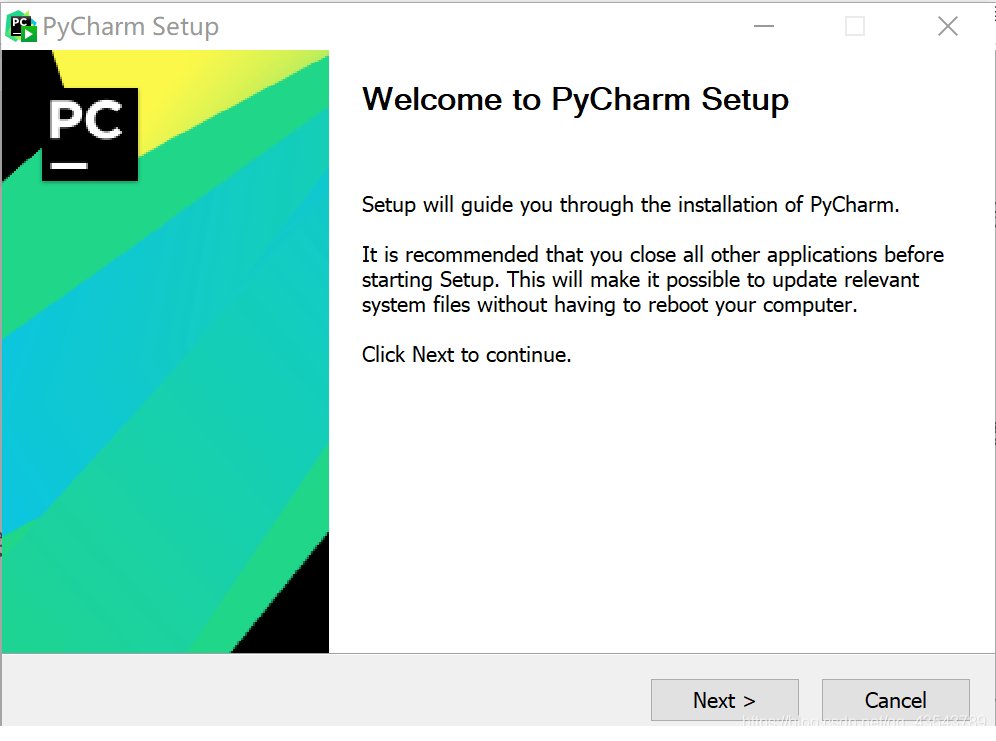
选择安装目录,Pycharm需要的内存较多,建议将其安装在D盘或者E盘,不建议放在系统盘C盘:
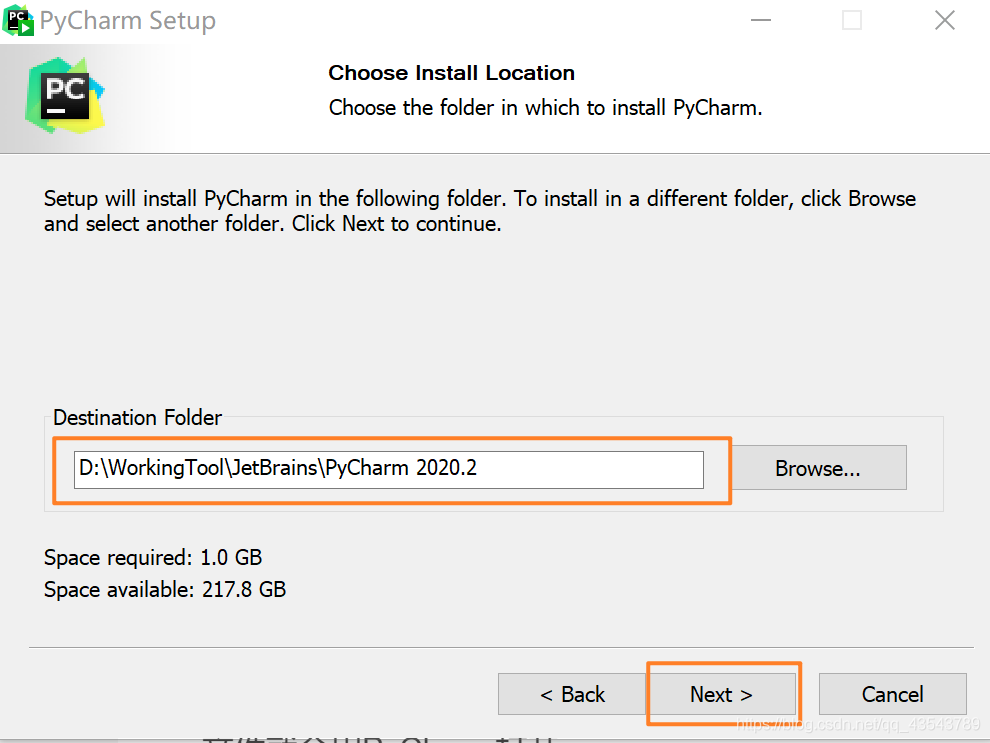
选好路径后,点击 Next ,创建桌面快捷方式等一系列选项参照下图勾选!
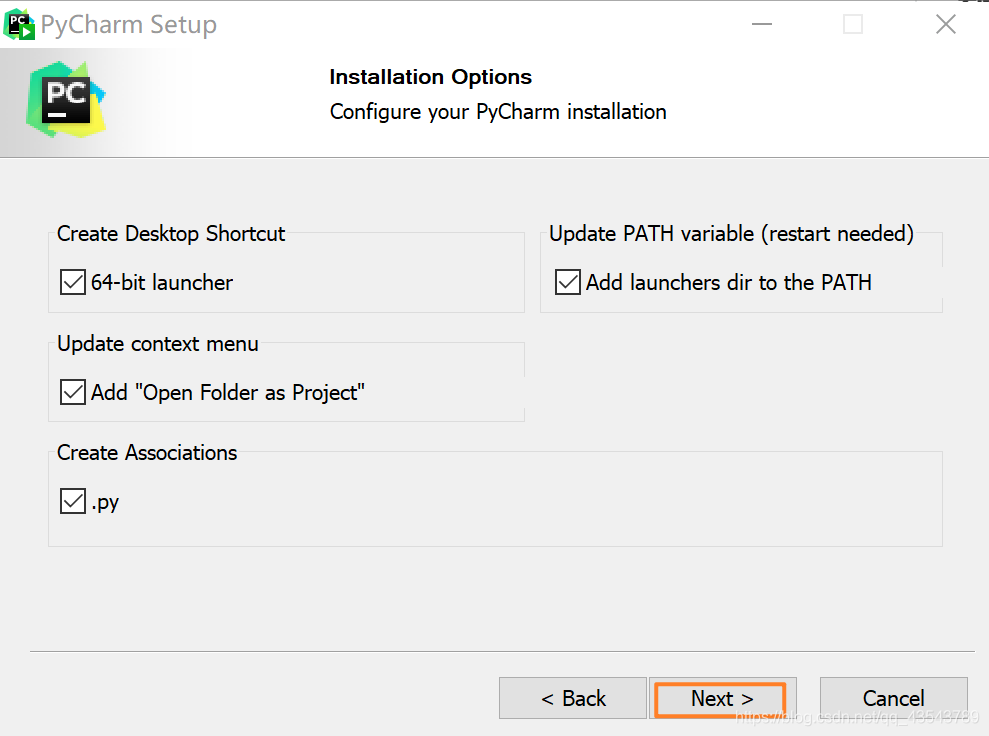
最后默认安装即可,直接点击Install。
7、耐心的等待两分钟左右。
之后就会得到下面的安装完成的界面
点击Finish,Pycharm安装完成。
接下来对Pycharm进行配置,双击运行桌面上的Pycharm图标,进入下图界面:
选择Do not import settings,之后选择OK,进入下一步。
下面是选择主题
-> 这里默认选择黑色(左边黑色,右边白色)
-> 点击Next:Featured plugins
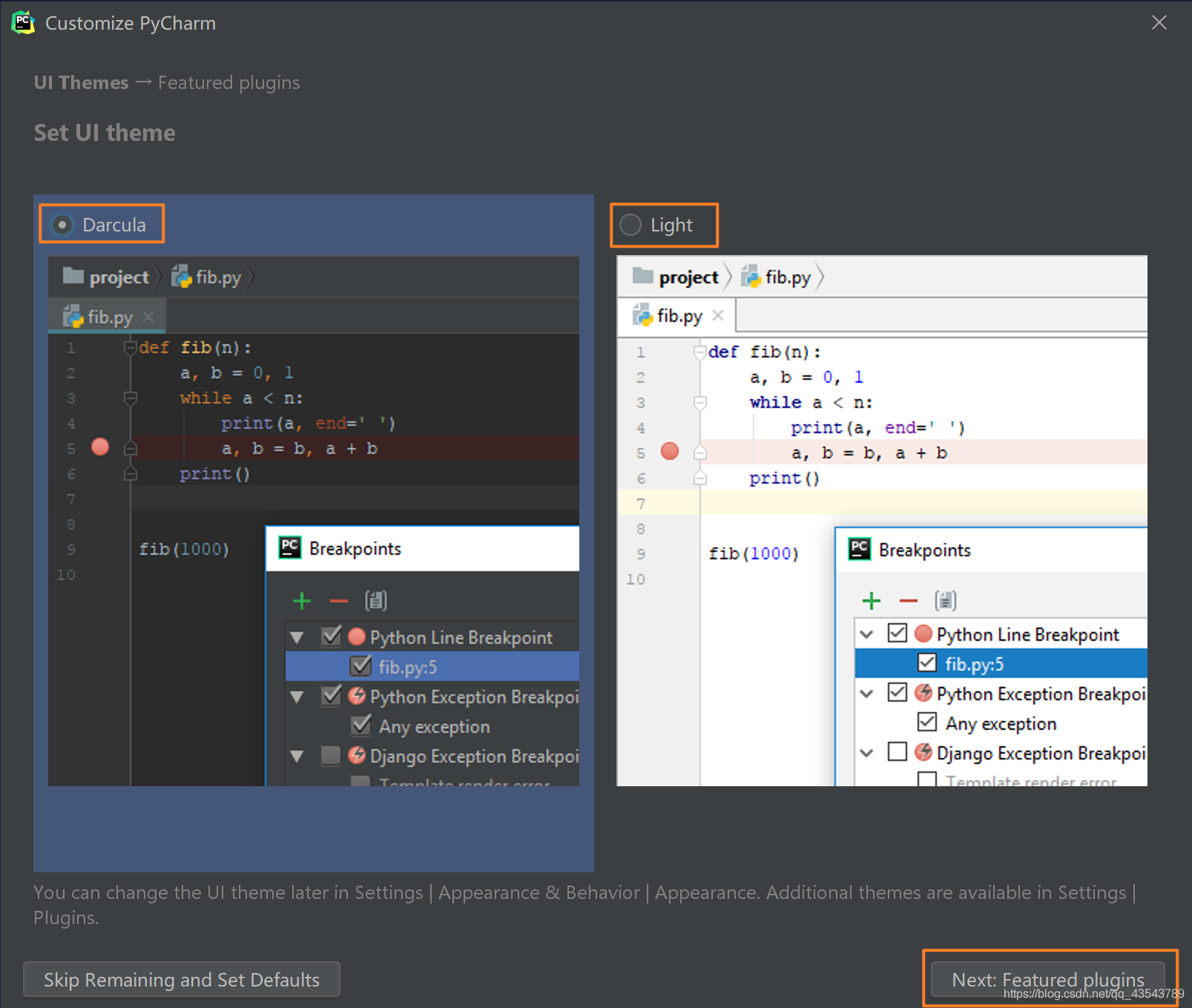
建议选择Darcula主题,该主题更有利于保护眼睛。
一切配置完成后,就会进入 PyCharm 的主界面。
首先,点击 View -> Appearance 勾上 Toolbar ,来调出工具栏,个人认为这个工具栏对于新手非常有用,使用频率很高。
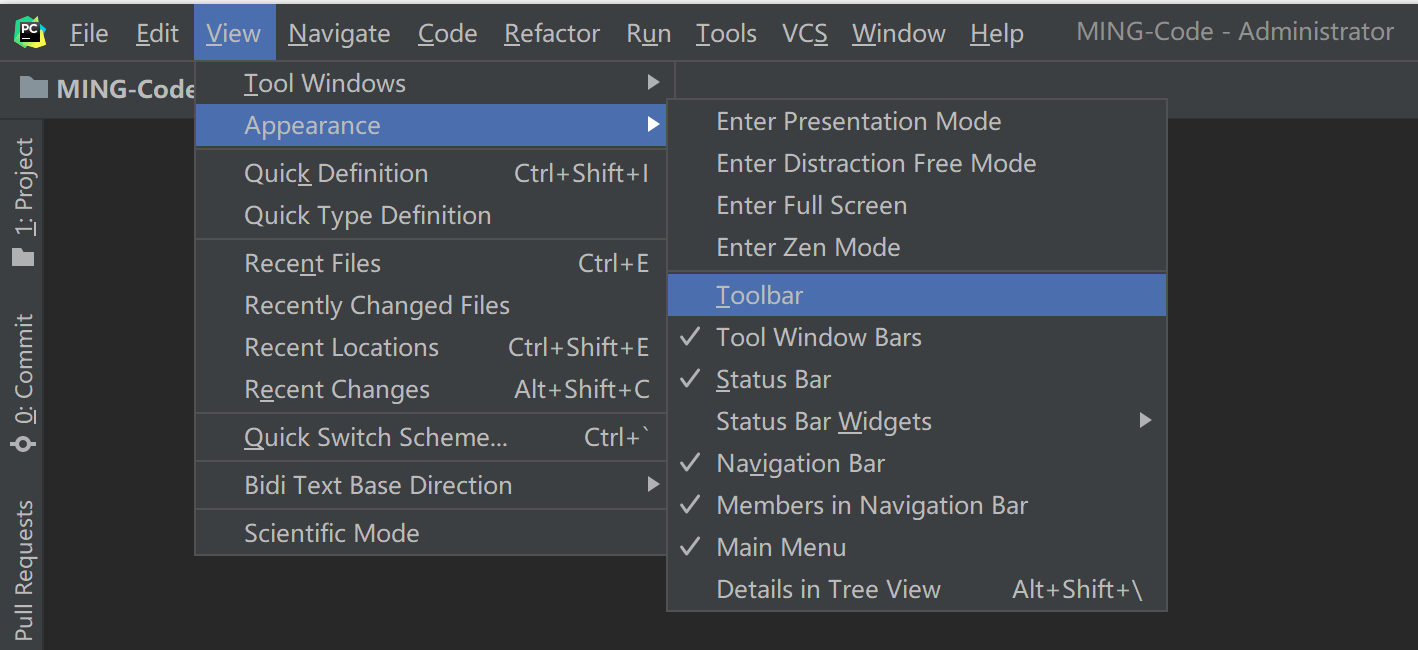
再然后,应该告诉 PyCharm 你的 CPython 解释器在哪里?不然后面要执行 Python 代码的时候,都不知道去哪里找。
点击 File -> Settings ,就会出现如下界面,在搜索框输入 interpreter ,点击右上角的 Add
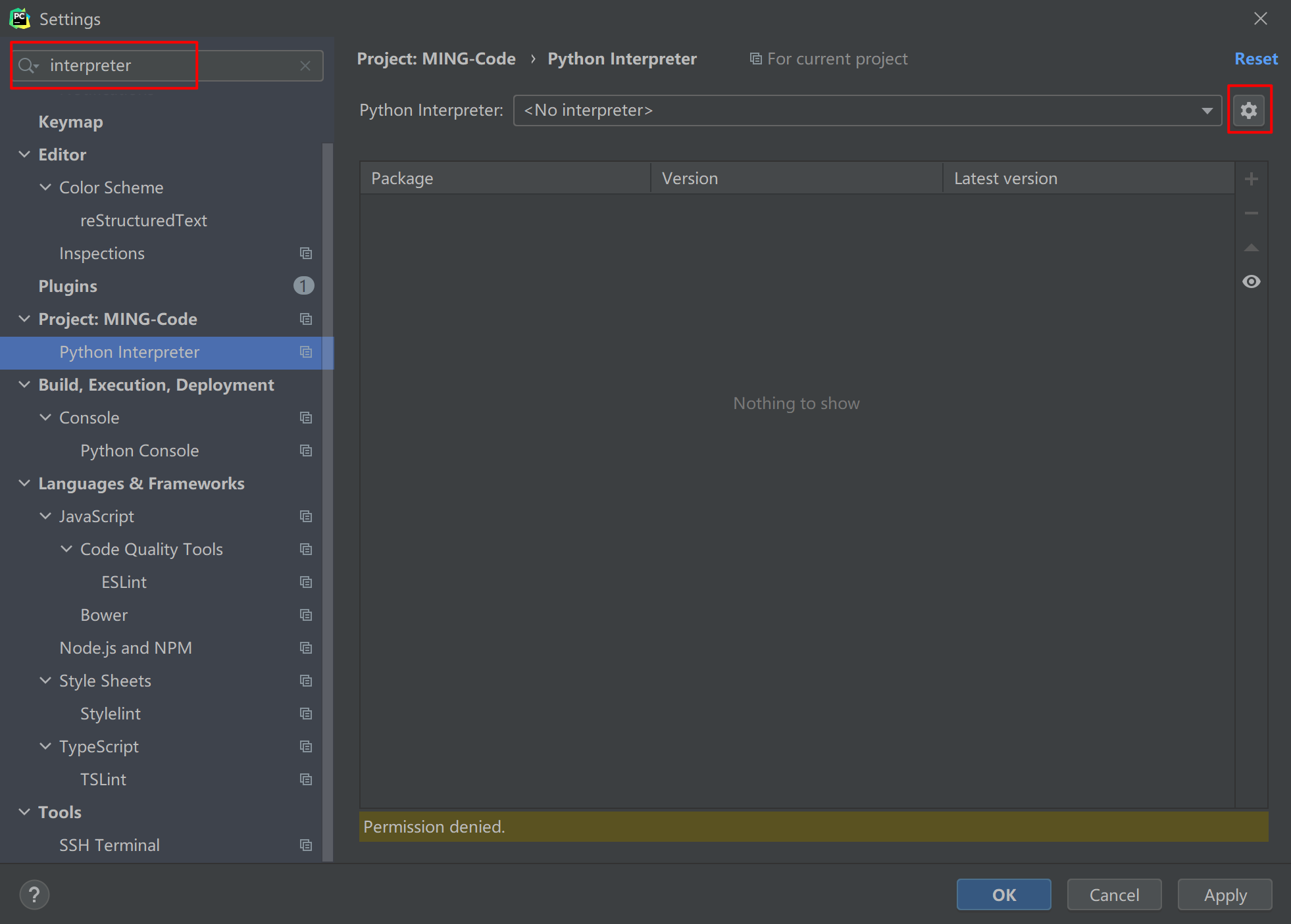
跳到如下界面,再选择 System Interpreter ,然后右边选择你在上一节中安装 CPython 的路径。
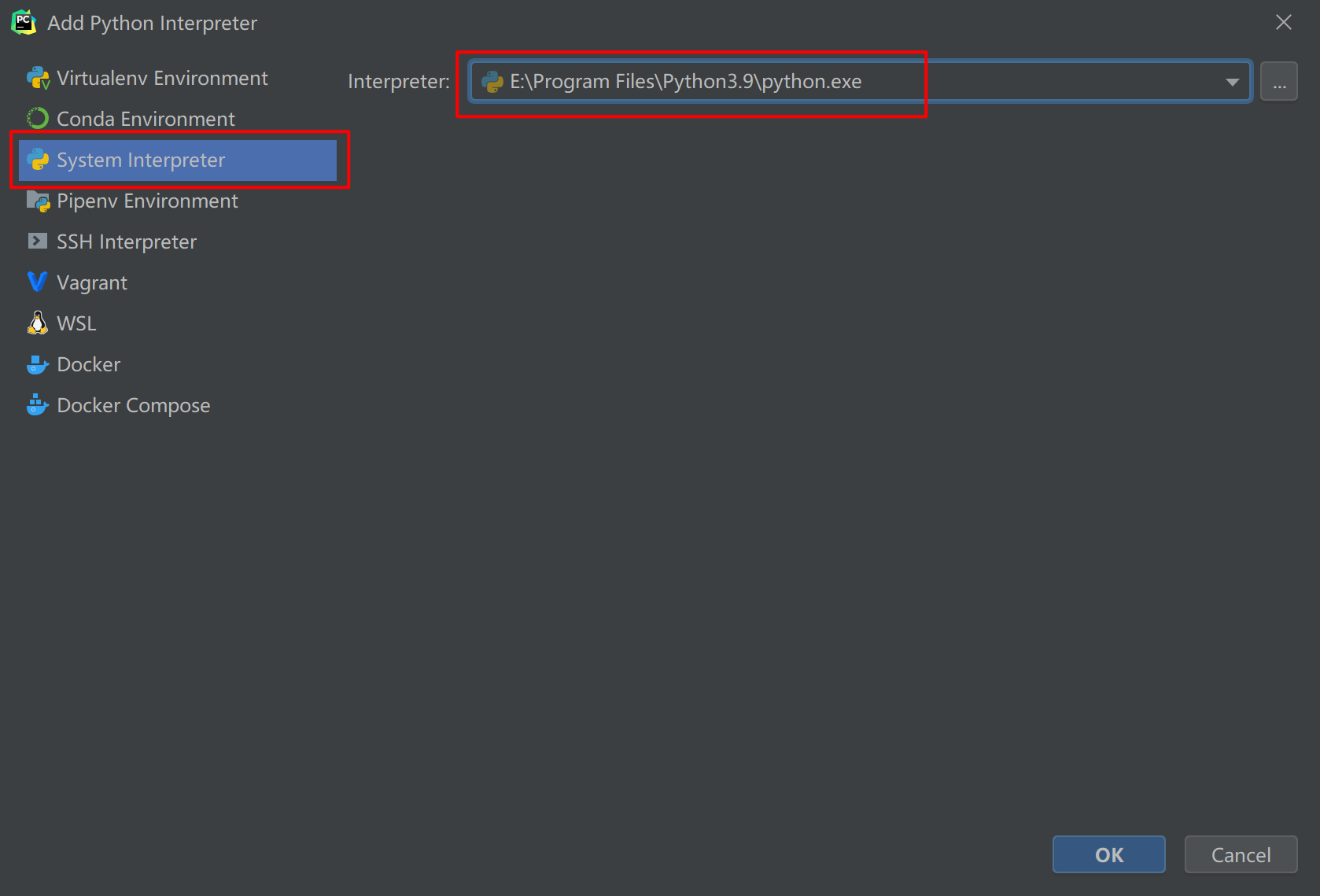
然后在文件夹下,新建一个 demo.py 的文件,并写入如下代码,然后再点击上面的 Add Configuration 配置脚本运行的参数
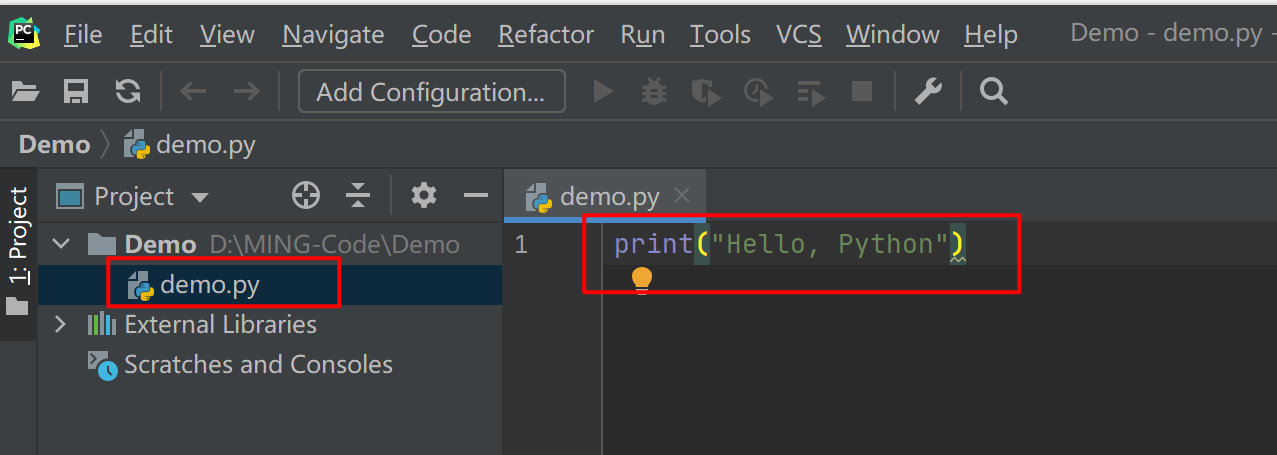
接下来,我们要在 PyCharm 中运行这个 demo.py 这个脚本了。右键然后选择 Run 'demo' ,或者直接按住快捷键:Ctrl+Shift+F10
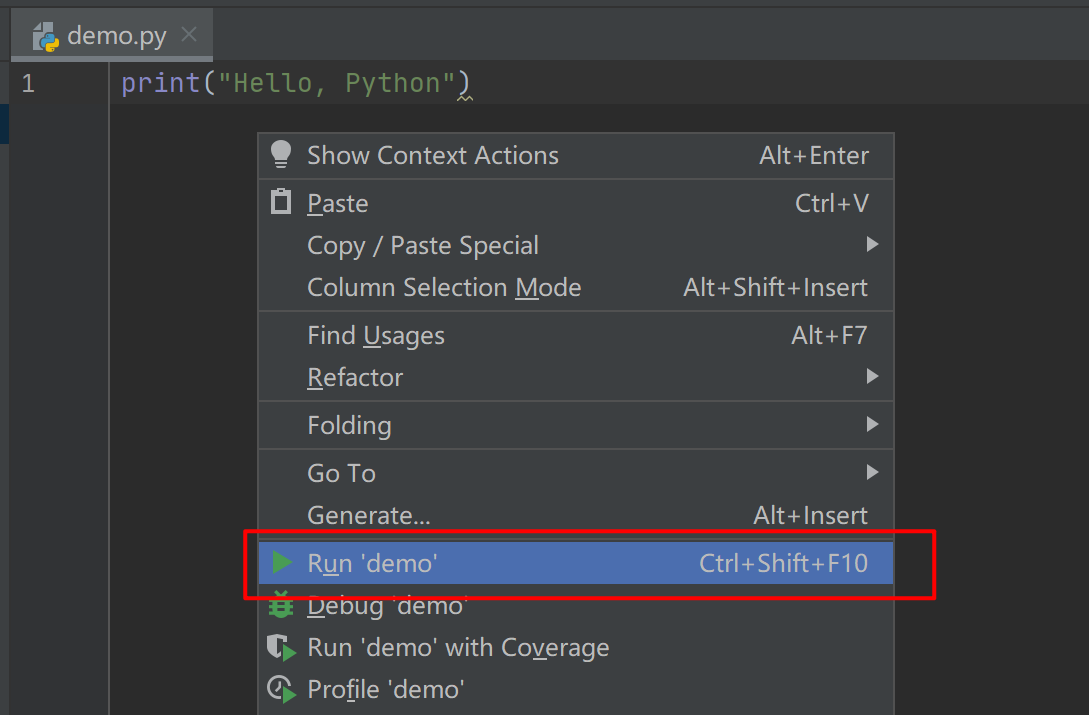
运行后,在下面就会弹出一个 Run 窗口,你在执行 Python 脚本时,所有的输出内容,都会出现在这里。
至此, PyCharm 这个非常好用的集成开发环境就配置完成了,后面我们就要正式开始接触代码了。
另外,关于 PyCharm 的使用,我花了两个月的时间,整理了一份非常实用且全面的 《PyCharm 中文指南》,点击这个链接,即可跳转学习:https://pycharm.iswbm.com/
1.3 【基础】两种运行 Python 程序方法
前两节我们安装好了 CPython 解释器,有了解释器,就可以运行 Python 程序了。
Python 程序的执行分为两种:
使用Python Console 界面上执行 Python 语句
使用命令行执行
.py后缀的脚本文件
下面分别对这两种方法进行演示。
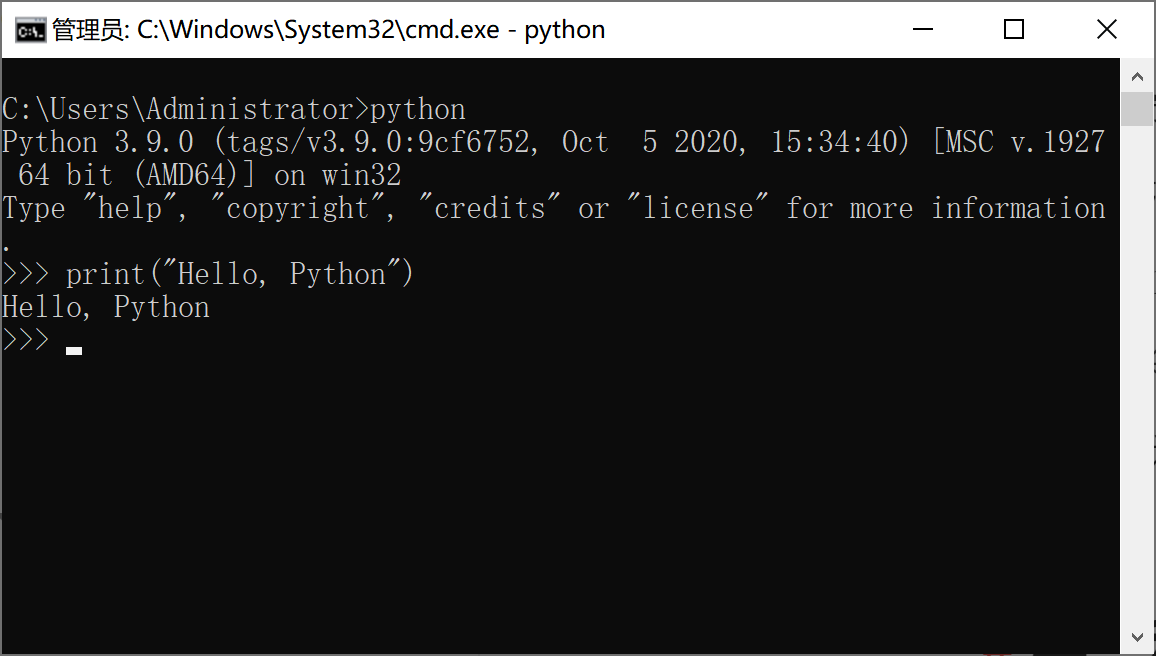
1. 第一种方法
首先打开你的终端,直接输入 python3 回车,然后输入 print("Hello, World"),就时候就会在屏幕上打印出 Hello, World 这几个字符。print 是 Python 的一个函数,通过它可以把你内容输出到终端屏幕上。这是我们写的第一行 Python 代码,调用的第一个 Python 函数,也是第一个 Python 程序。
2. 第二种方法
还记得我们在上一节中新建了个 Python 脚本文件 demo.py 吗?
当时我是使用 PyCharm 直接执行的,隐藏了一些运行细节,如果我不想通过 PyCharm 来执行脚本,有什么办法呢?
首先先进入脚本所在的文件夹,然后按住 Shift 和 右键,再点击如图位置打开 PowerShell
然后在 PowerShell 中输入 python dmeo.py,就可以执行这个 python 脚本啦。
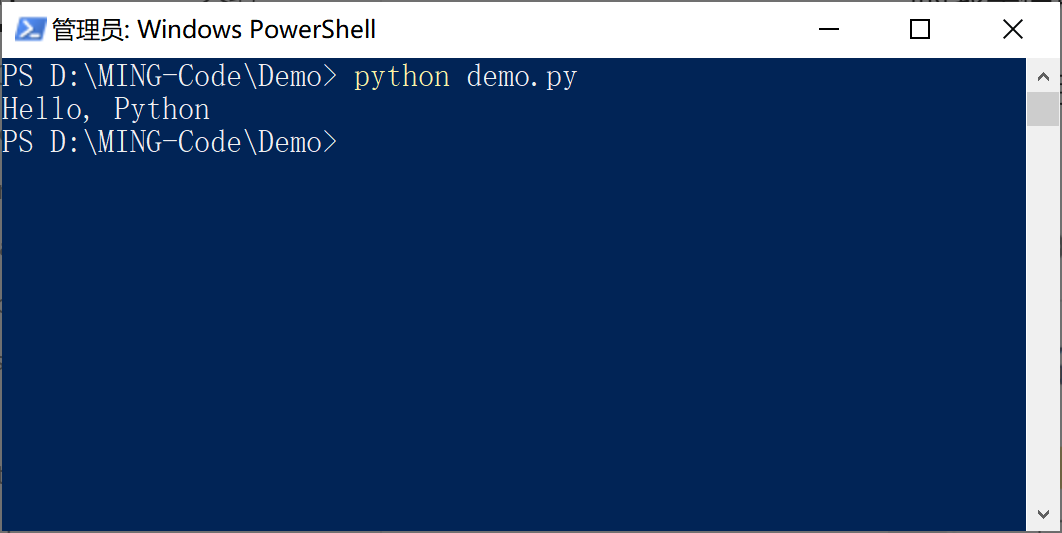
以上介绍了两种最原始的 Python 程序的执行方式。
3. 重要提示
- 在后面学习 Python 基础的时候,我在演示案例的时候,都会使用第一种方法(代码框里最前面会有
>>>标识),请你注意,后面不再提及。 - 实际上不管你使用哪个编辑器和 IDE 执行 Python 文件,它们的本质都是采用的第二种方法,因此这里很有必要向你介绍。
第二章:数据类型
2.1 【基础】常量与变量
变量:在程序运行过程中,值会发生变化的量
常量:在程序运行过程中,值不会发生变化的量
无论是变量还是常量,在创建时都会在内存中开辟一块空间,用于保存它的值。
1. 变量不需要声明类型
Python 的变量和常量不需要事先声明类型,这是根据Python的动态语言特性而来。
例如下面的 age 和 name 两个变量,在使用前没有进行任何的诸如 age int 和 name string 的类型声明,而这在一些静态语言中,比如 JAVA 和 Golang 中是必须的。
1 | |
2. 赋值与比较
Python 中 用 = 号来给变量赋值,比如下面这个表达式,age 这个变量的值就是 18
1 | |
与之相似的,新手会容易混淆的是 两个等号 == ,它表示的是比较两个值是否相等,如果相等返回 True,如果不相等返回 False
1 | |
3. 先创建再使用
每个变量在使用前都必须赋值,变量赋值以后才会被创建。
新的变量通过赋值的动作,创建并开辟内存空间,保存值。
如果没有赋值而直接使用,会抛出变量未定义的异常。例如:
1 | |
4. 赋值的方式
赋值的两种方式
第一种:单个直接赋值
1 | |
第二种:多个批量赋值
1 | |
第三种:先计算再赋值
1 | |
第四种:分别赋值
1 | |
5. 理解赋值的背后
理解变量在计算机内存中的表示也非常重要。
当我们写:a = "Jack" 时,Python解释器干了两件事情:
在内存中创建了一个
'Jack'的字符串对象;在内存中创建了一个名为a的变量,并把它指向
'Jack'。
而当你把一个变量a赋值给另一个变量b,这个操作实际上是将变量b指向变量a所指向的数据,例如下面的代码:
1 | |
通过 id() 可以查看变量值的内存地址,打印出来的 a 和 b的内存地址是一样的,因此二者其实是一个数据。
但如果继续对 a 进行赋值其他值, 会发现 a 的内存地址变了,而 b 的并没有变
1 | |
请牢记:Python中的一切都是对象,变量是对象的引用!:
- 执行a = ‘Jack’,解释器创建字符串‘Jack’对象和变量a,并把a指向‘Jack’对象;
- 执行b = a,解释器创建变量b,并且将其指向变量a指向的字符串‘Jack’对象;
- 执行a = ‘Tom’,解释器创建字符串‘Tom’对象,并把a改为指向‘Tom’对象,与b无关。
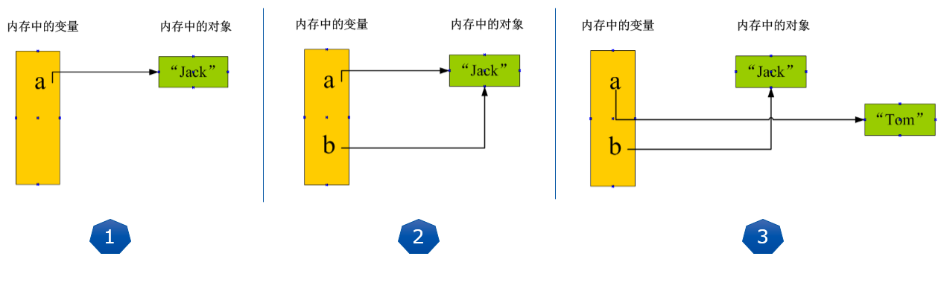
6. 简单介绍常量
说完变量,还要说下常量。
常量就是不变的变量,比如常用的数学常数圆周率就是一个常量。在Python中,通常用全部大写的变量名表示常量:
1 | |
但事实上,从Python语法角度看,PI仍然是一个变量,因为Python根本没有任何机制保证PI不会被改变。你完全可以给PI赋值为10,不会弹出任何错误。所以,用全部大写的变量名表示常量只是一个习惯上的用法。
常量通常放置在代码的最上部,并作为全局使用。
2.2 【基础】字符串类型
1. 如何定义字符串?
字符串是Python中最常用的数据类型之一。
使用单引号或双引号来创建字符串,使用三引号创建多行字符串。字符串要么使用两个单引号,要么两个双引号,不能一单一双!Python不支持单字符类型,单字符在Python中也是作为一个字符串使用。
以下四种写法是等价的
1 | |
如果一个字符串里,要有引号,那么最好和外部包裹的引号类型不同,比如
- 外层使用单引号,那么里层使用双引号
1 | |
- 外层使用双引号,那么里层使用单引号
1 | |
若想使用一样的符号呢?那字符串里的引号前记得加转义符号:\
1 | |
2. 常用的方法
字符串对象本身自带了许多非常实用的方法,考虑到新手的接受程序,在这里也没必要一一给你介绍。
本篇文章只会为你介绍最常用的那些方法,而剩下的你只要在需要的时候去过一下文档就 OK了。
去除首尾空格
1 | |
判断字符串是否以某字符串开头
1 | |
判断字符串是否以某字符串结尾
1 | |
格式化字符串:格式化字符串非常重要,在后面的章节中我有非常详细的讲解,这里你简单了解即可
1 | |
分割字符串:以逗号为分割符分割字符串
1 | |
表示数字的时候,有时我们还会用八进制或十六进制来表示:
十六进制:用0x前缀和0-9,a-f表示,例如:0xff00,0xa5b4c3d2。
八进制:用0o前缀和0-7表示,例如0o12
1 | |
2. 浮点数(Float)
浮点数也就是小数,如1.23,3.14,-9.01,等等。
1 | |
之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1.23x10^9和12.3x10^8是完全相等的。浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。
1 | |
3. 复数(Complex)
复数由实数部分和虚数部分构成,可以用a + bj,或者 complex(a,b) 表示,复数的实部a和虚部b都是浮点型。关于复数,不做科学计算或其它特殊需要,通常很难遇到,这里不做过多解释。
1 | |
4. 常用方法
两数运算
两数相加减
1 | |
两数相乘除
1 | |
取模取余
1 | |
计算绝对值
1 | |
数值直接取整
1 | |
数值四舍五入
1 | |
2.4 【基础】布尔值:真与假
1. 什么是布尔值
但在Python语言中,布尔类型只有两个值
True:表示真值False:表示假值
请注意,首字母要大写,不能是其它花式变型。
所有的计算结果,判断表达式调用返回值是True或者False的过程都可以称为布尔运算,例如比较运算。
布尔值通常用来判断条件是否成立。
1 | |
在 Python Shell 的模式下,很容易看出表达式返回的是真值还是假值。
1 | |
2. 布尔类型的转换
Python内置的 bool() 函数可以用来测试一个表达式的布尔值结果。
1 | |
看完上面的例子,可以总结出
下面这些值经过 bool 转换后是假值:
- 0、0.0、-0.0
- None:这个后面会讲到
- 空字符串、空列表、空元组、空字典
而这些会转换成真值
- -1、1或者其他非0数值
- 所有非空字符串,包括
"False" - 所有非空字典、非空列表、非空集合,非空元组
3. 布尔运算
布尔类型可以进行 and、or和 not运算。
and 运算是与运算,只有所有都为True,and运算的结果才是True:
1 | |
or运算是或运算,只要其中有一个为True,or运算结果就是True:
1 | |
not运算是非运算,它是单目运算符,把True变成False,False变成True:
1 | |
再开下脑洞,布尔类型还能做别的运算吗?试试就知道了!
1 | |
真的可以!比较运算,四则运算都没有问题。并且在做四则运算的时候,明显把True看做1,False看做0。往往是我们不知道的细节,有时候给我们带来巨大的困扰和疑惑。更多的运算种类支持,请大家自行测试。
4. 空值:None
空值不是布尔类型,严格的来说放在这里是不合适的,只不过和布尔关系比较紧密。
空值是Python里一个特殊的值,用None表示(首字母大写)。None不能理解为 0,因为0是整数类型,而None是一个特殊的值。
None也不是布尔类型,而是NoneType。
1 | |
2.5 【基础】学会输入与输出
无论是从我们一开始的“hello world”,还是前面章节的里各种例子,基本都是些“自说自话”,展示类的代码片段。只有能够接收用户输入,根据输入动态生成结果,并输出到屏幕上展示出来,才算一个较为完整,起码是有那么点乐趣或者说成就的简单程序。
1. input 输入函数
input函数:获取用户输入,保存成一个字符串。重要的话,说两遍,input函数的返回值是一个字符串类型。哪怕你输入的是个数字1,返回给你的只会是字符串“1”,而不是 整数1。下面是一些简单的展示例子:
1 | |
第一个例子中,inp = input("please input your name: "),input函数里可以提供一个字符串,用来给用户进行输入提示。input函数的返回值赋值给inp这个变量后,inp里就保存了用户输入的值。
type() 是Python内置的函数之一,非常有用,用于查看对象的数据类型。例子中的 name 是一个str字符串类型,这验证了我们前面说的话。
如果你想要输入的是数值,那么需要你手动使用 int() 函数转一下类型
1 | |
有时候可能输入两边会多敲入几个空格,这时候可以使用 strip() 函数去除首尾空格
1 | |
有时候用户输入的内容会不符合程序的预期,比如我想要获取年龄,那输入必然是全数字,而不能是其他非数值,这时候就可以使用 isdigit 函数进行判断
1 | |
input函数有时可以巧妙地用于阻塞或暂停程序
1 | |
此时的input函数不会将输入保存下来,只是用作暂停程序动作。
2. print 输入函数
print函数我们其实已经不陌生了,前前后后也用了不少次,多少有点经验,明白点它的用法了。
print函数用于将内容格式化显示在标准输出上,主要指的是屏幕显示器。
print可以接受多个字符串,字符串类型的变量或者可print的对象。每个字符串用逗号“,”隔开,连成一串输出。print会依次打印每个字符串,同时,每遇到一个逗号“,”就输出一个空格。
1 | |
对于形如print(a+"a"+b)的语句,其实是先计算a+"a"+b的值,然后再通过print打印它。print()会自动执行内部的语句,输出想要的结果。再看一个例子:
1 | |
我们看一下print函数的原型:print(self, *args, sep=' ', end='\n', file=None)
sep参数: 分隔的符号,默认是一个空格;
end参数: 打印后的结束方式,默认为换行符\n。如果,设置end='',则可以不换行,让print在一行内连续打印。活用print的参数,可以实现灵活的打印控制。
1 | |
2.6 【基础】字符串格式化
格式化输出,主要有三种方式
- 使用 % 进行格式化
- 使用 format 函数进行格式化
- 使用 f-string 进行格式化
由于这三种格式化的内容都非常的多,这里仅为了你看本教程后面的内容,我只介绍最常用的几种
第一种方法:使用 %
%s 表示这个位置接的是一个字符串变量
%d 表示这个位置接的是一个整型变量
前面有多少个 %,后面就要有多少个变量,一一对应,多个变量要括号括起来
1 | |
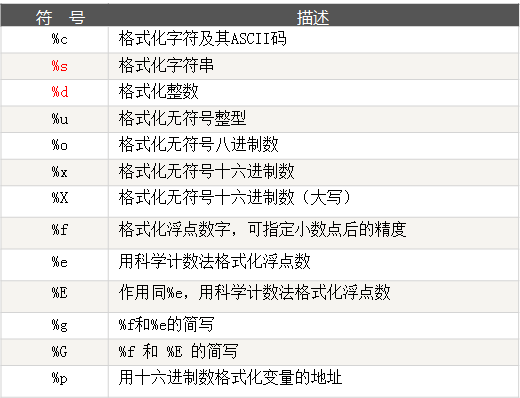
更多的格式化式符号,可以参考这张表
第二种方法:使用 format
在字符串中,使用 {} 进行占位,然后在字符串后跟上 .format() 函数,这个函数的参数就是我们要往字符串中填充的变量。
format 函数会依次填充,比如第一个 {} 会取到第一个参数 name,第二个 {} 会取到第二个参数 age
1 | |
然后如果变量值比较多的话,这样往往会看错乱掉。你可以改成使用索引
1 | |
甚至还可以直接用变量名进行替代
1 | |
更多 format 函数的用法,可详读我另一篇文章:Python强大的格式化format
第三种方法:使用 f-string
这种方法是 Python 3.6 才支持的写法,只要你在字符串前面加一个 f,开启 f-string ,就可以在字符中写入变量。
直接看案例了
1 | |
2.6 【基础】运算符(超全整理)
0. 什么是运算符?
本章节主要说明Python的运算符。举个简单的例子 4 +5 = 9 。 例子中,4和5被称为操作数,”+”号为运算符。
Python语言支持以下类型的运算符:
- 算术运算符
- 比较(关系)运算符
- 赋值运算符
- 逻辑运算符
- 位运算符
- 成员运算符
- 身份运算符
- 运算符优先级
接下来让我们一个个来学习Python的运算符。
1. Python算术运算符
以下假设变量a为10,变量b为20:
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 30 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -10 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 200 |
| / | 除 - x除以y | b / a 输出结果 2 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 0 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的20次方, 输出结果 100000000000000000000 |
| // | 取整除 - 返回商的整数部分 | 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 |
以下实例演示了Python所有算术运算符的操作
两数相加减
1 | |
两数相乘除
1 | |
取模取余
1 | |
2. Python比较运算符
以下假设变量a为10,变量b为20:
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False。 |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 true. |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False。 |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。注意,这些变量名的大写。 | (a < b) 返回 true。 |
| >= | 大于等于 - 返回x是否大于等于y。 | (a >= b) 返回 False。 |
| <= | 小于等于 - 返回x是否小于等于y。 | (a <= b) 返回 true。 |
以下实例演示了Python所有比较运算符的操作:
判断两数是否相等
1 | |
判断 a 是否大于 b
1 | |
3. Python赋值运算符
以下假设变量a为10,变量b为20:
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
以下实例演示了Python所有赋值运算符的操作:
这里只以加减为例,其它的同理
1 | |
4. Python位运算符
按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下:
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011, 在一个有符号二进制数的补码形式。 |
| << | 左移动运算符 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
以下实例演示了Python所有位运算符的操作:
与运算
1 | |
或运算
1 | |
异或运算
1 | |
取反运算
1 | |
左移动运算符
1 | |
右移动运算符
1 | |
5. Python逻辑运算符
Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔”与” - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔”或” - 如果 x 是非 0,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔”非” - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
以上实例输出结果:
and:必须都为True,才能返回True,否则返回False
1 | |
or:只要有一个为True,就返回True,其他返回False
1 | |
not:与原值取反
1 | |
6. Python成员运算符
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回True,否则返回False。 | x 在 y序列中 , 如果x在y序列中返回True。 |
| not in | 如果在指定的序列中没有找到值返回True,否则返回False。 | x 不在 y序列中 , 如果x不在y序列中返回True。 |
以下实例演示了Python所有成员运算符的操作:
1 | |
7. Python身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is是判断两个标识符是不是引用自一个对象 | x is y, 如果 id(x) 等于 id(y) , is 返回结果 1 |
| is not | is not是判断两个标识符是不是引用自不同对象 | x is not y, 如果 id(x) 不等于 id(y). is not 返回结果 1 |
以下实例演示了Python所有身份运算符的操作:
1 | |
8. Python运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 ‘AND’ |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not or and | 逻辑运算符 |
以下实例演示了Python运算符优先级的操作:
1 | |
计算顺序是
- 30*2 = 60
- 60/5 = 12.0
- 20 + 12.0 = 32.0
第三章:数据结构
3.1 【基础】列表
列表(英文名 list),是由一系列元素按顺序进行排列而成的容器。
这里面有两个重点:
- 元素:没有要求同一类型,所以可以是任意类型。
- 顺序:按顺序排列而成,说明列表是有序的。
在接下来的例子中,我会向你演示,列表的一些特性和常用的方法。
1. 创建列表
创建列表有两种方法
第一种方法:先创建空列表实例,再往实例中添加元素
1 | |
第二种方法:直接定义列表,并填充元素。
1 | |
很明显,第二种最简单直接,容易理解。并且经过测试,第二种的效率也比第一种的要高。因此推荐新手使用第二种。
2. 增删改查
增删改查:是 新增元素、删除元素、修改元素、查看元素的简写。
由于,内容比较简单,让我们直接看演示
查看元素
使用 [i] 的方式查看第 i+1 个元素。例如 x 的起始值为 0 ,代表第一个元素。
1 | |
使用 index 方法,查看第一个值为 x 的索引。
1 | |
使用 count 方法,查看该列表中有几个值为 x
1 | |
使用内置函数 len(),可以查看该列表中有几个值
1 | |
新增元素
使用列表的 append 、insert、和 extend 方法
- append 方法:将元素插入在列表的最后一个位置
1 | |
- insert 方法:将元素插入在列表的指定的位置
1 | |
- extend:将一个新的列表直接连接在旧的列表后面
1 | |
修改元素
直接使用 list[x]=new_item 的方法直接替换
1 | |
删除元素
使用 pop ,remove 、clear 方法或者 del 语句删除元素
- pop 方法:删除指定位置的元素。默认删除最后一个元素,并返回
1 | |
- remove:删除第一个值为 x 的元素。
1 | |
- clear 方法:把所有的元素清空
1 | |
- del 语句:清空列表,还有另一种方法
1 | |
使用 del 语句,还可以删除某一个或者某几个连续的元素。
1 | |
3. 列表反转
列表反转有两种方法
第一种方法:使用自带的 reverse 方法
1 | |
第二种方法:使用切片的方法
1 | |
这两种方法,区别在于:
- reverse 方法是原地反转,作用在原对象上
- 切片反转是返回一个新对象,原对象不改变
4. 列表排序
列表的排序同样有两种方法:
第一种方法:列表对象内置了 sort 方法,可方便我们对元素进行排序。
1 | |
第二种方法:Python 有个内置的 sorted 函数,它不仅可用作列表的排序,后面我们还会学到 字典 等其他数据结构的排序也会用到它。
1 | |
不管用哪种方法,都要保证列表内的元素俩俩是可比较的。
比如,数值和数值是可比较的,字符串和字符串之间是可比较的。
但是数值和字符串是不可比较的,示例如下
1 | |
除了上面介绍的俩种之外,其实利用 sort 函数还可以实现自定义排序,这部分内容对于新手来说学习起来稍有点难度,且用到的场景也不多,因此这边我就不介绍啦。
3.2 【基础】元组
元组(英文名 tuple),和列表非常的相似,它也是由一系列元素按顺序进行排列而成的容器。
不同的是,元组是不可变的,而列表是可变的。
1. 创建元组
创建元组有三种方法
第一种方法:直接使用 圆括号 将所有的元素进行包围。这有别于创建列表时使用的是中括号:[]
1 | |
第二种方法:有时候,创建元组时,圆括号可有可无的。
1 | |
第三种方法:使用元组推导式,由于元组是不可变的,所以生成一个生成器对象。这一种对于新手来说可能会比较难以理解,我会放在后面专门进行讲解,这里先作了解,新手可直接跳过。
1 | |
上面三种方法介绍完毕~
你以为就这么简单?
当你在创建只有一个元素的元组时,你有可能会这样子创建
1 | |
却发现,创建出来的并不是 tuple,而是一个 int 对象。
此时千万要记住,当你创建只包含一个元素的元组时,要在第一个元素后面加一个逗号
1 | |
另外,创建空元组可以这样
1 | |
2. 增删改查
最前面我们说过,元组是不可变的。因此,你想对元组进行修改的行为都是不被允许的。
呐,看一下示例,查看元素可以,但是修改元素和删除元素都报错了。
1 | |
新增元素呢?当然同样也是不支持的,这里不再演示。
3. 元组与列表的转换
虽然元组可能看起来与列表很像,但它们通常是在不同的场景被使用,并且有着不同的用途。
元组是 immutable (不可变的),其序列通常包含不同种类的元素,并且通过解包或者索引来访问(如果是 namedtuples 的话甚至还可以通过属性访问)。
列表是 mutable (可变的),并且列表中的元素一般是同种类型的,并且通过迭代访问。
那有办法可以实现二者的转换吗?
当然有,而且非常简单。
将元组转成列表
1 | |
将列表转成元组
1 | |
3.3 【基础】字典
字典(英文名 dict),它是由一系列的键值(key-value)对组合而成的数据结构。
字典中的每个键都与一个值相关联,其中
- 键,必须是可 hash 的值,如字符串,数值等
- 值,则可以是任意对象
1. 创建字典
创建一个字典有三种方法
第一种方法:先使用 dict() 创建空字典实例,再往实例中添加元素
1 | |
第二种方法:直接使用 {} 定义字典,并填充元素。
1 | |
第三种方法:使用 dict() 构造函数可以直接从键值对序列里创建字典。
1 | |
第四种方法:使用字典推导式,这一种对于新手来说可能会比较难以理解,我会放在后面专门进行讲解,这里先作了解,新手可直接跳过。
1 | |
2. 增删改查
增删改查:是 新增元素、删除元素、修改元素、查看元素的简写。
由于,内容比较简单,让我们直接看演示
查看元素
查看或者访问元素,直接使用 dict[key] 的方式就可以
1 | |
但这种方法,在 key 不存在时会报 KeyValue 的异常
1 | |
所以更好的查看获取值的方法是使用 get() 函数,当不存在 gender 的key时,默认返回 male
1 | |
新增元素
新增元素,直接使用 dict[key] = value 就可以
1 | |
修改元素
修改元素,直接使用 dict[key] = new_value 就可以
1 | |
删除元素
删除元素,有三种方法
第一种方法:使用 pop 函数
1 | |
第二种方法:使用 del 函数
1 | |
3. 重要方法
判断key是否存在
在 Python 2 中的字典对象有一个 has_key 函数,可以用来判断一个 key 是否在该字典中
1 | |
但是这个方法在 Python 3 中已经取消了,原因是有一种更简单直观的方法,那就是使用 in 和 not in 来判断。
1 | |
设置默认值
要给某个 key 设置默认值,最简单的方法
1 | |
实际上有个更简单的方法
1 | |
3.4 【基础】集合
集合(英文名 set),它是一个无序的不重复元素序列。
这里面有两个重点:
- 无序,
- 不重复
1. 创建集合
集合的创建有两种方法
第一种方法:使用 花括号 {} 直接创建,创建的时候,{} 可以包含有重要的元素,但是创建完后,集合会去重,只留第一个。
1 | |
第二种方法:使用 set() 方法进行创建,当 set() 函数不接任何参数时,创建的是空集合,如果不创建空集合,可以传入一个列表。
1 | |
2. 增删改查
增加元素
使用 add 函数可以往集合中传入函数
1 | |
另外,还可以使用 update 函数,来往集合中添加元素,update 函数后可接集合,列表,元组,字典等。
这是接集合的例子
1 | |
删除元素
使用 remove 函数可以删除集合中的元素
1 | |
使用 remove 函数,如果对应的元素不存在,是会报错的。
1 | |
对于这种情况,你可以使用 discard 函数,存在元素则移除,不存在也不会报错。
1 | |
此外,还有一个 pop 函数,用于从集合中随机删除元素,和列表、字典的 pop 不一样,这里的 pop 不能加任何的参数。
1 | |
最后,还要介绍一个 clear 函数,它用于清空集合的元素。
1 | |
修改元素
文章开头处,已经说明了集合是 无序 的,因此集合是没有索引的。
既然没有索引,修改也无从谈起。
记住:集合只有添加元素、删除元素。
查询元素
同上,没有顺序,也就没有索引,没有索引,查询也无从谈起。
但是我们可以查看集合的其他内容
比如,查看集合的长度
1 | |
3. 集合运算
求合集
将两个集合进行合并并去重,可以使用 union 函数,下面的示例中,由于 Huawei 是重复的元素,只会保留一个。
1 | |
另外还可以使用 | 的操作符
1 | |
求差集
要找出存在集合 A 但是不存在 集合 B 的元素,就是对两个集合求差集。
可以使用 difference 函数,下面的示例中, Apple 在 aset 中存在,但在 bset 中不存在。
1 | |
另外还可以使用 - 的操作符,更加直观
1 | |
求交集
要找出存在集合 A 并且存在集合 B 的元素,就是对两个集合求交集。
可以使用 intersection 函数
1 | |
和 intersection 相似的还有一个 intersection_update 函数,它们的区别是,intersection_update 会原地更新在 aset 上,而不是会回交集。
1 | |
另外还可以使用 & 的操作符
1 | |
求不重合集
如果计算两个集合中不重复的元素集合,可以使用 symmetric_difference 函数
1 | |
和 symmetric_difference 相似的还有一个 symmetric_difference_update 函数,它们的区别是,symmetric_difference_update 会原地更新在 aset 上,而不是直接返回。
1 | |
4. 集合判断
判断是否有某元素
1 | |
判断两集合是否有相同元素
如果两集合有相同元素,则返回 False,如果没有相同元素,则返回 True
1 | |
判断是否是子集
1 | |
2. 是否可迭代?
对 Python 比较熟悉的朋友,肯定知道哪些数据类型是可迭代的,哪些是不可迭代的。
但是对新手来说,可能需要借助一些函数来判别,比如 Python 内置的 collections.abc 模块,这个模块只有在 Python 中才有噢,在这个模块中提供了一个 Iterable 类,可以用 isinstance 来判断。
1 | |
但是这种方法并不是百分百准确(具体下面会说到),最准确的方法,还是应该使用 for 循环。
3. 可迭代协议
可迭代对象内部是如何实现在你对其进行 for 循环时,可以一个一个元素的返回出来呢?
这就要谈到迭代器协议。
第一种场景:如果一个对象内部实现了 __iter__() 方法 ,并返回一个迭代器实例,那么该对象就是可迭代对象
1 | |
第二种场景:假设一个对象没有实现 __iter__() ,Python 解释器 __getitem__() 方法获取元素,如果可行,那么该对象也是一个可迭代对象。
1 | |
此时如果你使用 isinstance(my_list, Iterable) 去判断是否是可迭代,就会返回 False,因为 isinstance 这种方法就是检查对象是否有 __iter__ 方法。这也论证了使用 isinstance(my_list, Iterable) 去判断是否可迭代是不准确的。
4. 什么是迭代器
当你对一个可迭代对象使用 iter 函数后,它会返回一个迭代器对象,对于迭代器对象,我们可以使用 next 函数,去获取元素,每执行一次,获取一次,等到全部获取完毕,会抛出 StopIteration 提示无元素可取。
1 | |
5. 迭代器协议
对比可迭代对象,迭代器的内部只是多了一个函数而已 – __next__()
正因为有了它,我们才可以用 next 来获取元素。
迭代器,是在可迭代的基础上实现的。要创建一个迭代器,我们首先,得有一个可迭代对象。
现在就来看看,如何创建一个可迭代对象,并以可迭代对象为基础创建一个迭代器。
1 | |
3.6 【基础】生成器
1. 什么是生成器?
生成器(英文名 Generator ),是一个可以像迭代器那样使用for循环来获取元素的函数。
生成器的出现(Python 2.2 +),实现了延时计算,从而缓解了在大量数据下内存消耗过猛的问题。
当你在 Python Shell 中敲入一个生成器对象,会直接输出 generator object 提示你这是一个生成器对象
1 | |
2. 如何创建生成器?
使用列表推导式
在上面已经演示过,正常我们使用列表推导式时是下面这样子,使用 [] ,此时生成的是列表。
1 | |
而当你把 [] 换成 () ,返回的就不是列表了,而是一个生成器
1 | |
使用 yield
yield 是什么东西呢? 它相当于我们函数里的 return,但与 return 又有所不同。
- 当一个函数运行到 yield 后,函数的运行会暂停,并且会把 yield 后的值返回出去。
- 若 yield 没有接任何值,则返回 None
- yield 虽然返回了,但是函数并没有结束
请看如下代码,我定义了一个 generator_factory 函数,当我执行 gen = generator_factory() 时,gen 就是一个生成器对象
1 | |
3. 生成器的使用
从一个生成器对象中取出元素,和我们前面学过的通过切片访问列表中的元素不一样,它没有那么直观。
想要从生成器对象中取出元素,只有两种方法:
第一种方法:使用 next 方法一个一个地把元素取出来,如果元素全部取完了,生成器会抛出 StopIteration 的异常。
1 | |
第二种方法:使用 for 循环一个一个地迭代出来
1 | |
4. 生成器的激活
生成器对象,在创建后,并不会执行任何的代码逻辑。
想要从生成器对象中获取元素,那么第一步要触发其运行,在这里称之为激活。
方法有两种:
- 使用
next():上面已经讲过 - 使用
generator.send(None)
还以下面这段代码为例,可以看到 gen.send(None) 相当于执行了 next(gen)
1 | |
5. 生成器的状态
生成器在其生命周期中,会有如下四个状态
GEN_CREATED# 生成器已创建,还未被激活GEN_RUNNING# 解释器正在执行(只有在多线程应用中才能看到这个状态)GEN_SUSPENDED# 在 yield 表达式处暂停GEN_CLOSED# 生成器执行结束
通过下面的示例可以很轻松地理解这一过程(GEN_RUNNING 这个状态只有在多线程中才能观察到,这里就不演示啦)
1 | |
6. 生成器的异常
在最前面,我有定义了一个生成器函数。
1 | |
在没有元素可返回时,我最后抛出了 StopIteration 异常,这是为了满足生成器的协议。
实际上,如果你不手动抛出 StopIteration,在生成器遇到函数 return 时,会我自动抛出 StopIteration。
请看下面代码,我将 raise StopIteration 去掉后,仍然会抛出异常。
1 | |
第四章:控制流程
4.1 【基础】条件语句:if
1. 简单小例子
如果满足条件 A,则执行代码块 a,否则执行代码块 b。类似这样的控制流程语句,称之为条件语句。
它的基本形式是
1 | |
举个最简单的例子
1 | |
2. 多条件语句
如果需要多次判断可以利用 elif,它的基本形式是
1 | |
举个最简单的例子
1 | |
3. 判断的条件
在 Python 中,值可以分为
假值:None、空列表、空集合、空字典,空元组、空字符串、0、False 等真值:非空列表、非空集合、非空字典,非空元组、非空字符串、非 0 数值、True 等
if 和 elif 后面可以接一个表达式(上面已经举例过),也可以接一个对象。
只要这个对象是真假,代码就会进入相应分支,如果为对象为假值,则继续下一判断。
这边随便以 0 和 1 举例
1 | |
4. 多个条件组合
在讲多个条件组合时,先来了解一下 Python 中的逻辑运算符。
以下假设变量 a 为 10, b为 20:
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔”与” - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔”或” - 如果 x 是非 0,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔”非” - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
学习完逻辑运算符,就可以开始写多条件语句
- 如果一个 if 条件需要同时满足多个条件,那么可以使用
and或者& - 如果一个 if 条件只需要满足多个条件的其中一个,那么可以使用
or或者| - 如果一个 if 要求不满足某个条件,那么可以使用
not或者!
1 | |
4.2 【基础】循环语句:for
for 循环可以遍历任何序列的项目,如一个列表或者一个字符串。
它的基本语法是
1 | |
1. 普通循环
直接上案例
1 | |
2. 带索引循环
如果想在循环的时候,把索引也取出来,可以加一个 enumerate 函数
1 | |
3. break 中断
正常情况下,我们都需要 for 循环能够全部循环完,但在某些情况下,需要中断循环的执行,中断循环使用的是 break 关键字。
举个例子
1 | |
4. continue 下一循环
在有些循环中,不需要把 for 的循环体内的代码全部执行完毕,这种情况下,可以使用 continue 关键字,直接进入下一循环。
举个例子,下面的循环中当 i 等于 1 时,就直接跳过了循环。
1 | |
5. for - else 循环
其实在 for 循环语句的后面,可以加一个 else 分支,当代码在 for 循环体中正常执行完,自然就会走到 else 分支中。
那么什么叫做 正常执行完 呢?就是只要不通过 break 语句中断的,都算正常执行完。
先以 continue 为例,所有的循环都非常正常,会走到 else 分支
1 | |
再把 continue 改成 break 后,发现不会走到 else 分支
1 | |
4.3 【基础】循环语句:while
while 语句用于循环执行程序,即在某条件下,循环执行某段程序,以处理需要重复处理的相同任务。
其基本形式为:
1 | |
1. 普通的循环
直接上案例
1 | |
运行后,输出结果
1 | |
2. 无限的循环
当 while 后面的条件一直满足且循环体内一直没有 break ,此时 while 就会变成死循环,就是写 while 循环时千万要注意的。
会造成死循环,无非两种情况:
1、 使用 while True,而且循环体内又没有 break 或者 走不到 break
1 | |
2、 使用一个永远都会成立的判断条件,而且循环体内又没有 break 或者 走不到 break
1 | |
3. while - else 语句
和 for 循环一样, while 循环同样可以加一个 else 分支,当代码在 while 循环体中正常执行完,就会走到 else 分支中。
那么什么叫做 正常执行完 呢?就是只要不通过 break 语句中断的,都算正常执行完。
1 | |
如果在循环体内加 break ,就算是异常退出
1 | |
举个例子。
我想找出一个数值列表中为偶数的元素,并组成新列表,通常不用列表推导式,可以这么写
1 | |
一个简单的功能,写的代码倒是不少。
如果使用了列表推导式,那就简洁多了,而且代码还变得更加易读了。
1 | |
2. 字典推导式
字典推导式的基本格式,和 列表推导式相似,只是把 [] 改成了 {},并且组成元素有两个:key 和 value,要用 key_expr: value_expr 表示。
1 | |
举个例子。
我想从一个包含所有学生成绩信息的字典中,找出数学考满分的同学。
1 | |
3. 集合推导式
集合推导式跟列表推导式也是类似的。 唯一的区别在于它使用大括号{},组成元素也只要一个。
基本格式
1 | |
举个例子
我想把一个数值列表里的数进行去重处理
1 | |
4. 生成器推导式
生成器推导式跟列表推导式,非常的像,只是把 [] 换成了 ()
- 列表推导式:生成的是新的列表
- 生成器推导式:生成的是一个生成器
直接上案例了,找出一个数值列表中所有的偶数
1 | |
5. 嵌套推导式
for 循环可以有两层,甚至更多层,同样的,上面所有的推导式,其实都可以写成嵌套的多层推导式。
但建议最多嵌套两层,最多的话,代码就会变得非常难以理解。
举个例子。
我想打印一个乘法表,使用两个for可以这样写
1 | |
输出如下
1 | |
如果使用嵌套的列表推导式,可以这么写
1 | |
第五章:学习函数
5.1 【基础】普通函数创建与调用
函数是一种仅在调用时运行的代码块。您可以将数据(称为参数)传递到函数中,然后由函数可以把数据作为结果返回。
如果将函数比喻成蛋糕店的话,那么函数的参数就是生产蛋糕的原材料,而函数的返回值就是蛋糕成品。
1. 函数的创建
在 Python 中,使用 def 关键字定义函数
1 | |
举个例子,我这边手动实现一个计算两个数平均值的函数,这边这样子写
1 | |
在定义函数的过程中,需要注意以下几点:
- 函数代码块以
def关键词开头,一个空格之后接函数标识符名称和圆括号(),再接个冒号。 - 任何传入的参数必须放在圆括号中间。
- 函数的第一行语句后可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- 使用return,返回值给调用者,并结束函数。return 关键并不是必须要加,可根据实际需要决定是否要写,若不写的话,默认返回None。
- return语句依然在函数体内部,不能回退缩进。直到函数的所有代码写完,才回退缩进,表示函数体结束。
2. 函数的调用
函数编写出来就是给人调用的。要调用一个函数,必须使用函数名后跟圆括号的方式才能调用函数。
调用的同时要根据函数的定义体,提供相应个数和类型的参数,每个参数之间用逗号分隔。
1 | |
4. 函数的返回
函数的返回值,可以是多种多样的,非常灵活:
可以是任意类型的对象,比如字符串,数值,列表,字典等等
1
2def demo_func():
return 10可以是一个表达式,函数会直接运行表达式,然后返回
1
2def get_average(a, b):
return (a + b)/2可以是函数本身,利用这点可以实现递归调用。
1
2
3
4def fact(n):
if n==1:
return 1
return n * fact(n - 1)另外还可以返回多个值
1 | |
- 可以是其他函数,利用这点可以实现装饰器。这部分属于进阶内容,感兴趣可查看另一章节内容:5.6 精通装饰器的八种用法
1
2
3
4def decorator(func):
def wrapper(*args, **kw):
return func()
return wrapper
5.2. 【基础】11个案例讲解函数参数
1. 参数分类
函数,在定义的时候,可以有参数的,也可以没有参数。
从函数定义的角度来看,参数可以分为两种:
必选参数:调用函数时必须要指定的参数,在定义时没有等号可选参数:也叫默认参数,调用函数时可以指定也可以不指定,不指定就默认的参数值来。
例如下面的代码中,a 和 b 属于必选参数, c 和 d 属于可选参数
1 | |
从函数调用的角度来看,参数可以分为两种:
关键字参数:调用时,使用 key=value 形式传参的,这样传递参数就可以不按定义顺序来。位置参数:调用时,不使用关键字参数的 key-value 形式传参,这样传参要注意按照函数定义时参数的顺序来。
1 | |
最后还有一种非常特殊的参数,叫做可变参数。
意思是参数个数可变,可以是 0 个或者任意个,但是传参时不能指定参数名,通常使用 *args 和 **kw 来表示:
*args:接收到的所有按照位置参数方式传递进来的参数,是一个元组类型**kw:接收到的所有按照关键字参数方式传递进来的参数,是一个字典类型
1 | |
输出如下
1 | |
2. 十一个案例
案例一:在下面这个函数中, a 是必选参数,是必须要指定的
1 | |
案例二:在下面这个函数中,b 是可选参数(默认参数),可以指定也可以不指定,不指定的话,默认为10
1 | |
案例三:在下面这个函数中, name 和 age 都是必选参数,在调用指定参数时,如果不使用关键字参数方式传参,需要注意顺序
1 | |
如果参数太多,你不想太花精力去注意顺序,可以使用关键字参数方式传参,在指定参数时附上参数名,比如这样:
1 | |
案例四:在下面这个函数中,args 参数和上面的参数名不太一样,在它前面有一个 *,这就表明了它是一个可变参数,可以接收任意个数的不指定参数名的参数。
1 | |
案例五:在下面这个函数中,kw 参数和上面的 *args 还多了一个 * ,总共两个 ** ,这个意思是 kw 是一个可变关键字参数,可以接收任意个数的带参数名的参数。
1 | |
案例六:在定义时,必选参数一定要在可选参数的前面,不然运行时会报错
1 | |
案例七:在定义时,可变位置参数一定要在可变关键字参数前面,不然运行时也会报错
1 | |
案例八:可变位置参数可以放在必选参数前面,但是在调用时,必选参数必须要指定参数名来传入,否则会报错
1 | |
案例九:可变关键字参数则不一样,可变关键字参数一定得放在最后,下面三个示例中,不管关键字参数后面接位置参数,还是默认参数,还是可变参数,都会报错。
1 | |
案例十:将上面的知识点串起来,四种参数类型可以在一个函数中出现,但一定要注意顺序
1 | |
试着调用这个函数,输出如下:
1 | |
案例十一:使用单独的 *,当你在给后面的位置参数传递时,对你传参的方式有严格要求,你在传参时必须要以关键字参数的方式传参数,要写参数名,不然会报错。
1 | |
3. 传参的坑
函数参数传递的是实际对象的内存地址。如果参数是引用类型的数据类型(列表、字典等),在函数内部修改后,就算没有把修改后的值返回回去,外面的值其实也已经发生了变化。
1 | |
5.3 【基础】匿名函数的使用
匿名函数(英语:anonymous function)是指一类无需定义标识符(函数名)的函数。通俗来说呢,就是它可以让我们的函数,可以不需要函数名。
正常情况下,我们定义一个函数,使用的是 def 关键字,而当你学会使用匿名函数后,替代 def 的是 lambda。
这边使用def 和 lambda 分别举个例子,你很快就能理解。
1 | |
从上面的示例,我们可以看到匿名函数直接运行,省下了很多行的代码,有没有?
接下来,我们的仔细看一下它的用法
带 if/else
1 | |
嵌套函数
1 | |
递归函数
1 | |
或者
1 | |
从以上示例来看,lambda 表达式和常规的函数相比,写法比较怪异,可读性相对较差。除了可以直接运行之外,好像并没有其他较为突出的功能,为什么在今天我们要介绍它呢?
首先我们要知道 lambda 是一个表达式,而不是一个语句。正因为这个特点,我们可以在一些特殊的场景中去使用它。具体是什么场景呢?接下来我们会介绍到几个非常好用的内置函数。
5.4 【基础】必学高阶函数
1. map 函数
map 函数,它接收两个参数,第一个参数是一个函数对象(当然也可以是一个lambda表达式),第二个参数是一个序列。
它可以实现怎样的功能呢,我举个例子你就明白了。
1 | |
可以很清楚地看到,它可以将后面序列中的每一个元素做为参数传入lambda中。
当我们不使用 map 函数时,你也许会这样子写。
1 | |
2. filter 函数
filter 函数,和 map 函数相似。同样也是接收两个参数,一个lambda 表达式,一个序列。它会遍历后面序列中每一个元素,并将其做为参数传入lambda表达式中,当表达式返回 True,则元素会被保留下来,当表达式返回 False ,则元素会被丢弃。
下面这个例子,将过滤出一个列表中小于0的元素。
1 | |
3. reduce 函数
reduce 函数,也是类似的。它的作用是先对序列中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 lambda 函数运算,将其得到的结果再与第四个元素进行运算,以此类推下去直到后面没有元素了。
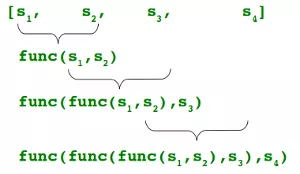
这边举个例子你也就明白了。
1 | |
它的运算过程分解一下是这样的。
1 | |
4. 注意点
以上几个函数,熟练的掌握它们的写法,可以让我们的代码看起来更加的 Pythonic ,在某一程度上代码看起来更加的简洁。
如果你是新手呢,你需要注意的是,以上示例是在 Python2.x 环境下演示的。而在 Python3.x 中,却有所不同,你可以自己尝试一下。
这里总结一下:
第一点,map 和 filter 函数返回的都不再是一个列表,而是一个迭代器对象。这里以map为例
1 | |
第二点,reduce 不可以直接调用,而是要先导入才能使用,
1 | |
5.5 【基础】反射函数的使用
自省,在我们日常生活中,通常是自我反省的意思。
但在计算机编程中,自省并不是这个意思,它的英文单词是 introspection,表示的是自我检查的行为或能力。
它的内容包括
- 告诉别人,我是谁
- 告诉别人,我能做什么
Python 是一门动态语言,有了自省,就能让程序在运行时能够获知对象的类型以及该对象下有哪些方法等。
1. 学习 Python 模块的入口
help()
在 console 模式下,输入 help() ,可以看到输出了一段帮助文档,教你如何使用这个 help,当你看到提示符变成了 help> 时,这时候就进入了 help 模式。
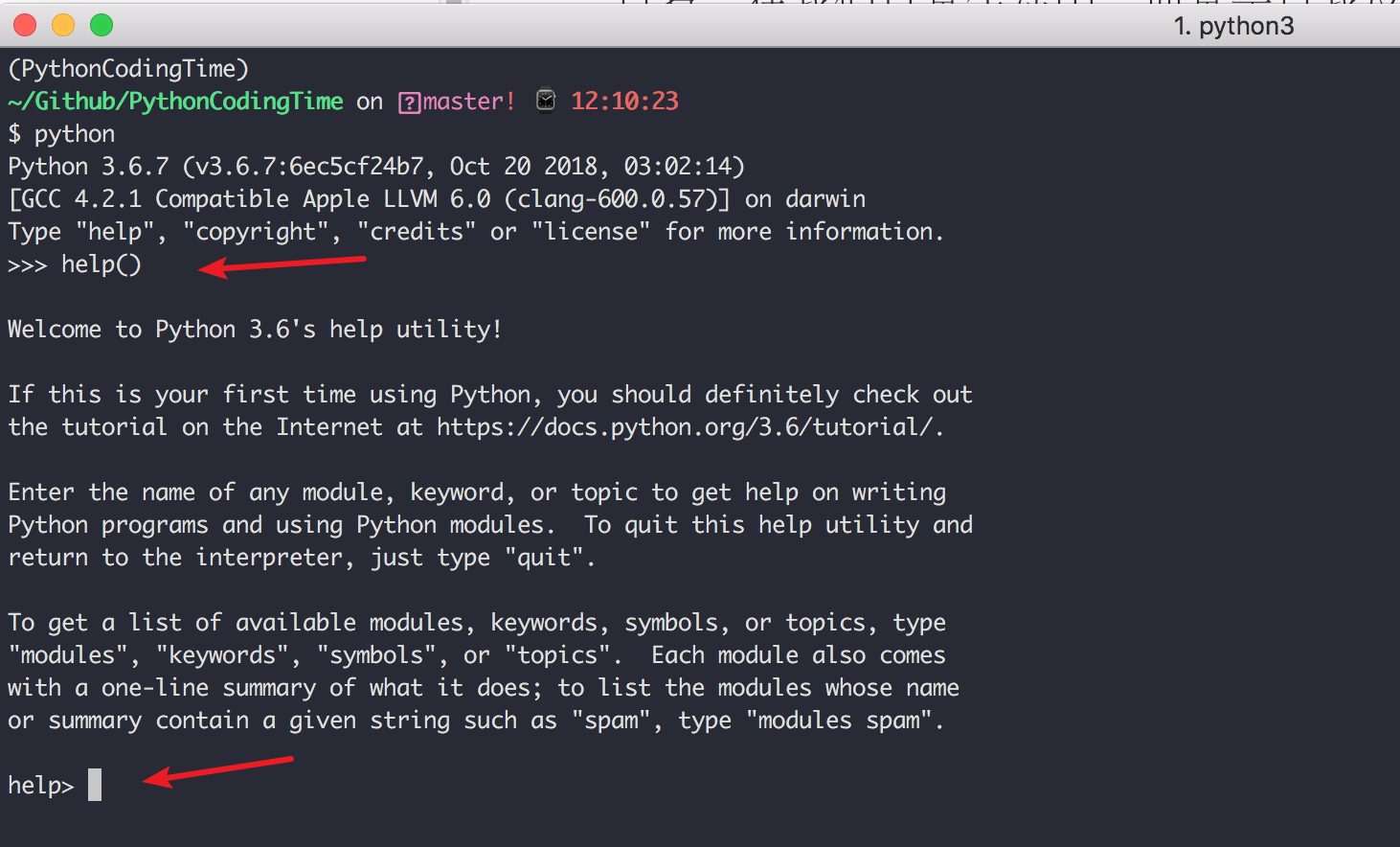
此时你可以键入你想要了解的模块、语法等,help 告诉你如何使用。
比如我输入 keywords ,就可以看到 Python 里所有的关键字。再输入 modules 就可以查看 Python 中所有的内置模块。
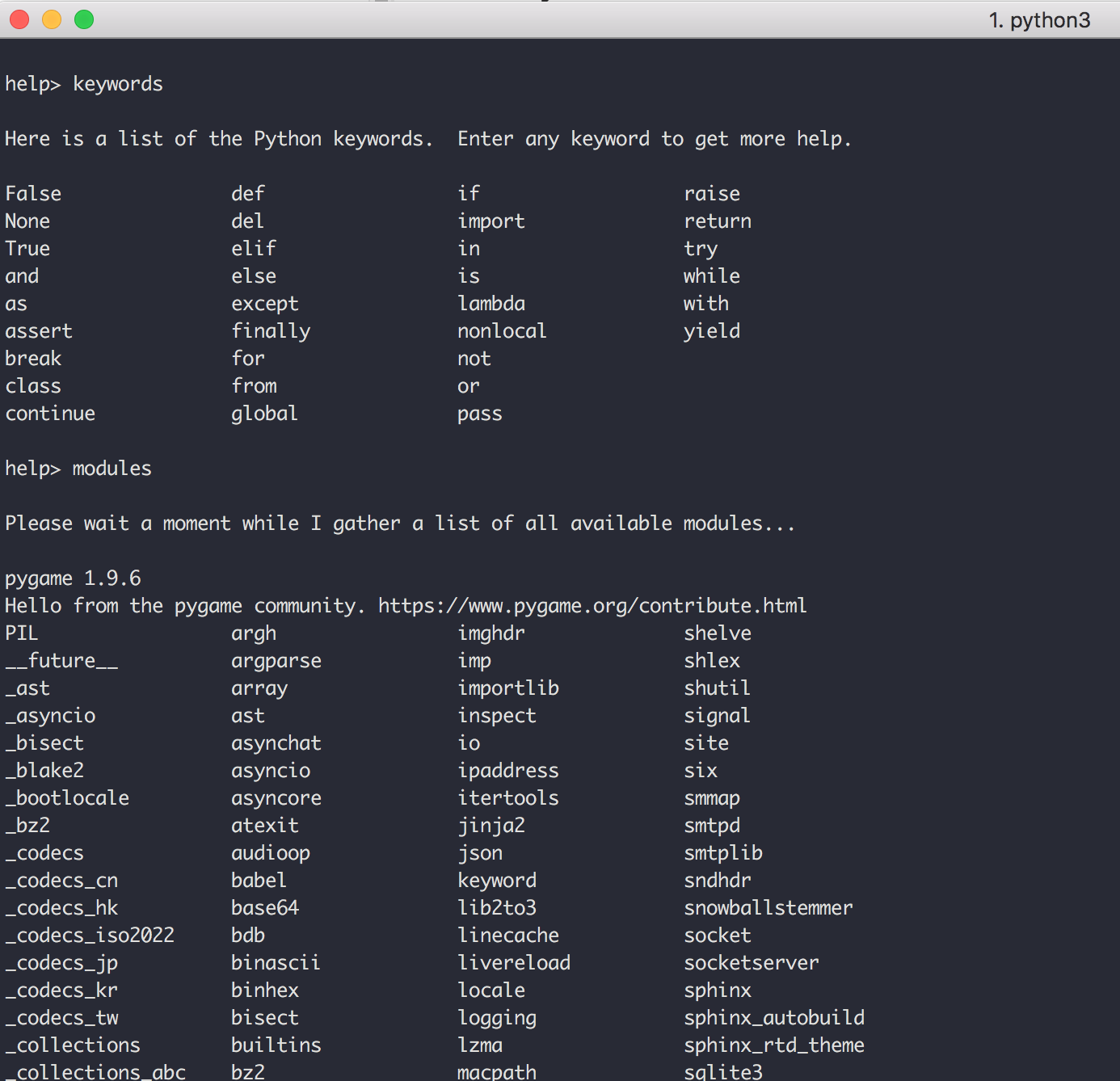
输入 modules + 指定包名,就可以查看这个包下有哪些模块
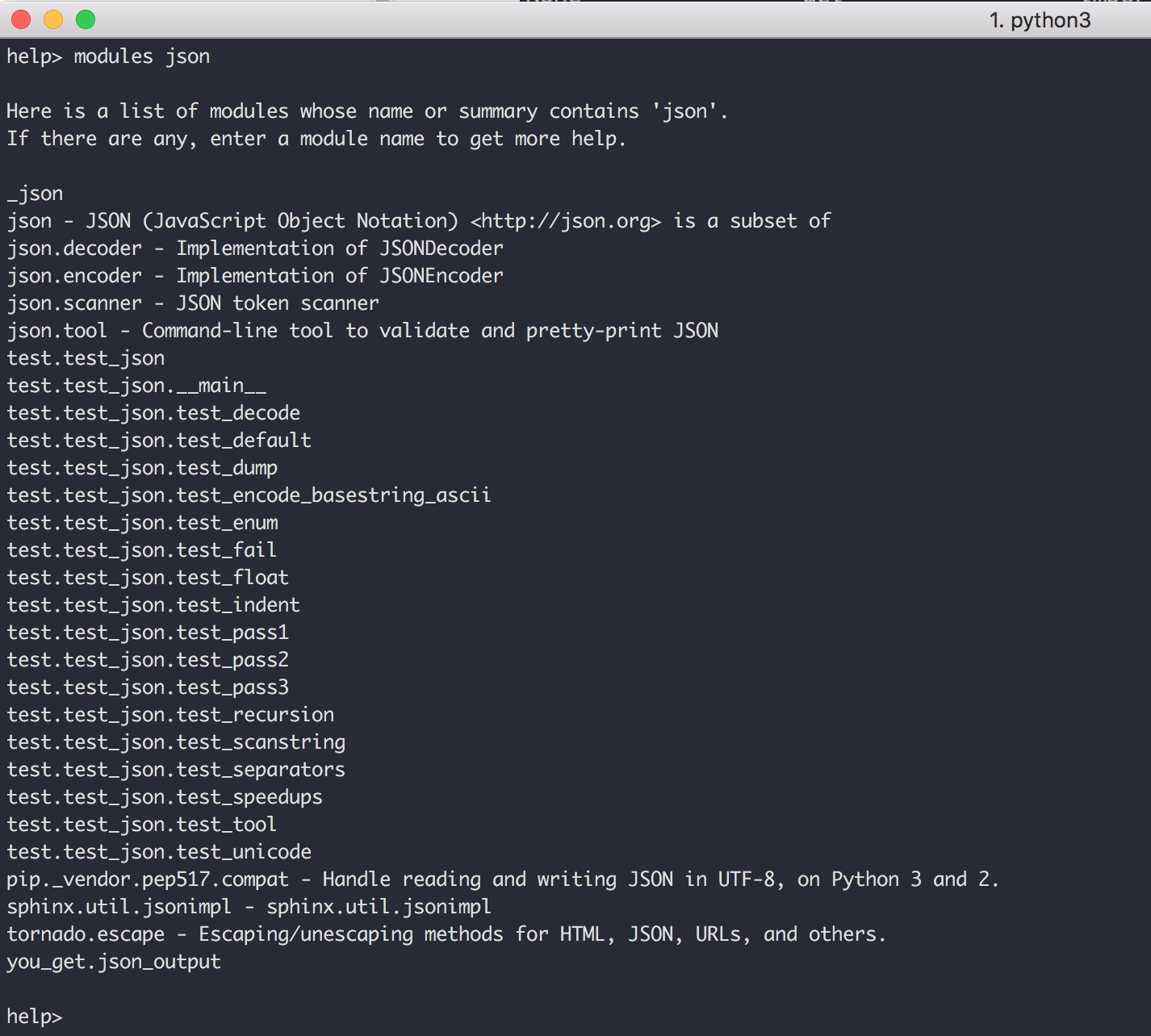
如果你想学习某个包要如何使用,可以直接在 help 模式下输入 包名,就像下面这样,我就可以获得一份 json 的帮助文档。
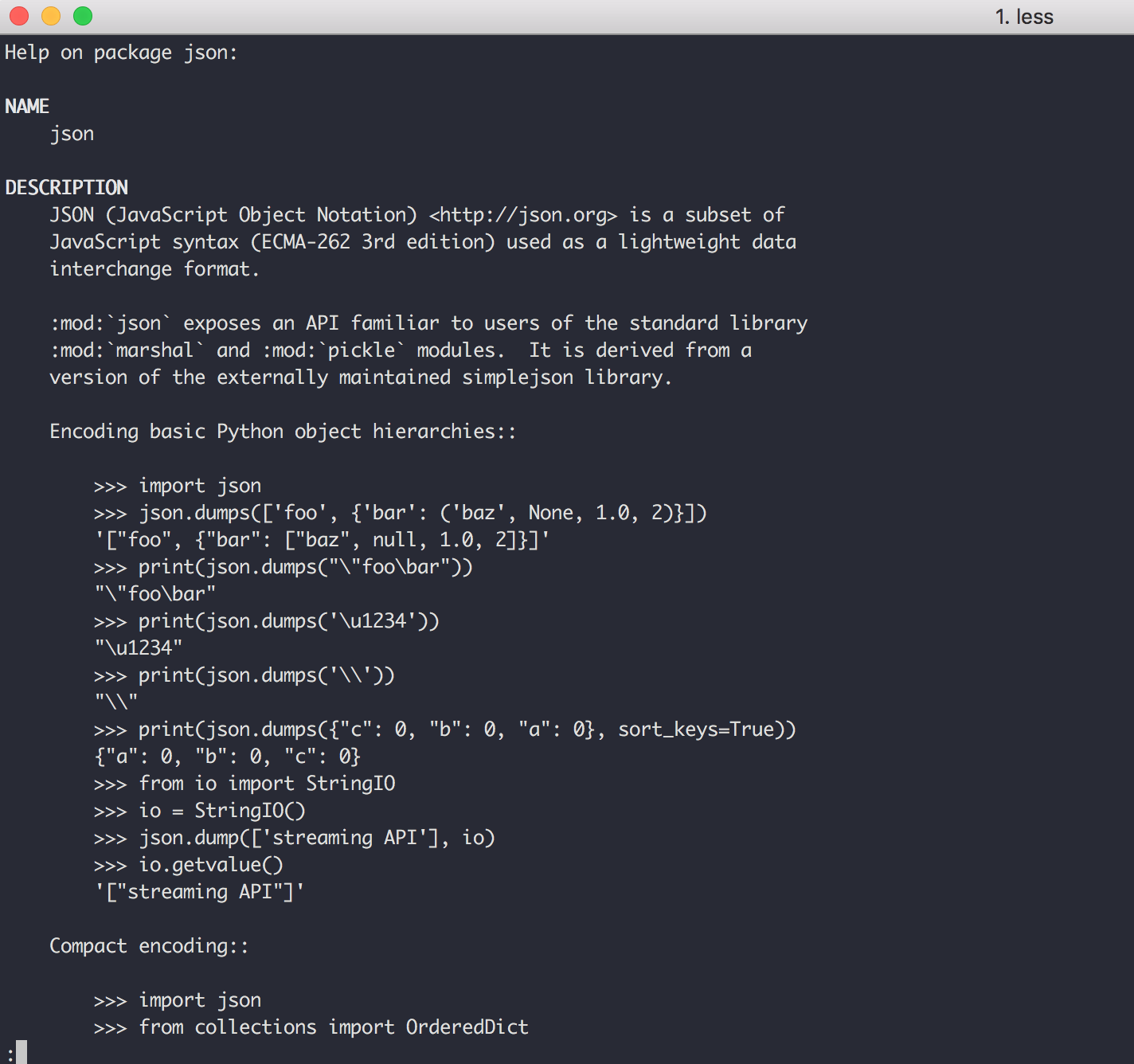
如果你想学习某个关键字的用法,可以在 help 模式下直接键入 关键字 查询用法,比如我直接键入 for 。
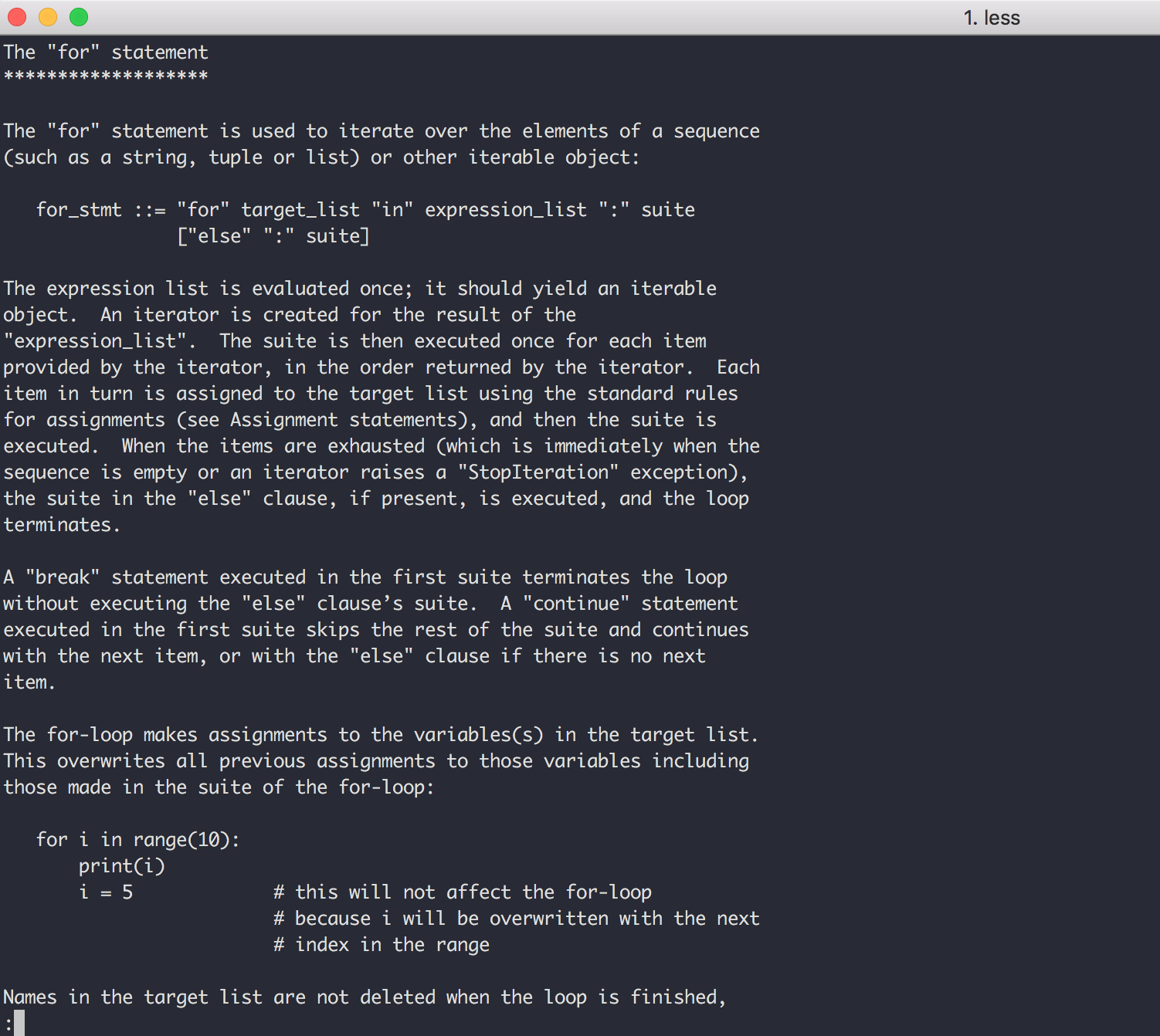
查完后,使用 quit 就可以退出 help 模式了。
如果你觉得进入 help 模式太麻烦,可以在 console 模式下直接查询
1 | |
dir()
dir() 函数可能是 Python 自省机制中最著名的部分了。它返回传递给它的任何对象的属性名称经过排序的列表。如果不指定对象,则 dir() 返回当前作用域中的名称。让我们将 dir() 函数应用于 keyword 模块,并观察它揭示了什么:
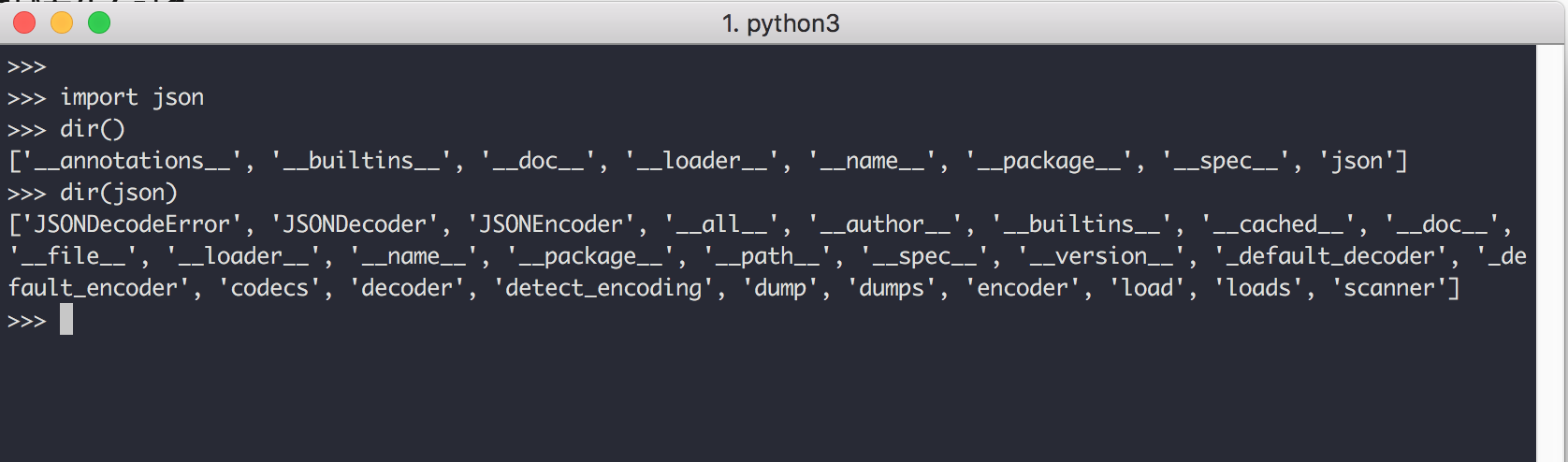
2. 应用到实际开发中
type()
type() 函数有助于我们确定对象是字符串还是整数,或是其它类型的对象。它通过返回类型对象来做到这一点,可以将这个类型对象与 types 模块中定义的类型相比较:
1 | |
hasattr()
使用 dir() 函数会返回一个对象的属性列表。
但是,有时我们只想测试一个或多个属性是否存在。如果对象具有我们正在考虑的属性,那么通常希望只检索该属性。这个任务可以由 hasattr() 来完成.
1 | |
getattr()
使用 hasattr 获知了对象拥有某个属性后,可以搭配 getattr() 函数来获取其属性值。
1 | |
使用 getattr 获取函数后,可以很方便地使用这个函数,比如下面这样,可以不再使写 json.dumps 这么字。
1 | |
id()
id() 函数返回对象的唯一标识符,标识符是一个整数。
1 | |
isinstance()
使用 isinstance() 函数可以确定一个对象是否是某个特定类型或定制类的实例。
1 | |
callable()
使用 callable 可以确定一个对象是否是可调用的,比如函数,类这些对象都是可以调用的对象。
1 | |
3. 模块(Modules)
_doc_
使用 __doc__ 这个魔法方法,可以查询该模块的文档,它输出的内容和 help() 一样。
_name_
始终是定义时的模块名;即使你使用import .. as 为它取了别名,或是赋值给了另一个变量名。
1 | |
_file_
包含了该模块的文件路径。需要注意的是内建的模块没有这个属性,访问它会抛出异常!
1 | |
_dict_
包含了模块里可用的属性名-属性的字典;也就是可以使用模块名.属性名访问的对象。
4. 类(Class)
_doc_
文档字符串。如果类没有文档,这个值是None。
1 | |
_name_
始终是定义时的类名。
1 | |
_dict_
包含了类里可用的属性名-属性的字典;也就是可以使用类名.属性名访问的对象。
1 | |
_module_
包含该类的定义的模块名;需要注意,是字符串形式的模块名而不是模块对象。
由于我是在 交互式命令行的环境下,所以模块是 __main__
1 | |
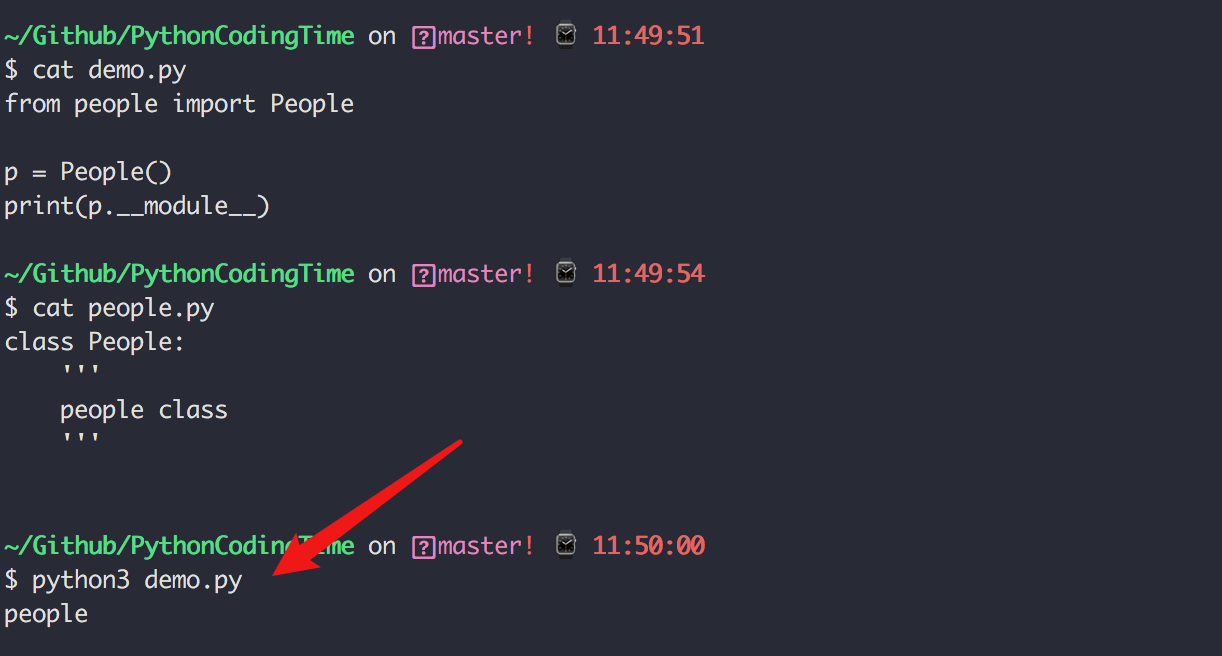
如果将上面的代码放入 demo.py,并且从 people 模块导入 People 类,其值就是 people 模块
_bases_
直接父类对象的元组;但不包含继承树更上层的其他类,比如父类的父类。
1 | |
5.6 【基础】偏函数的妙用
假如一个函数定义了多个位置参数,那你每次调用时,都需要把这些个参数一个一个地传递进去。
比如下面这个函数,是用来计算 x的n次方 的。
1 | |
那我每次计算 x 的 n 次方,都要传递两个参数
1 | |
后来我发现,我很多时候都是计算平方值,很多会去计算三次方,四次方。
那有什么办法可以偷个懒吗?
答案是,有。可以使用 偏函数。
偏函数(Partial Function),可以将某个函数的常用参数进行固定,避免每次调用时都要指定。
使用偏函数,需要导入 functools.partial ,然后利用它创建一个新函数,新函数的 n 固定等2。
具体使用请看下面的示例
1 | |
5.7 【进阶】泛型函数的使用
根据传入参数类型的不同而调用不同的函数逻辑体,这种实现我们称之为泛型。在 Python 中叫做 singledispatch。
singledispatch 是 PEP443 中引入的,如果你对此有兴趣,PEP443 应该是最好的学习文档:https://www.python.org/dev/peps/pep-0443/
它使用方法极其简单,只要被singledispatch 装饰的函数,就是一个single-dispatch 的泛函数(generic functions)。
- 单分派:根据一个参数的类型,以不同方式执行相同的操作的行为。
- 多分派:可根据多个参数的类型选择专门的函数的行为。
- 泛函数:多个函数绑在一起组合成一个泛函数。
这边举个简单的例子。
1 | |
执行结果
1 | |
说起泛型,其实在 Python 本身的一些内建函数中并不少见,比如 len() , iter(),copy.copy() ,pprint() 等
你可能会问,它有什么用呢?实际上真没什么用,你不用它或者不认识它也完全不影响你编码。
我这里举个例子,你可以感受一下。
大家都知道,Python 中有许许多的数据类型,比如 str,list, dict, tuple 等,不同数据类型的拼接方式各不相同,所以我这里我写了一个通用的函数,可以根据对应的数据类型对选择对应的拼接方式拼接,而且不同数据类型我还应该提示无法拼接。以下是简单的实现。
1 | |
输出结果如下
1 | |
如果不使用singledispatch 的话,你可能会写出这样的代码。
1 | |
输出如下
1 | |
5.8 【基础】变量的作用域
1. 作用域
Python的作用域可以分为四种:
- L (Local) 局部作用域
- E (Enclosing) 闭包函数外的函数中
- G (Global) 全局作用域
- B (Built-in) 内建作用域
变量/函数 的查找顺序:
L –> E –> G –>B
意思是,在局部找不到的,便去局部外的局部作用域找(例如 闭包),再找不到的就去全局作业域里找,再找不到就去内建作业域中找。
会影响 变量/函数 作用范围的有
- 函数:def 或 lambda
- 类:class
- 关键字:global noglobal
- 文件:*py
- 推导式:[],{},()等,仅限Py3.x中,Py2.x会出现变量泄露。
1、赋值在前,引用在后
1 | |
2、引用在前,赋值在后(同一作用域内)
1 | |
3、赋值在低层,引用在高层
1 | |
2. 闭包
闭包这个概念很重要噢。你一定要掌握。
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。其实装饰函数,很多都是闭包。
好像并不难理解,为什么初学者会觉得闭包难以理解呢?
我解释一下,你就明白了。
一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
你可以看下面这段代码,就构成了闭包。在内函数里可以引用外函数的变量。
1 | |
3. 改变作用域
变量的作用域,与其定义(或赋值)的位置有关,但不是绝对相关。
因为我们可以在某种程度上去改变向上的作用范围。
关键字:global
将 局部变量 变为全局变量关键字:nonlocal
可以在闭包函数中,引用并使用闭包外部函数的变量(非全局的噢)
global好理解,这里只讲下nonlocal。
先来看个例子
1 | |
运行一下,会报错。
1 | |
但是这样就OK
1 | |
其实,你如果不使用 +=、-=等一类的操作,不加nonlocal也没有关系。这就展示了闭包的特性。
1 | |
4. 变量集合
在Python中,有两个内建函数,你可能用不到,但是需要掌握它们。
- globals() :以dict的方式存储所有全局变量
- locals():以dict的方式存储所有局部变量
globals()
1 | |
locals()
1 | |
5.9 【进阶】上下文管理器
当你准备从一个文件中读取内容时,通常来说,都是这么写的。
1 | |
上面这种方法,需要你手动关闭文件句柄,但是很多时候,程序员是会忘记这一操作的。
因为推荐你使用下面这种方法,使用 with 这个关键字,可以在文件读取结束后,自动关闭文件句柄。
1 | |
使用 Python 的专业术语来说,with 的这个用法叫做 上下文管理器。
1. 什么是上下文管理器?
基本语法
1 | |
从上面这个语法中,先理清几个概念:
- 上下文表达式:
with open('test.txt') as file: - 上下文管理器:
open('test.txt') file不是上下文管理器,应该是资源对象。
2. 如何写上下文管理器?
要手动实现一个上下文管理器,需要你有对类有一些了解,至少需要知道什么是类,怎么定义类。对于类的知识,我放在了第七章,因此你可以先前往学习下第七章的的第一节内容:7.1 类的理解与使用 。
学习了类的基本知识,想要自己实现这样一个上下文管理,就简单了。
你只要在一个类里实现上下文管理协议,简单点说,就是在一个类里,定义了__enter__和__exit__的方法,这个类的实例就是一个上下文管理器。
例如这个示例:
1 | |
我们执行一下,通过日志的打印顺序。可以知道其执行过程。
1 | |
从这个示例可以很明显的看出,在编写代码时,可以将资源的连接或者获取放在__enter__中,而将资源的关闭写在__exit__ 中。
3. 为什么需要上下文管理器?
学习时多问自己几个为什么,养成对一些细节的思考,有助于加深对知识点的理解。
为什么要使用上下文管理器?
在我看来,这和 Python 崇尚的优雅风格有关。
- 可以以一种更加优雅的方式,操作(创建/获取/释放)资源,如文件操作、数据库连接;
- 可以以一种更加优雅的方式,处理异常;
第一种,我们上面已经以资源的连接为例讲过了。
而第二种,会被大多数人所忽略。这里会重点讲一下。
大家都知道,处理异常,通常都是使用 try...execept.. 来捕获处理的。这样做一个不好的地方是,在代码的主逻辑里,会有大量的异常处理代理,这会很大的影响我们的可读性。
好一点的做法呢,可以使用 with 将异常的处理隐藏起来。
仍然是以上面的代码为例,我们将1/0 这个一定会抛出异常的代码写在 operate 里
1 | |
运行一下,惊奇地发现,居然不会报错。
这就是上下文管理协议的一个强大之处,异常可以在__exit__ 进行捕获并由你自己决定如何处理,是抛出呢还是在这里就解决了。在__exit__ 里返回 True(没有return 就默认为 return False),就相当于告诉 Python解释器,这个异常我们已经捕获了,不需要再往外抛了。
在 写__exit__ 函数时,需要注意的事,它必须要有这三个参数:
- exc_type:异常类型
- exc_val:异常值
- exc_tb:异常的错误栈信息
当主逻辑代码没有报异常时,这三个参数将都为None。
4. 学会使用 contextlib
在上面的例子中,我们只是为了构建一个上下文管理器,却写了一个类。如果只是要实现一个简单的功能,写一个类未免有点过于繁杂。这时候,我们就想,如果只写一个函数就可以实现上下文管理器就好了。
这个点Python早就想到了。它给我们提供了一个装饰器,你只要按照它的代码协议来实现函数内容,就可以将这个函数对象变成一个上下文管理器。
我们按照 contextlib 的协议来自己实现一个打开文件(with open)的上下文管理器。
1 | |
在被装饰函数里,必须是一个生成器(带有yield),而yield之前的代码,就相当于__enter__里的内容。yield 之后的代码,就相当于__exit__ 里的内容。
上面这段代码只能实现上下文管理器的第一个目的(管理资源),并不能实现第二个目的(处理异常)。
如果要处理异常,可以改成下面这个样子。
1 | |
好像只要讲到上下文管理器,大多数人都会谈到打开文件这个经典的例子。
但是在实际开发中,可以使用到上下文管理器的例子也不少。我这边举个我自己的例子。
在OpenStack中,给一个虚拟机创建快照时,需要先创建一个临时文件夹,来存放这个本地快照镜像,等到本地快照镜像创建完成后,再将这个镜像上传到Glance。然后删除这个临时目录。
这段代码的主逻辑是创建快照,而创建临时目录 ,属于前置条件,删除临时目录,是收尾工作。
虽然代码量很少,逻辑也不复杂,但是“创建临时目录,使用完后再删除临时目录”这个功能,在一个项目中很多地方都需要用到,如果可以将这段逻辑处理写成一个工具函数作为一个上下文管理器,那代码的复用率也大大提高。
代码是这样的
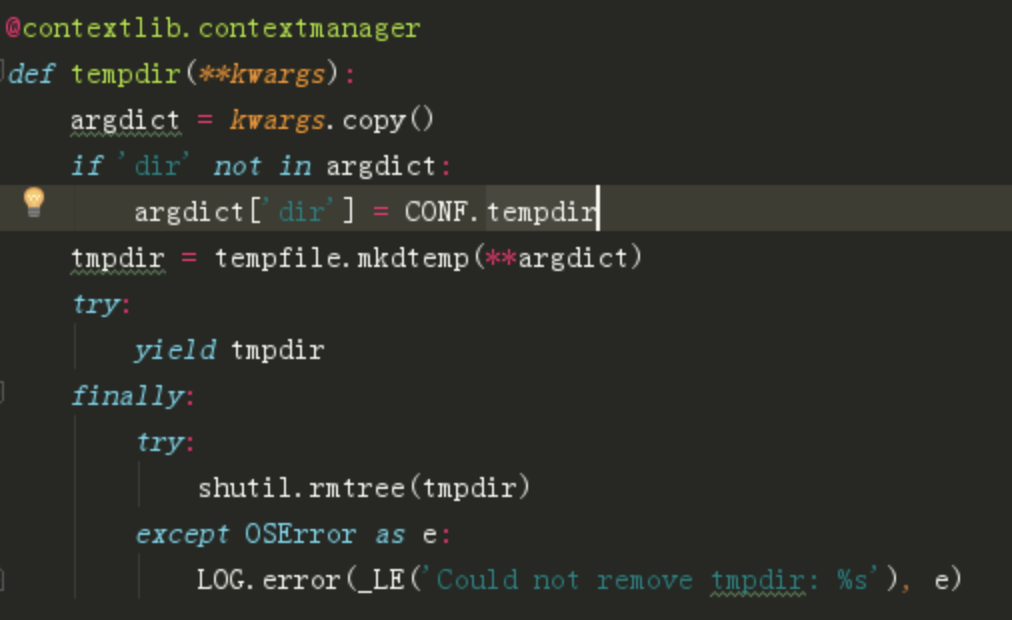
5. 总结起来
使用上下文管理器有三个好处:
- 提高代码的复用率;
- 提高代码的优雅度;
- 提高代码的可读性;
5.10 【进阶】装饰器的六种写法
Hello,装饰器
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。
它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。
装饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。
装饰器的使用方法很固定
- 先定义一个装饰器(帽子)
- 再定义你的业务函数或者类(人)
- 最后把这装饰器(帽子)扣在这个函数(人)头上
就像下面这样子
1 | |
实际上,装饰器并不是编码必须性,意思就是说,你不使用装饰器完全可以,它的出现,应该是使我们的代码
- 更加优雅,代码结构更加清晰
- 将实现特定的功能代码封装成装饰器,提高代码复用率,增强代码可读性
接下来,我将以实例讲解,如何编写出各种简单及复杂的装饰器。
第一种:普通装饰器
首先咱来写一个最普通的装饰器,它实现的功能是:
- 在函数执行前,先记录一行日志
- 在函数执行完,再记录一行日志
1 | |
假如,我的业务函数是,计算两个数之和。写好后,直接给它带上帽子。
1 | |
然后执行一下 add 函数。
1 | |
来看看输出了什么?
1 | |
第二种:带参数的函数装饰器
通过上面两个简单的入门示例,你应该能体会到装饰器的工作原理了。
不过,装饰器的用法还远不止如此,深究下去,还大有文章。今天就一起来把这个知识点学透。
回过头去看看上面的例子,装饰器是不能接收参数的。其用法,只能适用于一些简单的场景。不传参的装饰器,只能对被装饰函数,执行固定逻辑。
装饰器本身是一个函数,做为一个函数,如果不能传参,那这个函数的功能就会很受限,只能执行固定的逻辑。这意味着,如果装饰器的逻辑代码的执行需要根据不同场景进行调整,若不能传参的话,我们就要写两个装饰器,这显然是不合理的。
比如我们要实现一个可以定时发送邮件的任务(一分钟发送一封),定时进行时间同步的任务(一天同步一次),就可以自己实现一个 periodic_task (定时任务)的装饰器,这个装饰器可以接收一个时间间隔的参数,间隔多长时间执行一次任务。
可以这样像下面这样写,由于这个功能代码比较复杂,不利于学习,这里就不贴了。
1 | |
那我们来自己创造一个伪场景,可以在装饰器里传入一个参数,指明国籍,并在函数执行前,用自己国家的母语打一个招呼。
1 | |
那我们如果实现这个装饰器,让其可以实现 传参 呢?
会比较复杂,需要两层嵌套。
1 | |
来执行一下
1 | |
看看输出结果。
1 | |
第三种:不带参数的类装饰器
以上都是基于函数实现的装饰器,在阅读别人代码时,还可以时常发现还有基于类实现的装饰器。
基于类装饰器的实现,必须实现 __call__ 和 __init__两个内置函数。__init__ :接收被装饰函数__call__ :实现装饰逻辑。
还是以日志打印这个简单的例子为例
1 | |
执行一下,看看输出
1 | |
第四种:带参数的类装饰器
上面不带参数的例子,你发现没有,只能打印INFO级别的日志,正常情况下,我们还需要打印DEBUG WARNING等级别的日志。 这就需要给类装饰器传入参数,给这个函数指定级别了。
带参数和不带参数的类装饰器有很大的不同。
__init__ :不再接收被装饰函数,而是接收传入参数。__call__ :接收被装饰函数,实现装饰逻辑。
1 | |
我们指定WARNING级别,运行一下,来看看输出。
1 | |
第五种:使用偏函数与类实现装饰器
绝大多数装饰器都是基于函数和闭包实现的,但这并非制造装饰器的唯一方式。
事实上,Python 对某个对象是否能通过装饰器( @decorator)形式使用只有一个要求:decorator 必须是一个“可被调用(callable)的对象。
对于这个 callable 对象,我们最熟悉的就是函数了。
除函数之外,类也可以是 callable 对象,只要实现了__call__ 函数(上面几个例子已经接触过了)。
还有容易被人忽略的偏函数其实也是 callable 对象。
接下来就来说说,如何使用 类和偏函数结合实现一个与众不同的装饰器。
如下所示,DelayFunc 是一个实现了 __call__ 的类,delay 返回一个偏函数,在这里 delay 就可以做为一个装饰器。(以下代码摘自 Python工匠:使用装饰器的小技巧)
1 | |
我们的业务函数很简单,就是相加
1 | |
来看一下执行过程
1 | |
第六种:能装饰类的装饰器
用 Python 写单例模式的时候,常用的有三种写法。其中一种,是用装饰器来实现的。
以下便是我自己写的装饰器版的单例写法。
1 | |
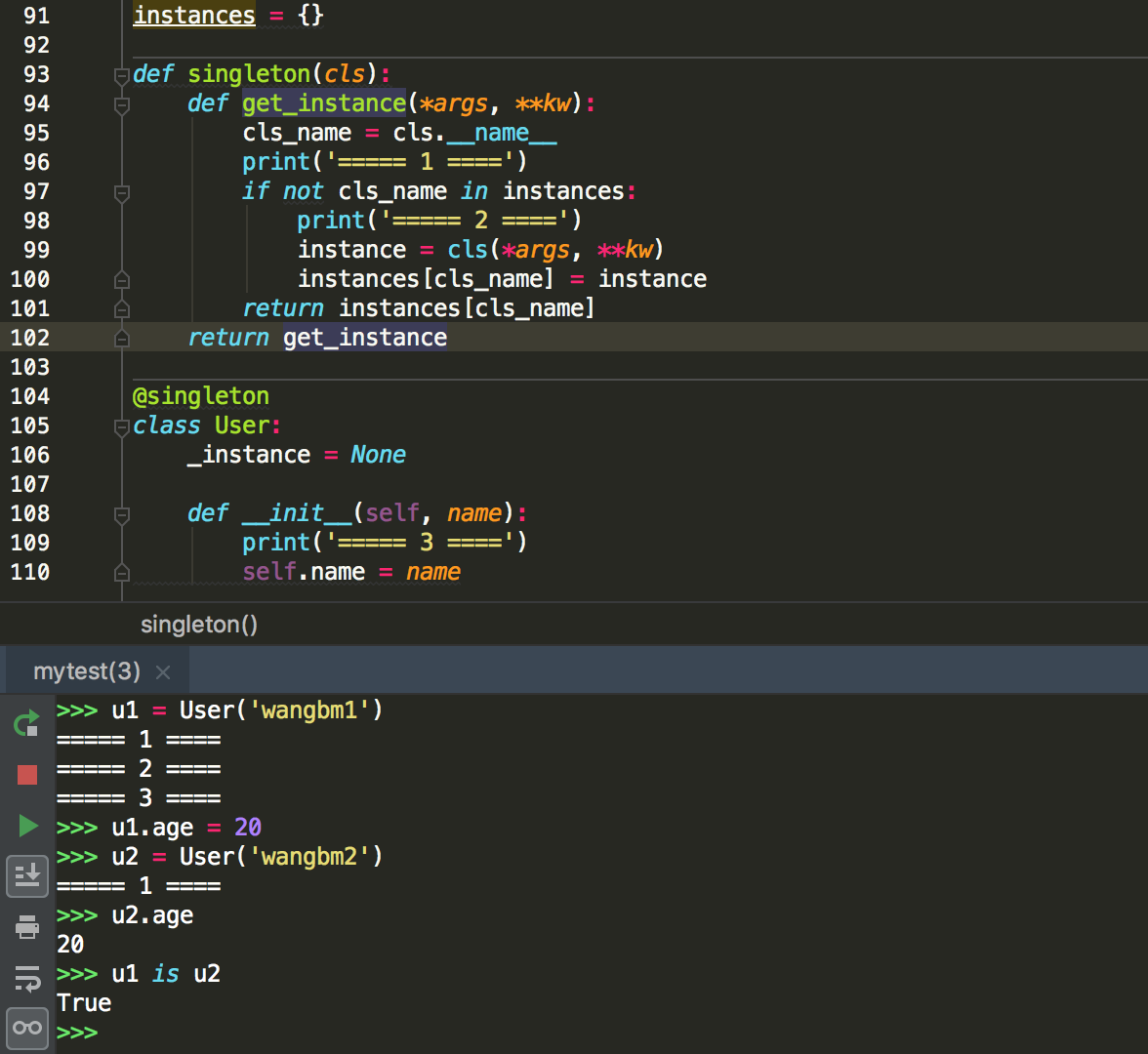
可以看到我们用singleton 这个装饰函数来装饰 User 这个类。装饰器用在类上,并不是很常见,但只要熟悉装饰器的实现过程,就不难以实现对类的装饰。在上面这个例子中,装饰器就只是实现对类实例的生成的控制而已。
其实例化的过程,你可以参考我这里的调试过程,加以理解。
第六章:错误异常
6.1 【基础】什么是异常?
在程序运行过程中,总会遇到各种各样的问题和错误。
有些错误是我们编写代码时自己造成的,比如语法错误、调用错误,甚至逻辑错误。下面这个例子,在输入 if 后输入回车了,没有按照 Python 的语法规则来,所以直接抛出了语法错误。
1
2
3
4
5>>> if
File "<stdin>", line 1
if
^
SyntaxError: invalid syntax还有一些错误,则是不可预料的错误,但是完全有可能发生的,比如文件不存在、磁盘空间不足、网络堵塞、系统错误等等。下面这个例子,使用 open 函数打开
demo.txt文件,可是在当前目录下并没有这个文件,所以一定会打开失败,抛出了IOError。1
2
3
4>>> fp = open('demo.txt')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IOError: [Errno 2] No such file or directory: 'demo.txt'
这些导致程序在运行过程中出现异常中断和退出的错误,我们统称为异常。正常情况下,异常都不会被程序处理,而是以错误信息的形式展现出来。
异常有很多种类型,Python内置了几十种常见的异常,就在builtins模块内,它们无需特别导入,就可以直接使用。需要注意的是,所有的异常都是异常类,首字母是大写的!
在发生异常的时候,Python会打印出异常信息,信息的前面部分显示了异常发生的上下文环境,并以调用栈的形式显示具体信息。异常类型作为信息的一部分也会被打印出来,例如ZeroDivisionError,TypeError。
1 | |
正常情况下,我们都不需要去记住 Python 到底内置了哪些错误和异常类型,除非你需要去捕获它,关于捕获的内容,我会放在下一节。这一节先来认识一下 Python 中有哪些常见的错误和异常,对于新手,下面的内容大概过一下就好,不用深究,因为这些在你以后的编码中都会遇到的。
1.SyntaxError
SyntaxError,是语法错误,可能是新手在学习 Python 时最容易遇到的错误
1 | |
解析器会输出出现语法错误的那一行,并显示一个“箭头”,指向这行里面检测到的第一个错误。 错误是由箭头指示的位置 上面 的 token 引起的(或者至少是在这里被检测出的):在示例中,在 print() 这个函数中检测到了错误,因为在它前面少了个冒号 (':') 。文件名和行号也会被输出,以便输入来自脚本文件时你能知道去哪检查。
2、TypeError
TypeError,是类型错误,也就是说将某个操作或功能应用于不合适类型的对象时引发,比如整型与字符型进行加减法
1 | |
3、IndexError
IndexError,是指索引出现了错误,比如最常见下标索引超出了序列边界
1 | |
4、KeyError
KeyError是关键字错误,这个异常主要发生在字典中,比如当用户试图访问一个字典中不存在的键时会被引发。
1 | |
5、ValueError
ValueError为值错误,当用户传入一个调用者不期望的值时会引发,即使这个值的类型是正确的,比如想获取一个列表中某个不存在值的索引。
1 | |
6、AttributeError
AttributeError是属性错误,当用户试图访问一个对象不存在的属性时会引发。
比如字典有get方法,而列表却没有,所以对一个列表对象调用该方法就会引发该异常。
1 | |
7、NameError
NameError是指变量名称发生错误,比如用户试图调用一个还未被赋值或初始化的变量时会被触发。
1 | |
8、IOError
IOError 为打开文件错误,当用户试图以读取方式打开一个不存在的文件时引发。
1 | |
9、StopIteration
StopIteration为迭代器错误,当访问至迭代器最后一个值时仍然继续访问,就会引发这种异常,提醒用户迭代器中已经没有值可供访问了。
1 | |
10、AssertionError
AssertionError 为断言错误,当用户利用断言语句检测异常时,如果断言语句检测的表达式为假,则会引发这种异常。
1 | |
11. IndentationError
Python 是一门严格缩进的语言,如果缩进有问题,就会导致解释器解析异常,抛出 IndentationError
1 | |
12. ImportError
当你在使用 import 导包的时候,如果因为包名错误或者路径不对、包未安装,都会抛出 ImportError
1 | |
上面这些异常应该是平时编程中遇见频率比较高的一部分,还有更多的异常,可以前往官方文档:https://docs.python.org/3/library/exceptions.html## 6.2 【基础】如何抛出和捕获异常?
1. 如何抛出异常?
异常的产生有两种来源:
- 一种是程序自动抛出,比如
1/0会自动抛出 ZeroDivisionError - 一种是开发者主动抛出,使用
raise关键字抛出。
在 Python 中是使用 raise 关键字来抛出异常的,比如在下面这个函数中,如果不存在目标文件,则会抛出一个 Exception 通用异常。
1 | |
2. 如何捕获异常?
出现错误或者异常没有关系,关键在于你要学会预判程序可能会出现的错误或异常,然后在代码中捕获这些异常并处理。
异常的捕获的语法有如下四种:
第一种语法
只捕捉但是不想获取异常信息
1 | |
第二种语法
不但捕捉了还要获取异常信息,赋值给 e 后,后面你可以把异常信息打印到日志中。
1 | |
有了上面的基础语法,可以扩展出下面三种常用的异常捕获的写法。
第三种语法
正常使用 try ... except ...
如果代码A发生了异常,则会走到代码B的逻辑。
1 | |
举个例子
1 | |
第四种语法
使用 try ... except ... else
如果代码A发生了异常,则会走到代码B的逻辑,如果没有发生异常,则会走到代码C
1 | |
举个例子
不发生异常的情况
1 | |
发生异常的情况
1 | |
- 第三种:使用
try ... except ... finally
如果代码A发生了异常,则会走到代码B的逻辑,最后不管有没有发生异常都会走到代码C
1 | |
举个例子
发生异常的情况
1 | |
不发生异常的情况
1 | |
3. 捕获多个异常?
每个except捕获一个异常
一个 try 语句可能有多个 except 子句,以指定不同异常的处理程序,但是最多会执行一个处理程序。
当代码 A 在运行中抛出了异常时,Python 解释器会逐行运行代码,如果抛出的异常是 exception1 那么后面直接运行代码B,运行完 B 后,就不会再判断后面两个 except 语句了。
而如果不是 exception1 ,而是 exception2 ,那会运行代码C,而不会再运行第三个 except 语句了。
1 | |
举个例子吧,下面这段代码,由于 1/0 会抛出 ZeroDivisionError 错误,所以前面两个异常匹配都不成功,而在最后一个 except 成功匹配上,最终打印出 除数不能为 0
1 | |
一个except捕获多个异常
上面的例子可以看出来,第二个异常和第三个异常是属于同一类,就是 计算错误,异常处理的代码是一样的,那有没有办法将它们合并在一起呢,简化一下代码呢?
答案是,可以的。
在 except 后面其实是可以接多个异常的,多个异常之间使用括号包裹。只要匹配上一个就算捕获到,就会进入相应的代码分支。
1 | |
6.3 【基础】如何自定义异常?
大多数情况下,内置的错误和异常已经够用了,但是有时候你还是需要自定义一些异常。
自定义异常,需要你对 类 与 继承 有一些了解,对于类的知识,我放在了第七章,因此你可以先前往学习下第七章的的下面两节内容:
等学习完后再回过头来学习本节内容。
自定义异常应该继承 Exception 类,直接继承或者间接继承都可以,自定义的异常或错误类,下面使用 InputError ,表示接受用户输入时发生问题。
1 | |
异常的名字都以Error结尾,我们在为自定义异常命名的时候也需要遵守这一规范,就跟标准的异常命名一样。
定义完后,再看如下代码,我在 try 里调用 get_input 函数,如果发现用户没有输入内容,就使用 raise 关键字来抛出 InputError。
1 | |
6.4 【进阶】如何关闭异常自动关联上下文?
当你在处理异常时,由于处理不当或者其他问题,再次抛出另一个异常时,往外抛出的异常也会携带原始的异常信息。
就像这样子。
1 | |
从输出可以看到两个异常信息
1 | |
如果在异常处理程序或 finally 块中引发异常,默认情况下,异常机制会隐式工作会将先前的异常附加为新异常的 __context__属性。这就是 Python 默认开启的自动关联异常上下文。
如果你想自己控制这个上下文,可以加个 from 关键字(from 语法会有个限制,就是第二个表达式必须是另一个异常类或实例。),来表明你的新异常是直接由哪个异常引起的。
1 | |
输出如下
1 | |
当然,你也可以通过with_traceback()方法为异常设置上下文__context__属性,这也能在traceback更好的显示异常信息。
1 | |
最后,如果我想彻底关闭这个自动关联异常上下文的机制?有什么办法呢?
可以使用 raise...from None,从下面的例子上看,已经没有了原始异常
1 | |
6.5 【进阶】异常处理的三个好习惯
本文作者:piglei
本文来源:https://github.com/piglei/one-python-craftsman
如果你用 Python 编程,那么你就无法避开异常,因为异常在这门语言里无处不在。打个比方,当你在脚本执行时按 ctrl+c 退出,解释器就会产生一个 KeyboardInterrupt 异常。而 KeyError、ValueError、TypeError 等更是日常编程里随处可见的老朋友。
异常处理工作由“捕获”和“抛出”两部分组成。“捕获”指的是使用 try ... except 包裹特定语句,妥当的完成错误流程处理。而恰当的使用 raise 主动“抛出”异常,更是优雅代码里必不可少的组成部分。
在这篇文章里,我会分享与异常处理相关的 3 个好习惯。继续阅读前,我希望你已经了解了下面这些知识点:
- 异常的基本语法与用法(建议阅读官方文档 “Errors and Exceptions”)
- 为什么要使用异常代替错误返回(建议阅读《让函数返回结果的技巧》)
- 为什么在写 Python 时鼓励使用异常 (建议阅读 “Write Cleaner Python: Use Exceptions”)
1. 只做最精确的异常捕获
假如你不够了解异常机制,就难免会对它有一种天然恐惧感。你可能会觉得:异常是一种不好的东西,好的程序就应该捕获所有的异常,让一切都平平稳稳的运行。而抱着这种想法写出的代码,里面通常会出现大段含糊的异常捕获逻辑。
让我们用一段可执行脚本作为样例:
1 | |
脚本里的 save_website_title 函数做了好几件事情。它首先通过网络获取网页内容,然后利用正则匹配出标题,最后将标题写在本地文件里。而这里有两个步骤很容易出错:网络请求 与 本地文件操作。所以在代码里,我们用一个大大的 try ... except 语句块,将这几个步骤都包裹了起来。安全第一 ⛑。
那么,这段看上去简洁易懂的代码,里面藏着什么问题呢?
如果你旁边刚好有一台安装了 Python 的电脑,那么你可以试着跑一遍上面的脚本。你会发现,上面的代码是不能成功执行的。而且你还会发现,无论你如何修改网址和目标文件的值,程序仍然会报错 “save failed: unable to…”。为什么呢?
问题就藏在这个硕大无比的 try ... except 语句块里。假如你把眼睛贴近屏幕,非常仔细的检查这段代码。你会发现在编写函数时,我犯了一个小错误,我把获取正则匹配串的方法错打成了 obj.grop(1),少了一个 ‘u’(obj.group(1))。
但正是因为那个过于庞大、含糊的异常捕获,这个由打错方法名导致的原本该被抛出的 AttibuteError 却被吞噬了。从而给我们的 debug 过程增加了不必要的麻烦。
异常捕获的目的,不是去捕获尽可能多的异常。假如我们从一开始就坚持:只做最精准的异常捕获。那么这样的问题就根本不会发生,精准捕获包括:
- 永远只捕获那些可能会抛出异常的语句块
- 尽量只捕获精确的异常类型,而不是模糊的
Exception
依照这个原则,我们的样例应该被改成这样:
1 | |
2. 别让异常破坏抽象一致性
大约四五年前,当时的我正在开发某移动应用的后端 API 项目。如果你也有过开发后端 API 的经验,那么你一定知道,这样的系统都需要制定一套“API 错误码规范”,来为客户端处理调用错误时提供方便。
一个错误码返回大概长这个样子:
1 | |
在制定好错误码规范后,接下来的任务就是如何实现它。当时的项目使用了 Django 框架,而 Django 的错误页面正是使用了异常机制实现的。打个比方,如果你想让一个请求返回 404 状态码,那么只要在该请求处理过程中执行 raise Http404 即可。
所以,我们很自然的从 Django 获得了灵感。首先,我们在项目内定义了错误码异常类:APIErrorCode。然后依据“错误码规范”,写了很多继承该类的错误码。当需要返回错误信息给用户时,只需要做一次 raise 就能搞定。
1 | |
毫无意外,所有人都很喜欢用这种方式来返回错误码。因为它用起来非常方便,无论调用栈多深,只要你想给用户返回错误码,调用 raise error_codes.ANY_THING 就好。
随着时间推移,项目也变得越来越庞大,抛出 APIErrorCode 的地方也越来越多。有一天,我正准备复用一个底层图片处理函数时,突然碰到了一个问题。
我看到了一段让我非常纠结的代码:
1 | |
process_image 函数会尝试解析一个文件对象,如果该对象不能被作为图片正常打开,就抛出 error_codes.INVALID_IMAGE_UPLOADED (APIErrorCode 子类) 异常,从而给调用方返回错误代码 JSON。
让我给你从头理理这段代码。最初编写 process_image 时,我虽然把它放在了 util.image 模块里,但当时调这个函数的地方就只有 “处理用户上传图片的 POST 请求” 而已。为了偷懒,我让函数直接抛出 APIErrorCode 异常来完成了错误处理工作。
再来说当时的问题。那时我需要写一个在后台运行的批处理图片脚本,而它刚好可以复用 process_image 函数所实现的功能。但这时不对劲的事情出现了,如果我想复用该函数,那么:
- 我必须去捕获一个名为
INVALID_IMAGE_UPLOADED的异常- 哪怕我的图片根本就不是来自于用户上传
- 我必须引入
APIErrorCode异常类作为依赖来捕获异常- 哪怕我的脚本和 Django API 根本没有任何关系
这就是异常类抽象层级不一致导致的结果。APIErrorCode 异常类的意义,在于表达一种能够直接被终端用户(人)识别并消费的“错误代码”。它在整个项目里,属于最高层的抽象之一。但是出于方便,我们却在底层模块里引入并抛出了它。这打破了 image.processor 模块的抽象一致性,影响了它的可复用性和可维护性。
这类情况属于“模块抛出了高于所属抽象层级的异常”。避免这类错误需要注意以下几点:
- 让模块只抛出与当前抽象层级一致的异常
- 比如
image.processer模块应该抛出自己封装的ImageOpenError异常
- 比如
- 在必要的地方进行异常包装与转换
- 比如,应该在贴近高层抽象(视图 View 函数)的地方,将图像处理模块的
ImageOpenError低级异常包装转换为APIErrorCode高级异常
- 比如,应该在贴近高层抽象(视图 View 函数)的地方,将图像处理模块的
修改后的代码:
1 | |
除了应该避免抛出高于当前抽象级别的异常外,我们同样应该避免泄露低于当前抽象级别的异常。
如果你用过 requests 模块,你可能已经发现它请求页面出错时所抛出的异常,并不是它在底层所使用的 urllib3 模块的原始异常,而是通过 requests.exceptions 包装过一次的异常。
1 | |
这样做同样是为了保证异常类的抽象一致性。因为 urllib3 模块是 requests 模块依赖的底层实现细节,而这个细节有可能在未来版本发生变动。所以必须对它抛出的异常进行恰当的包装,避免未来的底层变更对 requests 用户端错误处理逻辑产生影响。
3. 异常处理不应该喧宾夺主
在前面我们提到异常捕获要精准、抽象级别要一致。但在现实世界中,如果你严格遵循这些流程,那么很有可能会碰上另外一个问题:异常处理逻辑太多,以至于扰乱了代码核心逻辑。具体表现就是,代码里充斥着大量的 try、except、raise 语句,让核心逻辑变得难以辨识。
让我们看一段例子:
1 | |
这是一个处理用户上传头像的视图函数。这个函数内做了三件事情,并且针对每件事都做了异常捕获。如果做某件事时发生了异常,就返回对用户友好的错误到前端。
这样的处理流程纵然合理,但是显然代码里的异常处理逻辑有点“喧宾夺主”了。一眼看过去全是代码缩进,很难提炼出代码的核心逻辑。
早在 2.5 版本时,Python 语言就已经提供了对付这类场景的工具:“上下文管理器(context manager)”。上下文管理器是一种配合 with 语句使用的特殊 Python 对象,通过它,可以让异常处理工作变得更方便。
那么,如何利用上下文管理器来改善我们的异常处理流程呢?让我们直接看代码吧。
1 | |
在上面的代码里,我们定义了一个名为 raise_api_error 的上下文管理器,它在进入上下文时什么也不做。但是在退出上下文时,会判断当前上下文中是否抛出了类型为 self.captures 的异常,如果有,就用 APIErrorCode 异常类替代它。
使用该上下文管理器后,整个函数可以变得更清晰简洁:
1 | |
Hint:建议阅读 PEP 343 – The “with” Statement | Python.org,了解与上下文管理器有关的更多知识。
模块 contextlib 也提供了非常多与编写上下文管理器相关的工具函数与样例。
总结一下
在这篇文章中,我分享了与异常处理相关的三个建议。最后再总结一下要点:
- 只捕获可能会抛出异常的语句,避免含糊的捕获逻辑
- 保持模块异常类的抽象一致性,必要时对底层异常类进行包装
- 使用“上下文管理器”可以简化重复的异常处理逻辑
第七章:类与对象
7.1 【基础】类的理解与使用
1. 通俗理解类
类(英文名 class),是具有相同特性(属性)和行为(方法)的对象(实例)的抽象模板。
从定义上来理解类,是一件非常吃力的事情,特别是对那些没有任何基础的初学者。
下面我举例来说明类中一些关键术语都是什么意思:
- 类:动物属于一个类,植物属于一个类
- 实例:猫和狗都属于同一类,就是动物类,那么猫和狗是动物类的实例/对象。
- 属性:类中所有的变量,都叫做属性。
- 方法:类中的所有函数,都叫做方法。
类与对象的关系就如模具和铸件的关系,类的实例化的结果就是对象,而对象的抽象就是类,类描述了一组有相同特性(属性)和相同行为(方法)的对象。
2. 如何定义类?
定义一个类,使用的是 class 关键字
下边我定义了一个 Animal 的类
1 | |
其中
Animal是类名__init__是构造函数,用于实例的初始化self.name是实例属性,age是类属性run是方法,第一个参数 self 是什么意思呢?这个咱后面再讲。
除了上面这种写法外
1 | |
还有另外两种写法,与之是等价的
1 | |
因为在 Python 3 中,无论你是否显示继承自 object,Python 解释器都会默认你继承 object ,这是新式类的写法,与之对应的是 Python 2 的经典类写法(Python 2 已经远去,无需要再了解经典类写法)。
3. 如何实例化?
定义了类之后,就可以通过下边的写法实例化它,并访问属性,调用方法
1 | |
在实例化时传入的参数 name="小黑" 传进入到构造函数 __init__ 中,最终赋值 self.name 成为实例的属性。
4. 方法的调用
实例化成对象后,如果访问实例属性,可以用 对象.属性名 进行访问。
1 | |
如果要调用方法,有两种方法
- 通过
对象.方法名:使用这种方法,在定义方法时 self 就代表对象(dog),调用时无需再传入了。
1 | |
- 通过
类.方法名:使用这种方法,self 参数要传入实例对象
1 | |
7.2 【基础】静态方法与类方法
1. 写法上的差异
类的方法可以分为:
- 静态方法:有
staticmethod装饰的函数 - 类方法:有
classmethod装饰的函数 - 实例方法:没有任何装饰器的普通函数
举个例子,如下这段代码中,run 普通的实例方法,eat 是静态方法,jump 是类方法。
1 | |
这三种方法,在写法有很大的区别:
1、普通的实例方法,在定义时,他的第一个方法固定是 self,如果是从实例调用,那么 self 参数 不需要传入,如果是通过类调用,那么 self 要传入已经实例化的对象。
1 | |
2、静态方法,在定义时,不需要 self 参数。
1 | |
3、类方法,在定义时,第一个参数固定是 cls,为 class 的简写,代表类本身。不管是通过实例还是类调用类方法,都不需要传入 cls 的参数。
1 | |
2. 方法与函数区别
在前面,我们很经常提到方法和函数,为免有同学将他们混为一谈,我这里总结一下他们的区别。
在 Python 3.x 中,
普通函数(未定位在类里)和静态方法,都是函数(
function)。实例方法(@staticmethod)和类方法,都是方法(
method)。
这些结论其实都可以使用 type 函数得到验证。
先准备如下代码
1 | |
然后进入 Python Console 模式
1 | |
到这里,你应该会有疑问了吧?
类方法和实例方法,名字本身就有方法,也是方法也说得过去。那静态方法呢,为什么不是方法而是函数呢?
对此,我的理解是:方法是一种和对象(实例或者类)绑定后的特殊函数。
方法本质上还是函数,不同之处在于它与对象进行绑定。## 7.3 【基础】私有变量与私有方法
1. 下划线妙用
在 Python 中,下划线可是非常推荐使用的符号:
- 变量名推荐使用下划线分隔的蛇形命名法
- 魔法方法、构造函数都需要使用双下划线
- 对于暂时用不到的变量值,可以赋值给单下划线
_进行占位
根据分类,我把下划线写法分成下面五种:
- 单前导下划线:
_var - 单末尾下划线:
var_ - 双前导下划线:
__var - 双前导和末尾下划线:
__var__ - 单下划线:
_
由于篇幅所限,本篇将只介绍跟标题(私有变量与私有方法)有关的用法,也就是访问控制。
上面五种写法中,涉及到访问控制的有:_var 和 __var
2. 单前导下划线 _var
下划线前缀的含义是告知其他程序员:以单个下划线开头的变量或方法仅供内部使用。
请看下面这个例子
1 | |
如果你实例化此类,然后分别访问 self.foo 和 self._bar 会发生什么情况?
1 | |
结果是:外界都可以直接访问这两个属性。
但实际上,二者是有区别的。PEP 8 有提及,如果一个属性的有单前导下划线,则该属性应该仅供内部访问。
但这并不是强制性的,不然上面我们也不可能通过 self._bar 访问到 22,但做为一名 Python 程序员最好遵守这一共识。
3. 双前导下划线 __var
双下划线前缀会导致Python解释器重写属性名称,以避免子类中的命名冲突。
这也叫做名称修饰(name mangling) - 解释器更改变量的名称,以便在类被扩展的时候不容易产生冲突。
我知道这听起来很抽象。因此,我组合了一个小小的代码示例来予以说明:
1 | |
将其进行实例化,然后使用 dir() 函数查看这个对象的属性
1 | |
不难发现,foo 和 _bar 都很正常,可以使用 demo.属性名 进行访问。
但 __baz 明显和 foo 、 _bar 不一样,尝试访问后却报了 AttributeError,属性不存在。
1 | |
如果你仔细观察,你会看到此对象上有一个名为_Demo__baz的属性。这就是Python解释器所做的名称修饰。它这样做是为了防止变量在子类中被重写。
如果想访问,那得按照 dir 提示的写法去访问,在 __baz 前面加上 _类名。
1 | |
总结可得,使用双下划线开头的属性变量,就是一个私有变量。
这样的规则在属性上生效,在方法上也同样适用。
如果一个实例方法,以双下划线开头,那么这个方法就是一个私有的方法,不能由实例对象或者类直接调用。
必须得通过 实例._类名__方法名 来调用。
4. 总结一下
Python并没有真正的私有化支持,但可用下划线得到伪私有。
尽量避免定义以下划线开头的变量。
- 私有变量:以双下划线前导的变量,可以使用
实例._类名__变量名进行访问 - 私有方法:以双下划线前导的方法,可以使用
实例._类名__方法名()进行访问
私有变量和私有方法,虽然有办法访问,但是仍然不建议使用上面给出的方法直接访问,而应该接口统一的接口(函数入口)来对私有变量进行查看、变量,对私有方法进行调用。对于这些内容我放到了下一节的的封装,请继续往后学习。
7.4 【基础】类的封装(Encapsulation)
封装是指将数据与具体操作的实现代码放在某个对象内部,使这些代码的实现细节不被外界发现,外界只能通过接口使用该对象,而不能通过任何形式修改对象内部实现。
要了解封装,离不开“私有化”,就是将类或者是函数中的某些属性限制在某个区域之内,外部无法直接调用。
关于什么是 私有化变量和私有化函数,在上一节我已经很详细的讲过啦。
私有变量和私有方法,虽然有办法访问,但是仍然不建议使用上面给出的方法直接访问,而应该接口统一的接口(函数入口)来对私有变量进行查看、变量,对私有方法进行调用。这就是封装。
正是由于封装机制,程序在使用某一对象时不需要关心该对象的数据结构细节及实现操作的方法。使用封装能隐藏对象实现细节,使代码更易维护,同时因为不能直接调用、修改对象内部的私有信息,在一定程度上保证了系统安全性。类通过将函数和变量封装在内部,实现了比函数更高一级的封装。
请看下面这段代码
1 | |
我定义了一个 Person 的类,它有 name 和 age 两个属性。
如果想判断小明是不是成年人,需要使用 xh.age 来与 18 比较。
对于很多女生还来说,年龄是非常隐私的。如果不想年龄被人随意就获取,可以在 age 前加两个下划线,将其变成一个私有变量。外界就无法随随便便就知道某个人年龄啦。
如此一来,想要知道一个人是否是成年人,该怎么办呢?
这时候,就该 封装 出场啦。
我可以定义一个用于专门判断一个人是否成年人的函数,对 self.__age 这个属性进行封装。
1 | |
7.5 【基础】类的继承(Inheritance)
类的继承,跟人类繁衍的关系相似。
被继承的类称为基类(也叫做父类),继承而得的类叫派生类(也叫子类),这种关系就像人类的父子关系。
继承最大的好处是子类获得了父类的全部变量和方法的同时,又可以根据需要进行修改、拓展。
继承的语法结构是
1 | |
1. 单继承
举个例子:下面的代码中。先是定义了一个 People 类,里面有一个 speak 方法。然后再定义一个 Student 类,并继承自 People 类。
1 | |
由于继承的机制,Student 实例会拥有 People 类所有属性和方法,比如下边我可以直接调用 People 类的 speak 方法。
1 | |
你如果不想使用父类的方法,你可以重写它以覆盖父类的 speak 方法。
1 | |
此时,再调用的话,就会调用自己的方法了
1 | |
2. 多继承
Python 还支持多继承,可以继承自多个类。
1 | |
多继承的话,情况会比单继承复杂得多。
假设多个父类都有一个 foo 方法,并且子类没有重写 foo 方法,那么 子类 的实例在调用 foo 方法时,应该使用哪个父类的 foo 方法呢?
关于这一点,只要简单的做个验证就行啦。
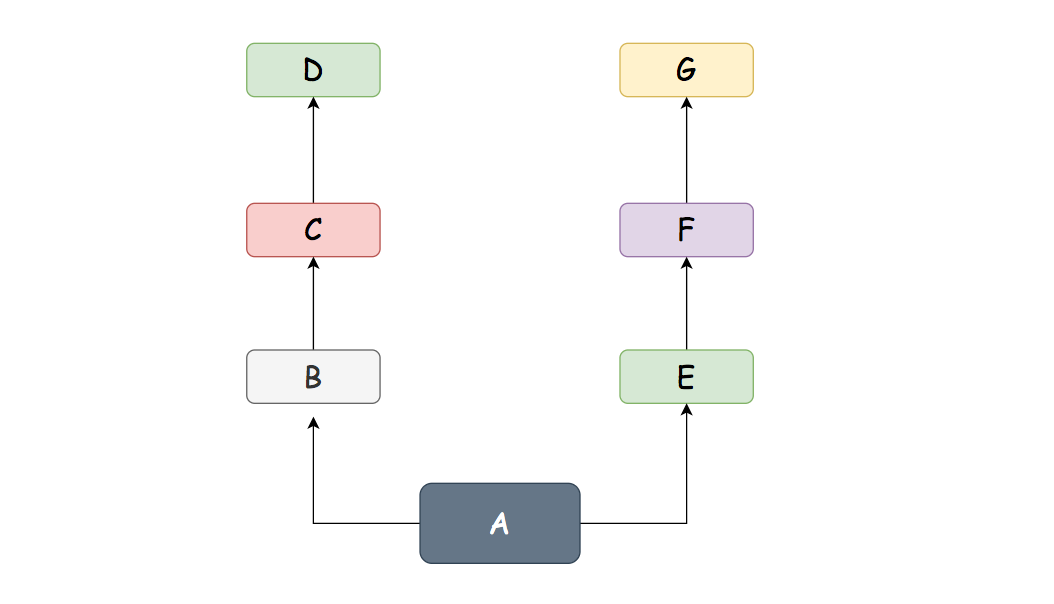
有如下代码,定义了 7 个类
1 | |
它们的继承关系是
运行后的结果如下
1 | |
在类A中,没有show()这个方法,于是它只能去它的父类里查找,它首先在B类中找,结果找到了,于是直接执行B类的show()方法。可见,在A的定义中,继承参数的书写有先后顺序,写在前面的被优先继承。
3. 继承顺序
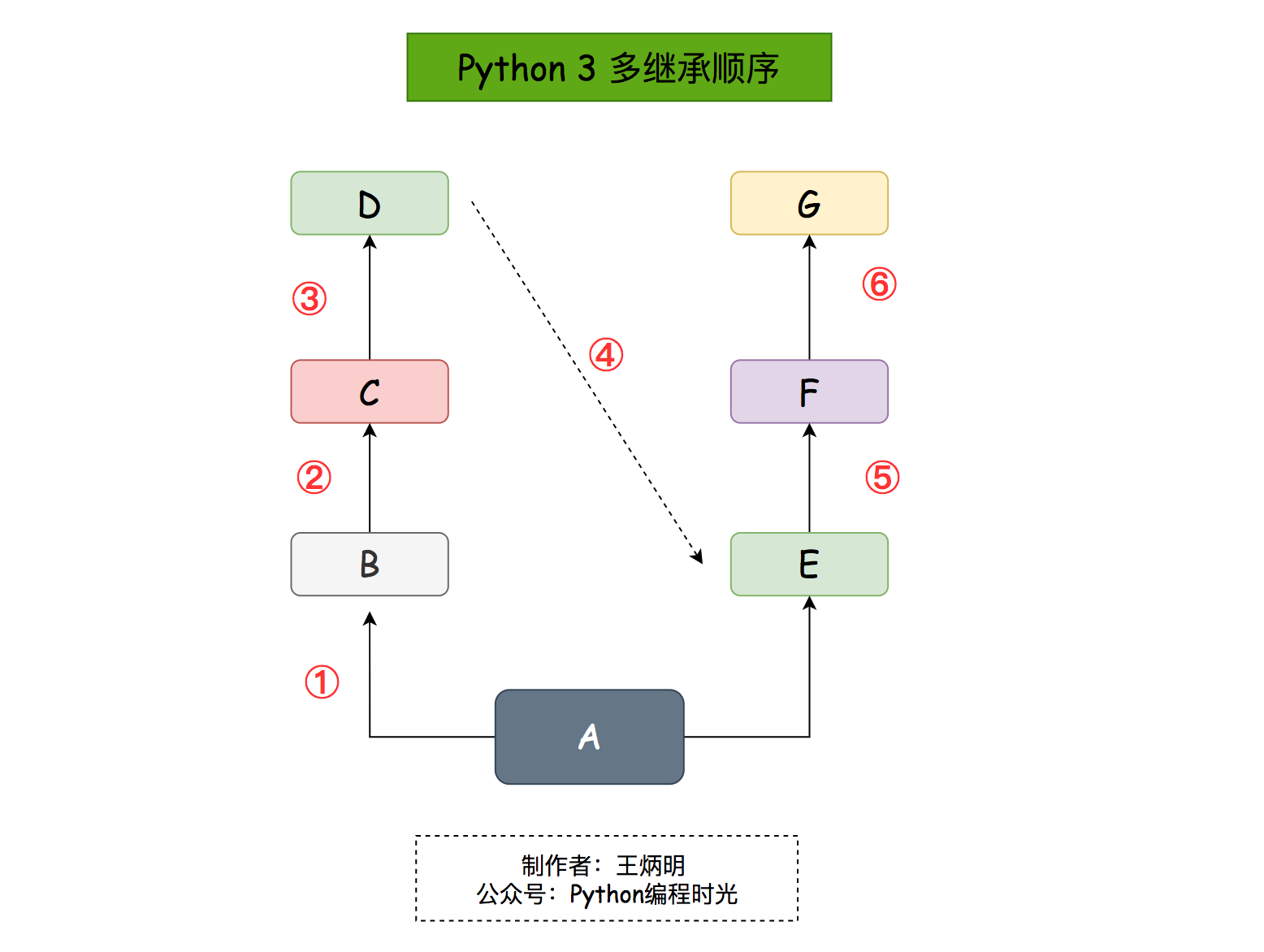
那如果B没有show方法,而是D有呢?
1 | |
执行结果是
1 | |
由此可见,多继承的顺序使用的是从左向右再深度优先的原则。
4. MRO 算法
上面的继承案例是只是非常简单的一种场景,在实际应用中,会远比这个来得复杂。
此时如果你单纯的将其理解成
- 从左向右
- 深度优先
就会发现很场景下想要理清的方法解析顺序(MRO)是非常难的。
在这种情况下,你还可以有两种方法:
- 使用
__mro__来查询 - 使用 merge算法进行推导
使用 mro 查询
比如在下面这个菱形继承中
1 | |
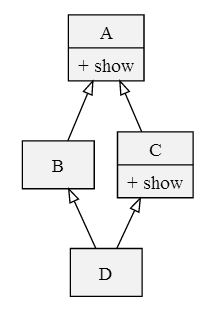
可以使用 __mro__
1 | |
或者借助 inspect 模块
1 | |
得到的结果都将是
1 | |
使用 merge 推导
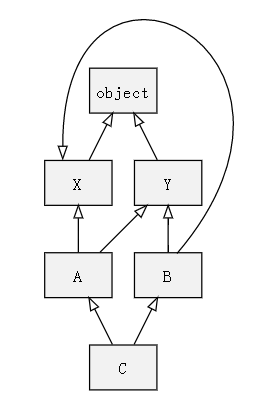
- 检查第一个列表的头元素(如 L[B1] 的头),记作 H。
- 若 H 未出现在其它列表的尾部,则将其输出,并将其从所有列表中删除,然后回到步骤1;否则,取出下一个列表的头部记作 H,继续该步骤。
- 重复上述步骤,直至列表为空或者不能再找出可以输出的元素。如果是前一种情况,则算法结束;如果是后一种情况,说明无法构建继承关系,Python 会抛出异常。
你可以在草稿纸上,参照上面的merge算法,写出如下过程
1 | |
附录:参考文章
- https://www.python.org/download/releases/2.3/mro/
- https://www.cnblogs.com/whatisfantasy/p/6046991.html
7.6 【基础】类的多态(Polymorphism)
多态,是指在同一类型下的不同形态。
比如下面这段代码
1 | |
American 和 Chinese 都继承了 People 类,但他们在 speak() 函数下,却有不同的形态表现。American 说英文,Chinese 说汉语。
倘若现在有一个 do_speak 函数
1 | |
那么无论传入的 American 实例还是 Chinese 实例,只要他有实现 speak 方法都可以。
这就是 Python 中非常有名鸭子类型:一个对象只要“看起来像鸭子,走起路来像鸭子”,那它就可以被看做是鸭子。
套入刚刚的代码实例中,就是一个对象,只要有 speak 方法,那么他就是一个 do_speak 方法所需要的 people 对象。
可能有人会觉得,这些内容很自然啊,没什么不好理解,不觉得多态有什么特殊,Python就是这样啊!
如果你学过 JAVA 这一类强类型静态语言,就不会这么觉得了,对于JAVA,必须指定函数参数的数据类型,只能传递对应参数类型或其子类型的参数,不能传递其它类型的参数,show_kind()函数只能接收animal、dog、cat和pig类型,而不能接收job类型。就算接收dog、cat和pig类型,也是通过面向对象的多态机制实现的。## 7.7 【基础】类的 property 属性
在之前的学习中,对象的属性,我们都是通过把变量值赋值给对象本身来实现的。
1 | |
直接赋值会存在一个问题,就是无法对属性值进行合法性较验,比如我给 age 赋值的是负数,在业务上这种数据是不合法的。但上面那种写法是无法检查出来的。
1 | |
为了实现属性的合法性校验,Python 引入的 property 属性。
请看下面这段代码
1 | |
此时再对 age 属性进行赋值就会对 value 的值进行合法性检查,小于 0 或者 大于 150 的都是不合法数据。
1 | |
由此我们知道了 property ,其实是 Python 中一个内置的装饰器,它可以在新式类中把一个函数 改造 成属性。
当你读取属性值时,会进入被
property装饰的函数。当你对属性进行赋值时,会进入被
@xx.setter装饰的函数。两个装饰器,一定是
@property在前面,而@xx.setter在后
7.8 【进阶】类的 Mixin 设计模式
类的单继承,是开发者再熟悉不过的继承方式,写起来也毫不费力。
而多继承呢,见得很多,写得很少。在很多的项目代码里,你还会见到一种很奇怪的类,他们有一个命名上的共同点,就是在类名的结尾,都喜欢用 Mixin。
1. 认识Mixin模式
那我们今天就来讲讲这个 Mixin,对于这个Mixin,如何理解?它其实是一种设计模式,如果开发者之间没有产生这样一种设计模式的共识,那么设计模式将不复存在。
为了让大家,对这个 Mixin 有一个更直观的理解,我摘录了网上一段说明。
继承是一个”is-a”关系。比如轿车类继承交通工具类,因为轿车是一个(“is-a”)交通工具。一个物品不可能是多种不同的东西,因此就不应该存在多重继承。不过有没有这种情况,一个类的确是需要继承多个类呢?
答案是有,我们还是拿交通工具来举例子,民航飞机是一种交通工具,对于土豪们来说直升机也是一种交通工具。对于这两种交通工具,它们都有一个功能是飞行,但是轿车没有。所以,我们不可能将飞行功能写在交通工具这个父类中。但是如果民航飞机和直升机都各自写自己的飞行方法,又违背了代码尽可能重用的原则(如果以后飞行工具越来越多,那会出现许多重复代码)。
怎么办,那就只好让这两种飞机同时继承交通工具以及飞行器两个父类,这样就出现了多重继承。这时又违背了继承必须是”is-a”关系。这个难题该怎么破?
这时候 Mixin 就闪亮登场了。飞行只是飞机做为交通工具的一种(增强)属性,我们可以为这个飞行的功能单独定义一个(增强)类,称之为 Mixin 类。这个类,是做为增强功能,添加到子类中的。为了让其他开发者,一看就知道这是个 Mixin 类,一般都要求开发者遵循规范,在类名末尾加上 Mixin 。
举个例子
1 | |
使用Mixin类实现多重继承要遵循以下几个规范
- 责任明确:必须表示某一种功能,而不是某个物品;
- 功能单一:若有多个功能,那就写多个Mixin类;
- 绝对独立:不能依赖于子类的实现;子类即便没有继承这个Mixin类,也照样可以工作,就是缺少了某个功能。
2. 不使用Mixin的弊端
你肯定会问,不使用 Mixin 行吗?
当然可以,这个问题就像在问,我不遵循 PEP8 代码规范行吗?完全没问题,只是不推荐那样做。
那么到底有什么理由,让我们要去用到 Mixin 设计模式呢?
不使用的话,大概有如下三点弊端:
1、结构复杂
单继承中一个类的父类是什么,父类的父类是什么非常明确。多继承一个类有多个父类,父类又有多个父类,继承关系复杂。
2、优先顺序模糊
多个父类中有同名方法,在开发过程中,容易造成思维混乱,子类不知道继承哪个父类,会增加开发难度。关于子类的继承顺序,有一个比较复杂的 C3 算法,如果你还不清楚,可以点击我的另一篇文章 ,了解一下。
3、功能冲突
多重继承有多个父类,但是子类只能继承一个,对于同名方法,就会导致另一个父类的方法失效。
7.9 【进阶】类的魔术方法(超全整理)
什么是魔法方法呢?它们在面向对象的Python的处处皆是。
它们是一些可以让你对类添加魔法的特殊方法。它们经常是两个下划线包围来命名的(比如 __init__ , __lt__ )。
本文整理自: (译)Python魔法方法指南,内容非常多,不适合新手全文阅读,如果你是跟着教程从头看到这的,建议先跳过本文内容。而如果你是一名有经验的 Python 老手,可以考虑全文通读,会加深你对 Python 魔法方法的理解。
01. 构造方法
我们最为熟知的基本的魔法方法就是 __init__ ,我们可以用它来指明一个对象初始化的行为。然而,当我们调用 x = SomeClass() 的时候, __init__ 并不是第一个被调用的方法。事实上,第一个被调用的是 __new__ ,这个 方法才真正地创建了实例。当这个对象的生命周期结束的时候, __del__ 会被调用。让我们近一步理解这三个方法:
__new__(cls,[…)__new__是对象实例化时第一个调用的方法,它只取下 cls 参数,并把其他参数传给__init__。__new__很少使用,但是也有它适合的场景,尤其是当类继承自一个像元组或者字符串这样不经常改变的类型的时候。我不打算深入讨论__new__,因为它并不是很有用, Python文档 中 有详细的说明。__init__(self,[…])类的初始化方法。它获取任何传给构造器的参数(比如我们调用 x = SomeClass(10, ‘foo’) ,
__init__就会接到参数 10 和 ‘foo’ 。__init__在Python的类定义中用的最多。__del__(self)__new__和__init__是对象的构造器,__del__是对象的销毁器。它并非实现了语句 del x (因此该语句不等同于 x.__del__()。而是定义了当对象被垃圾回收时的行为。当对象需要在销毁时做一些处理的时候这个方法很有用,比如 socket 对象、文件对象。但是需要注意的是,当Python解释器退出但对象仍然存活的时候,__del__并不会 执行。所以养成一个手工清理的好习惯是很重要的,比如及时关闭连接。
这里有个 __init__ 和 __del__ 的例子:
1 | |
02. 操作符
使用Python魔法方法的一个巨大优势就是可以构建一个拥有Python内置类型行为的对象。这意味着你可以避免使用非标准的、丑陋的方式来表达简单的操作。在一些语言中,这样做很常见:
1 | |
你当然可以在Python也这么做,但是这样做让代码变得冗长而混乱。不同的类库可能对同一种比较操作采用不同的方法名称,这让使用者需要做很多没有必要的工作。运用魔法方法的魔力,我们可以定义方法 __eq__
1 | |
这是魔法力量的一部分,这样我们就可以创建一个像内建类型那样的对象了!
2.1 比较操作符
Python包含了一系列的魔法方法,用于实现对象之间直接比较,而不需要采用方法调用。同样也可以重载Python默认的比较方法,改变它们的行为。下面是这些方法的列表:
__cmp__(self, other)__cmp__是所有比较魔法方法中最基础的一个,它实际上定义了所有比较操作符的行为(<,==,!=,等等),但是它可能不能按照你需要的方式工作(例如,判断一个实例和另一个实例是否相等采用一套标准,而与判断一个实例是否大于另一实例采用另一套)。__cmp__应该在 self < other 时返回一个负整数,在 self == other 时返回0,在 self > other 时返回正整数。最好只定义你所需要的比较形式,而不是一次定义全部。如果你需要实现所有的比较形式,而且它们的判断标准类似,那么__cmp__是一个很好的方法,可以减少代码重复,让代码更简洁。__eq__(self, other)定义等于操作符(==)的行为。
__ne__(self, other)定义不等于操作符(!=)的行为。
__lt__(self, other)定义小于操作符(<)的行为。
__gt__(self, other)定义大于操作符(>)的行为。
__le__(self, other)定义小于等于操作符(<)的行为。
__ge__(self, other)定义大于等于操作符(>)的行为。
举个例子,假如我们想用一个类来存储单词。我们可能想按照字典序(字母顺序)来比较单词,字符串的默认比较行为就是这样。我们可能也想按照其他规则来比较字符串,像是长度,或者音节的数量。在这个例子中,我们使用长度作为比较标准,下面是一种实现:
1 | |
现在我们可以创建两个 Word 对象( Word(‘foo’) 和 Word(‘bar’))然后根据长度来比较它们。注意我们没有定义 __eq__ 和 __ne__ ,这是因为有时候它们会导致奇怪的结果(很明显, Word(‘foo’) == Word(‘bar’) 得到的结果会是true)。根据长度测试是否相等毫无意义,所以我们使用 str 的实现来比较相等。
从上面可以看到,不需要实现所有的比较魔法方法,就可以使用丰富的比较操作。标准库还在 functools 模块中提供了一个类装饰器,只要我们定义 __eq__ 和另外一个操作符( __gt__, __lt__ 等),它就可以帮我们实现比较方法。这个特性只在 Python 2.7 中可用。当它可用时,它能帮助我们节省大量的时间和精力。要使用它,只需要它 @total_ordering 放在类的定义之上就可以了
2.2 数值操作符
就像你可以使用比较操作符来比较类的实例,你也可以定义数值操作符的行为。固定好你的安全带,这样的操作符真的有很多。看在组织的份上,我把它们分成了五类:一元操作符,常见算数操作符,反射算数操作符(后面会涉及更多),增强赋值操作符,和类型转换操作符。
一元操作符
一元操作符只有一个操作符。
__pos__(self)实现取正操作,例如 +some_object。
__neg_(self)实现取负操作,例如 -some_object。
__abs__(self)实现内建绝对值函数 abs() 操作。
__invert__(self)实现取反操作符 ~。
__round__(self, n)实现内建函数 round() ,n 是近似小数点的位数。
__floor__(self)实现 math.floor() 函数,即向下取整。
__ceil__(self)实现 math.ceil() 函数,即向上取整。
__trunc__(self)实现 math.trunc() 函数,即截断整数。
常见算数操作符
现在,我们来看看常见的二元操作符(和一些函数),像+,-,*之类的,它们很容易从字面意思理解。
__add__(self, other)实现加法操作。
__sub__(self, other)实现减法操作。
__mul__(self, other)实现乘法操作。
__floordiv__(self, other)实现使用 // 操作符的整数除法。
__div__(self, other)实现使用 / 操作符的除法。
__truediv__(self, other)实现 true 除法,这个函数只有使用
from __future__ import division时才有作用。__mod__(self, other)实现 % 取余操作。
__divmod__(self, other)实现 divmod 内建函数。
__pow__(self)实现 ** 操作符。
__lshift__(self, other)实现左移位运算符 << 。
__rshift__(self, other)实现右移位运算符 >> 。
__and__(self, other)实现按位与运算符 & 。
__or__(self, other)实现按位或运算符 | 。
__xor__(self, other)实现按位异或运算符 ^ 。
反射算数运算符
还记得刚才我说会谈到反射运算符吗?可能你会觉得它是什么高端霸气上档次的概念,其实这东西挺简单的,下面举个例子:
1 | |
这是“常见”的加法,反射是一样的意思,只不过是运算符交换了一下位置:
1 | |
所有反射运算符魔法方法和它们的常见版本做的工作相同,只不过是处理交换连个操作数之后的情况。绝大多数情况下,反射运算和正常顺序产生的结果是相同的,所以很可能你定义 __radd__ 时只是调用一下 __add__。注意一点,操作符左侧的对象(也就是上面的 other )一定不要定义(或者产生 NotImplemented 异常) 操作符的非反射版本。例如,在上面的例子中,只有当 other 没有定义 __add__ 时 some_object.__radd__ 才会被调用。
__radd__(self, other)实现反射加法操作。
__rsub__(self, other)实现反射减法操作。
__rmul__(self, other)实现反射乘法操作。
__rfloordiv__(self, other)实现使用 // 操作符的整数反射除法。
__rdiv__(self, other)实现使用 / 操作符的反射除法。
__rtruediv__(self, other)实现 true 反射除法,这个函数只有使用
from __future__ import division时才有作用。__rmod__(self, other)实现 % 反射取余操作符。
__rdivmod__(self, other)实现调用 divmod(other, self) 时 divmod 内建函数的操作。
__rpow__(self)实现 ** 反射操作符。
__rlshift__(self, other)实现反射左移位运算符 << 的作用。
__rshift__(self, other)实现反射右移位运算符 >> 的作用。
__rand__(self, other)实现反射按位与运算符 & 。
__ror__(self, other)实现反射按位或运算符 | 。
__rxor__(self, other)实现反射按位异或运算符 ^ 。
增强赋值运算符
Python同样提供了大量的魔法方法,可以用来自定义增强赋值操作的行为。或许你已经了解增强赋值,它融合了“常见”的操作符和赋值操作,如果你还是没听明白,看下面的例子:
1 | |
这些方法都应该返回左侧操作数应该被赋予的值(例如, a += b __iadd__ 也许会返回 a + b ,这个结果会被赋给 a ),下面是方法列表:
__iadd__(self, other)实现加法赋值操作。
__isub__(self, other)实现减法赋值操作。
__imul__(self, other)实现乘法赋值操作。
__ifloordiv__(self, other)实现使用 //= 操作符的整数除法赋值操作。
__idiv__(self, other)实现使用 /= 操作符的除法赋值操作。
__itruediv__(self, other)实现 true 除法赋值操作,这个函数只有使用
from __future__ import division时才有作用。__imod__(self, other)实现 %= 取余赋值操作。
__ipow__(self)实现 **= 操作。
__ilshift__(self, other)实现左移位赋值运算符 <<= 。
__irshift__(self, other)实现右移位赋值运算符 >>= 。
__iand__(self, other)实现按位与运算符 &= 。
__ior__(self, other)实现按位或赋值运算符 | 。
__ixor__(self, other)实现按位异或赋值运算符 ^= 。
类型转换操作符
Python也有一系列的魔法方法用于实现类似 float() 的内建类型转换函数的操作。它们是这些:
__int__(self)实现到int的类型转换。
__long__(self)实现到long的类型转换。
__float__(self)实现到float的类型转换。
__complex__(self)实现到complex的类型转换。
__oct__(self)实现到八进制数的类型转换。
__hex__(self)实现到十六进制数的类型转换。
__index__(self)实现当对象用于切片表达式时到一个整数的类型转换。如果你定义了一个可能会用于切片操作的数值类型,你应该定义
__index__。__trunc__(self)当调用 math.trunc(self) 时调用该方法,
__trunc__应该返回 self 截取到一个整数类型(通常是long类型)的值。__coerce__(self)该方法用于实现混合模式算数运算,如果不能进行类型转换,
__coerce__应该返回 None 。反之,它应该返回一个二元组 self 和 other ,这两者均已被转换成相同的类型。
03. 类的表示
使用字符串来表示类是一个相当有用的特性。在Python中有一些内建方法可以返回类的表示,相对应的,也有一系列魔法方法可以用来自定义在使用这些内建函数时类的行为。
__str__(self)定义对类的实例调用 str() 时的行为。
__repr__(self)定义对类的实例调用 repr() 时的行为。str() 和 repr() 最主要的差别在于“目标用户”。repr() 的作用是产生机器可读的输出(大部分情况下,其输出可以作为有效的Python代码),而 str() 则产生人类可读的输出。
__unicode__(self)定义对类的实例调用 unicode() 时的行为。unicode() 和 str() 很像,只是它返回unicode字符串。注意,如果调用者试图调用 str() 而你的类只实现了
__unicode__() ,那么类将不能正常工作。所有你应该总是定义__str__() ,以防有些人没有闲情雅致来使用unicode。__format__(self)定义当类的实例用于新式字符串格式化时的行为,例如, “Hello, 0:abc!”.format(a) 会导致调用
a.__format__("abc")。当定义你自己的数值类型或字符串类型时,你可能想提供某些特殊的格式化选项,这种情况下这个魔法方法会非常有用。__hash__(self)定义对类的实例调用 hash() 时的行为。它必须返回一个整数,其结果会被用于字典中键的快速比较。同时注意一点,实现这个魔法方法通常也需要实现
__eq__,并且遵守如下的规则:a == b 意味着 hash(a) == hash(b)。__nonzero__(self)定义对类的实例调用 bool() 时的行为,根据你自己对类的设计,针对不同的实例,这个魔法方法应该相应地返回True或False。
__dir__(self)定义对类的实例调用 dir() 时的行为,这个方法应该向调用者返回一个属性列表。一般来说,没必要自己实现
__dir__。但是如果你重定义了__getattr__或者__getattribute__(下个部分会介绍),乃至使用动态生成的属性,以实现类的交互式使用,那么这个魔法方法是必不可少的。
到这里,我们基本上已经结束了魔法方法指南中无聊并且例子匮乏的部分。既然我们已经介绍了较为基础的魔法方法,是时候涉及更高级的内容了。
04. 访问控制
很多从其他语言转向Python的人都抱怨Python的类缺少真正意义上的封装(即没办法定义私有属性然后使用公有的getter和setter)。然而事实并非如此。实际上Python不是通过显式定义的字段和方法修改器,而是通过魔法方法实现了一系列的封装。
__getattr__(self, name)
当用户试图访问一个根本不存在(或者暂时不存在)的属性时,你可以通过这个魔法方法来定义类的行为。这个可以用于捕捉错误的拼写并且给出指引,使用废弃属性时给出警告(如果你愿意,仍然可以计算并且返回该属性),以及灵活地处理AttributeError。只有当试图访问不存在的属性时它才会被调用,所以这不能算是一个真正的封装的办法。
__setattr__(self, name, value)
和 __getattr__ 不同, __setattr__ 可以用于真正意义上的封装。它允许你自定义某个属性的赋值行为,不管这个属性存在与否,也就是说你可以对任意属性的任何变化都定义自己的规则。然后,一定要小心使用 __setattr__ ,这个列表最后的例子中会有所展示。
__delattr__(self, name)
这个魔法方法和 __setattr__几乎相同,只不过它是用于处理删除属性时的行为。和 _setattr__ 一样,使用它时也需要多加小心,防止产生无限递归(在 __delattr__ 的实现中调用 del self.name 会导致无限递归)。
__getattribute__(self, name)
__getattribute__ 看起来和上面那些方法很合得来,但是最好不要使用它。__getattribute__ 只能用于新式类。在最新版的Python中所有的类都是新式类,在老版Python中你可以通过继承 object 来创建新式类。__getattribute__ 允许你自定义属性被访问时的行为,它也同样可能遇到无限递归问题(通过调用基类的 __getattribute__ 来避免)。__getattribute__ 基本上可以替代 __getattr__ 。只有当它被实现,并且显式地被调用,或者产生 AttributeError 时它才被使用。这个魔法方法可以被使用(毕竟,选择权在你自己),我不推荐你使用它,因为它的使用范围相对有限(通常我们想要在赋值时进行特殊操作,而不是取值时),而且实现这个方法很容易出现Bug。
自定义这些控制属性访问的魔法方法很容易导致问题,考虑下面这个例子:
1 | |
再次重申,Python的魔法方法十分强大,能力越强责任越大,了解如何正确的使用魔法方法更加重要。
到这里,我们对Python中自定义属性存取控制有了什么样的印象?它并不适合轻度的使用。实际上,它有些过分强大,而且违反直觉。然而它之所以存在,是因为一个更大的原则:Python不指望让杜绝坏事发生,而是想办法让做坏事变得困难。自由是至高无上的权利,你真的可以随心所欲。下面的例子展示了实际应用中某些特殊的属性访问方法(注意我们之所以使用 super 是因为不是所有的类都有 __dict__ 属性):
1 | |
05. 自定义序列
有许多办法可以让你的Python类表现得像是内建序列类型(字典,元组,列表,字符串等)。这些魔法方式是目前为止我最喜欢的。它们给了你难以置信的控制能力,可以让你的类与一系列的全局函数完美结合。在了解激动人心的内容之前,首先你需要掌握一些预备知识。
既然讲到创建自己的序列类型,就不得不说一说协议了。协议类似某些语言中的接口,里面包含的是一些必须实现的方法。在Python中,协议完全是非正式的,也不需要显式的声明,事实上,它们更像是一种参考标准。
为什么我们要讲协议?因为在Python中实现自定义容器类型需要用到一些协议。首先,不可变容器类型有如下协议:想实现一个不可变容器,你需要定义 __len__ 和 __getitem__ (后面会具体说明)。可变容器的协议除了上面提到的两个方法之外,还需要定义 __setitem__ 和 __delitem__ 。最后,如果你想让你的对象可以迭代,你需要定义 __iter__ ,这个方法返回一个迭代器。迭代器必须遵守迭代器协议,需要定义 __iter__ (返回它自己)和 next 方法。
5.1 容器背后的魔法方法
__len__(self)返回容器的长度,可变和不可变类型都需要实现。
__getitem__(self, key)定义对容器中某一项使用 self[key] 的方式进行读取操作时的行为。这也是可变和不可变容器类型都需要实现的一个方法。它应该在键的类型错误式产生 TypeError 异常,同时在没有与键值相匹配的内容时产生 KeyError 异常。
__setitem__(self, key)定义对容器中某一项使用 self[key] 的方式进行赋值操作时的行为。它是可变容器类型必须实现的一个方法,同样应该在合适的时候产生 KeyError 和 TypeError 异常。
__iter__(self, key)它应该返回当前容器的一个迭代器。迭代器以一连串内容的形式返回,最常见的是使用 iter() 函数调用,以及在类似 for x in container: 的循环中被调用。迭代器是他们自己的对象,需要定义
__iter__方法并在其中返回自己。__reversed__(self)定义了对容器使用 reversed() 内建函数时的行为。它应该返回一个反转之后的序列。当你的序列类是有序时,类似列表和元组,再实现这个方法,
__contains__(self, item)__contains__定义了使用 in 和 not in 进行成员测试时类的行为。你可能好奇为什么这个方法不是序列协议的一部分,原因是,如果__contains__没有定义,Python就会迭代整个序列,如果找到了需要的一项就返回 True 。__missing__(self ,key)__missing__在字典的子类中使用,它定义了当试图访问一个字典中不存在的键时的行为(目前为止是指字典的实例,例如我有一个字典 d , “george” 不是字典中的一个键,当试图访问 d[“george’] 时就会调用 d.__missing__(“george”) )。
5.2 一个例子
让我们来看一个实现了一些函数式结构的列表,可能在其他语言中这种结构更常见(例如Haskell):
1 | |
就是这些,一个(微不足道的)有用的例子,向你展示了如何实现自己的序列。当然啦,自定义序列有更大的用处,而且绝大部分都在标准库中实现了(Python是自带电池的,记得吗?),像 Counter , OrderedDict 和 NamedTuple 。
06. 反射
你可以通过定义魔法方法来控制用于反射的内建函数 isinstance 和 issubclass 的行为。下面是对应的魔法方法:
__instancecheck__(self, instance)检查一个实例是否是你定义的类的一个实例(例如 isinstance(instance, class) )。
__subclasscheck__(self, subclass)检查一个类是否是你定义的类的子类(例如 issubclass(subclass, class) )。
这几个魔法方法的适用范围看起来有些窄,事实也正是如此。我不会在反射魔法方法上花费太多时间,因为相比其他魔法方法它们显得不是很重要。但是它们展示了在Python中进行面向对象编程(或者总体上使用Python进行编程)时很重要的一点:不管做什么事情,都会有一个简单方法,不管它常用不常用。这些魔法方法可能看起来没那么有用,但是当你真正需要用到它们的时候,你会感到很幸运,因为它们还在那儿(也因为你阅读了这本指南!)
07. 抽象基类
请参考 http://docs.python.org/2/library/abc.html
08. 可调用的对象
你可能已经知道了,在Python中,函数是一等的对象。这意味着它们可以像其他任何对象一样被传递到函数和方法中,这是一个十分强大的特性。
Python中一个特殊的魔法方法允许你自己类的对象表现得像是函数,然后你就可以“调用”它们,把它们传递到使用函数做参数的函数中,等等等等。这是另一个强大而且方便的特性,让使用Python编程变得更加幸福。
__call__(self, [args…])允许类的一个实例像函数那样被调用。本质上这代表了 x() 和 x.
__call__() 是相同的。注意__call__可以有多个参数,这代表你可以像定义其他任何函数一样,定义__call__,喜欢用多少参数就用多少。
__call__ 在某些需要经常改变状态的类的实例中显得特别有用。“调用”这个实例来改变它的状态,是一种更加符合直觉,也更加优雅的方法。一个表示平面上实体的类是一个不错的例子:
1 | |
09. 上下文管理器
在Python 2.5中引入了一个全新的关键词,随之而来的是一种新的代码复用方法—— with 声明。上下文管理的概念在Python中并不是全新引入的(之前它作为标准库的一部分实现),直到PEP 343被接受,它才成为一种一级的语言结构。可能你已经见过这种写法了:
1 | |
当对象使用 with 声明创建时,上下文管理器允许类做一些设置和清理工作。上下文管理器的行为由下面两个魔法方法所定义:
__enter__(self)定义使用 with 声明创建的语句块最开始上下文管理器应该做些什么。注意
__enter__的返回值会赋给 with 声明的目标,也就是 as 之后的东西。__exit__(self, exception_type, exception_value, traceback)定义当 with 声明语句块执行完毕(或终止)时上下文管理器的行为。它可以用来处理异常,进行清理,或者做其他应该在语句块结束之后立刻执行的工作。如果语句块顺利执行, exception_type , exception_value 和 traceback 会是 None 。否则,你可以选择处理这个异常或者让用户来处理。如果你想处理异常,确保
__exit__在完成工作之后返回 True 。如果你不想处理异常,那就让它发生吧。
对一些具有良好定义的且通用的设置和清理行为的类,__enter__ 和 __exit__会显得特别有用。你也可以使用这几个方法来创建通用的上下文管理器,用来包装其他对象。下面是一个例子:
1 | |
这是一个 Closer 在实际使用中的例子,使用一个FTP连接来演示(一个可关闭的socket):
1 | |
看到我们的包装器是如何同时优雅地处理正确和不正确的调用了吗?这就是上下文管理器和魔法方法的力量。Python标准库包含一个 contextlib 模块,里面有一个上下文管理器 contextlib.closing() 基本上和我们的包装器完成的是同样的事情(但是没有包含任何当对象没有close()方法时的处理)。
10. 创建描述符对象
描述符是一个类,当使用取值,赋值和删除 时它可以改变其他对象。描述符不是用来单独使用的,它们需要被一个拥有者类所包含。描述符可以用来创建面向对象数据库,以及创建某些属性之间互相依赖的类。描述符在表现具有不同单位的属性,或者需要计算的属性时显得特别有用(例如表现一个坐标系中的点的类,其中的距离原点的距离这种属性)。
要想成为一个描述符,一个类必须具有实现 __get__ , __set__ 和 __delete__ 三个方法中至少一个。
让我们一起来看一看这些魔法方法:
__get__(self, instance, owner)定义当试图取出描述符的值时的行为。instance 是拥有者类的实例, owner 是拥有者类本身。
__set__(self, instance, owner)定义当描述符的值改变时的行为。instance 是拥有者类的实例, value 是要赋给描述符的值。
__delete__(self, instance, value)定义当描述符的值被删除时的行为。instance 是拥有者类的实例
现在,来看一个描述符的有效应用:单位转换:
1 | |
11. 拷贝
有些时候,特别是处理可变对象时,你可能想拷贝一个对象,改变这个对象而不影响原有的对象。这时就需要用到Python的 copy 模块了。然而(幸运的是),Python模块并不具有感知能力, 因此我们不用担心某天基于Linux的机器人崛起。但是我们的确需要告诉Python如何有效率地拷贝对象。
__copy__(self)定义对类的实例使用 copy.copy() 时的行为。copy.copy() 返回一个对象的浅拷贝,这意味着拷贝出的实例是全新的,然而里面的数据全都是引用的。也就是说,对象本身是拷贝的,但是它的数据还是引用的(所以浅拷贝中的数据更改会影响原对象)。
__deepcopy__(self, memodict=)定义对类的实例使用 copy.deepcopy() 时的行为。copy.deepcopy() 返回一个对象的深拷贝,这个对象和它的数据全都被拷贝了一份。memodict 是一个先前拷贝对象的缓存,它优化了拷贝过程,而且可以防止拷贝递归数据结构时产生无限递归。当你想深拷贝一个单独的属性时,在那个属性上调用 copy.deepcopy() ,使用 memodict 作为第一个参数。
这些魔法方法有什么用武之地呢?像往常一样,当你需要比默认行为更加精确的控制时。例如,如果你想拷贝一个对象,其中存储了一个字典作为缓存(可能会很大),拷贝缓存可能是没有意义的。如果这个缓存可以在内存中被不同实例共享,那么它就应该被共享。
12. Pickling
如果你和其他的Python爱好者共事过,很可能你已经听说过Pickling了。Pickling是Python数据结构的序列化过程,当你想存储一个对象稍后再取出读取时,Pickling会显得十分有用。然而它同样也是担忧和混淆的主要来源。
Pickling是如此的重要,以至于它不仅仅有自己的模块( pickle ),还有自己的协议和魔法方法。首先,我们先来简要的介绍一下如何pickle已存在的对象类型(如果你已经知道了,大可跳过这部分内容)。
12.1 小试牛刀
我们一起来pickle吧。假设你有一个字典,你想存储它,稍后再取出来。你可以把它的内容写入一个文件,小心翼翼地确保使用了正确地格式,要把它读取出来,你可以使用 exec() 或处理文件输入。但是这种方法并不可靠:如果你使用纯文本来存储重要数据,数据很容易以多种方式被破坏或者修改,导致你的程序崩溃,更糟糕的情况下,还可能在你的计算机上运行恶意代码。因此,我们要pickle它:
1 | |
过了几个小时,我们想把它取出来,我们只需要反pickle它:
1 | |
将会发生什么?正如你期待的,它就是我们之前的 data 。
现在,还需要谨慎地说一句:pickle并不完美。Pickle文件很容易因为事故或被故意的破坏掉。Pickling或许比纯文本文件安全一些,但是依然有可能被用来运行恶意代码。而且它还不支持跨Python版本,所以不要指望分发pickle对象之后所有人都能正确地读取。然而不管怎么样,它依然是一个强有力的工具,可以用于缓存和其他类型的持久化工作。
12.2 Pickle你的对象
Pickle不仅仅可以用于内建类型,任何遵守pickle协议的类都可以被pickle。Pickle协议有四个可选方法,可以让类自定义它们的行为(这和C语言扩展略有不同,那不在我们的讨论范围之内)。
__getinitargs__(self)如果你想让你的类在反pickle时调用
__init__,你可以定义__getinitargs__(self) ,它会返回一个参数元组,这个元组会传递给__init__。注意,这个方法只能用于旧式类。__getnewargs__(self)对新式类来说,你可以通过这个方法改变类在反pickle时传递给
__new__的参数。这个方法应该返回一个参数元组。__getstate__(self)你可以自定义对象被pickle时被存储的状态,而不使用对象的
__dict__属性。这个状态在对象被反pickle时会被__setstate__使用。__setstate__(self)当一个对象被反pickle时,如果定义了
__setstate__,对象的状态会传递给这个魔法方法,而不是直接应用到对象的__dict__属性。这个魔法方法和__getstate__相互依存:当这两个方法都被定义时,你可以在Pickle时使用任何方法保存对象的任何状态。__reduce__(self)当定义扩展类型时(也就是使用Python的C语言API实现的类型),如果你想pickle它们,你必须告诉Python如何pickle它们。reduce 被定义之后,当对象被Pickle时就会被调用。它要么返回一个代表全局名称的字符串,Pyhton会查找它并pickle,要么返回一个元组。这个元组包含2到5个元素,其中包括:一个可调用的对象,用于重建对象时调用;一个参数元素,供那个可调用对象使用;被传递给
__setstate__的状态(可选);一个产生被pickle的列表元素的迭代器(可选);一个产生被pickle的字典元素的迭代器(可选);__reduce_ex__(self)__reduce_ex__的存在是为了兼容性。如果它被定义,在pickle时__reduce_ex__会代替__reduce__被调用。__reduce__也可以被定义,用于不支持__reduce_ex__的旧版pickle的API调用。
12.3 一个例子
我们的例子是 Slate ,它会记住它的值曾经是什么,以及那些值是什么时候赋给它的。然而 每次被pickle时它都会变成空白,因为当前的值不会被存储:
1 | |
13. 总结在最后
这本指南的目标是使所有阅读它的人都能有所收获,无论他们有没有使用Python或者进行面向对象编程的经验。如果你刚刚开始学习Python,你会得到宝贵的基础知识,了解如何写出具有丰富特性的,优雅而且易用的类。如果你是中级的Python程序员,你或许能掌握一些新的概念和技巧,以及一些可以减少代码行数的好办法。如果你是专家级别的Python爱好者,你又重新复习了一遍某些可能已经忘掉的知识,也可能顺便了解了一些新技巧。无论你的水平怎样,我希望这趟遨游Python特殊方法的旅行,真的对你产生了魔法般的效果(实在忍不住不说最后这个双关)。
7.10 【进阶】神奇的元类编程(metaclass)
1. 类是如何产生的
类是如何产生?这个问题也许你会觉得很傻。
实则不然,很多初学者只知道使用继承的表面形式来创建一个类,却不知道其内部真正的创建是由 type 来创建的。
type?这不是判断对象类型的函数吗?
是的,type通常用法就是用来判断对象的类型。但除此之外,他最大的用途是用来动态创建类。当Python扫描到class的语法的时候,就会调用type函数进行类的创建。
2. 如何使用type创建类
首先,type() 需要接收三个参数
- 类的名称,若不指定,也要传入空字符串:
"" - 父类,注意以tuple的形式传入,若没有父类也要传入空tuple:
(),默认继承object - 绑定的方法或属性,注意以dict的形式传入
来看个例子
1 | |
3. 理解什么是元类
什么是类?可能谁都知道,类就是用来创建对象的「模板」。
那什么是元类呢?一句话通俗来说,元类就是创建类的「模板」。
为什么type能用来创建类?因为它本身是一个元类。使用元类创建类,那就合理了。
type是Python在背后用来创建所有类的元类,我们熟知的类的始祖 object 也是由type创建的。更有甚者,连type自己也是由type自己创建的,这就过份了。
1 | |
如果要形象的来理解的话,就看下面这三行话。
- str:用来创建字符串对象的类。
- int:是用来创建整数对象的类。
- type:是用来创建类对象的类。
反过来看
- 一个实例的类型,是类
- 一个类的类型,是元类
- 一个元类的类型,是type
写个简单的小示例来验证下
1 | |
下面再来看一个稍微完整的
1 | |
综上,我们知道了类是元类的实例,所以在创建一个普通类时,其实会走元类的 __new__。
同时,我们又知道在类里实现了 __call__ 就可以让这个类的实例变成可调用。
所以在我们对普通类进行实例化时,实际是对一个元类的实例(也就是普通类)进行直接调用,所以会走进元类的 __call__
在这里可以借助 「单例的实现」举一个例子,你就清楚了
1 | |
验证结果
1 | |
4. 使用元类的意义
正常情况下,我们都不会使用到元类。但是这并不意味着,它不重要。假如某一天,我们需要写一个框架,很有可能就需要你对元类要有进一步的研究。
元类有啥用,用我通俗的理解,元类的作用过程:
- 拦截类的创建
- 拦截下后,进行修改
- 修改完后,返回修改后的类
所以,很明显,为什么要用它呢?不要它会怎样?
使用元类,是要对类进行定制修改。使用元类来动态生成元类的实例,而99%的开发人员是不需要动态修改类的,因为这应该是框架才需要考虑的事。
但是,这样说,你一定不会服气,到底元类用来干什么?其实元类的作用就是创建API,一个最典型的应用是 Django ORM。
5. 元类实战:ORM
使用过Django ORM的人都知道,有了ORM,使得我们操作数据库,变得异常简单。
ORM的一个类(User),就对应数据库中的一张表。id,name,email,password 就是字段。
1 | |
如果我们要插入一条数据,我们只需这样做
1 | |
通常用户层面,只需要懂应用,就像上面这样操作就可以了。
但是今天我并不是来教大家如何使用ORM,我们是用来探究ORM内部究竟是如何实现的。我们也可以自己写一个简易的ORM。
从上面的User类中,我们看到StrField和IntField,从字段意思上看,我们很容易看出这代表两个字段类型。字段名分别是id,username,email,password。
StrField和IntField在这里的用法,叫做属性描述符。
简单来说呢,属性描述符可以实现对属性值的类型,范围等一切做约束,意思就是说变量id只能是int类型,变量name只能是str类型,否则将会抛出异常。
那如何实现这两个属性描述符呢?请看代码。
1 | |
我们看到User类继承自BaseModel,这个BaseModel里,定义了数据库操作的各种方法,譬如我们使用的save函数,也可以放在这里面的。所以我们就可以来写一下这个BaseModel类
1 | |
从BaseModel类中,save函数里面有几个新变量。
- fields: 存放所有的字段属性
- db_table:表名
我们思考一下这个u实例的创建过程:
type -> ModelMetaClass -> BaseModel -> User -> u
这里会有几个问题。
- init的参数是User实例时传入的,所以传入的id是int类型,name是str类型。看起来没啥问题,若是这样,我上面的数据描述符就失效了,不能起约束作用。所以我们希望init接收到的id是IntField类型,name是StrField类型。
- 同时,我们希望这些字段属性,能够自动归类到fields变量中。因为,做为BaseModel,它可不是专门为User类服务的,它还要兼容各种各样的表。不同的表,表里有不同数量,不同属性的字段,这些都要能自动类别并归类整理到一起。这是一个ORM框架最基本的。
- 我们希望对表名有两种选择,一个是User中若指定Meta信息,比如表名,就以此为表名,若未指定就以类名的小写 做为表名。虽然BaseModel可以直接取到User的db_table属性,但是如果在数据库业务逻辑中,加入这段复杂的逻辑,显然是很不优雅的。
上面这几个问题,其实都可以通过元类的__new__函数来完成。
下面就来看看,如何用元类来解决这些问题呢?请看代码。
1 | |
6. _new_ 有什么用?
在没有元类的情况下,每次创建实例,在先进入 __init__ 之前都会先进入 __new__。
1 | |
使用如下
1 | |
在有元类的情况下,每次创建类时,会都先进入 元类的 __new__ 方法,如果你要对类进行定制,可以在这时做一些手脚。
综上,元类的__new__和普通类的不一样:
- 元类的
__new__在创建类时就会进入,它可以获取到上层类的一切属性和方法,包括类名,魔法方法。 - 而普通类的
__new__在实例化时就会进入,它仅能获取到实例化时外界传入的属性。
附录:参考文章
7.11 【进阶】深藏不露的描述符(Descriptor)
在前几节里,有介绍过 property 的用法,property 实现将一系列函数改造成对象属性,并实现参数的访问检查。
很少有人会去深究这里面的原理究竟是什么?实际上对于大部分开发者而言,只要学会应用即可,无需深入探讨。
因此本节内容是 Python 的进阶知识点,若你是新手,请跳过此章节,否则会打击你的学习自信心。
打开天窗说亮话,实际上 property 的内部原理是 描述符 (Descriptor)
本篇都将带你全面的学习描述符,一起来感受 Python 语言的优雅。
1. 为什么要使用描述符?
假想你正在给学校写一个成绩管理系统,并没有太多编码经验的你,可能会这样子写。
1 | |
看起来一切都很合理
1 | |
但是程序并不像人那么智能,不会自动根据使用场景判断数据的合法性,如果老师在录入成绩的时候,不小心录入了将成绩录成了负数,或者超过100,程序是无法感知的。
聪明的你,马上在代码中加入了判断逻辑。
1 | |
这下程序稍微有点人工智能了,能够自己明辨是非了。
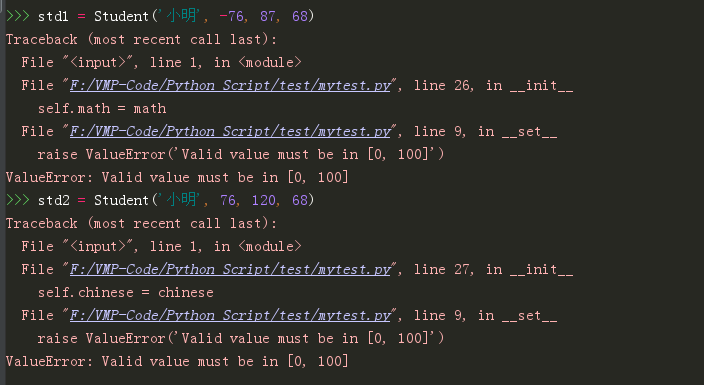
程序是智能了,但在__init__里有太多的判断逻辑,很影响代码的可读性。巧的是,你刚好学过 Property 特性,可以很好的应用在这里。于是你将代码修改成如下,代码的可读性瞬间提升了不少
1 | |
程序还是一样的人工智能,非常好。
你以为你写的代码,已经非常优秀,无懈可击了。
没想到,人外有天,你的主管看了你的代码后,深深地叹了口气:类里的三个属性,math、chinese、english,都使用了 Property 对属性的合法性进行了有效控制。功能上,没有问题,但就是太啰嗦了,三个变量的合法性逻辑都是一样的,只要大于0,小于100 就可以,代码重复率太高了,这里三个成绩还好,但假设还有地理、生物、历史、化学等十几门的成绩呢,这代码简直没法忍。去了解一下 Python 的描述符吧。
经过主管的指点,你知道了「描述符」这个东西。怀着一颗敬畏之心,你去搜索了下关于 描述符的用法。
其实也很简单,一个实现了 描述符协议 的类就是一个描述符。
什么描述符协议:在类里实现了 __get__()、__set__()、__delete__() 其中至少一个方法。
__get__: 用于访问属性。它返回属性的值,若属性不存在、不合法等都可以抛出对应的异常。__set__:将在属性分配操作中调用。不会返回任何内容。__delete__:控制删除操作。不会返回内容。
对描述符有了大概的了解后,你开始重写上面的方法。
如前所述,Score 类是一个描述符,当从 Student 的实例访问 math、chinese、english这三个属性的时候,都会经过 Score 类里的三个特殊的方法。这里的 Score 避免了 使用Property 出现大量的代码无法复用的尴尬。
1 | |
实现的效果和前面的一样,可以对数据的合法性进行有效控制(字段类型、数值区间等)
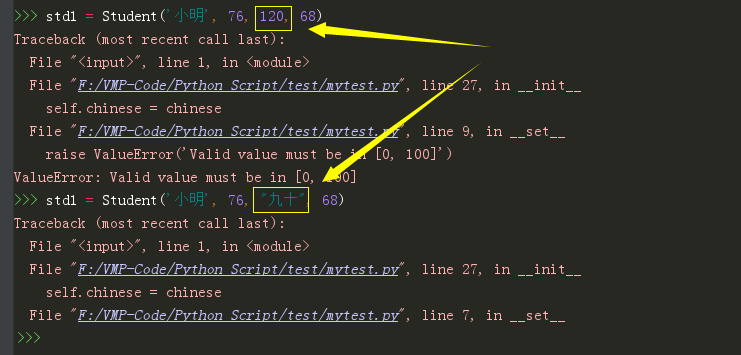
以上,我举了下具体的实例,从最原始的编码风格到 Property ,最后引出描述符。由浅入深,一步一步带你感受到描述符的优雅之处。
到这里,你需要记住的只有一点,就是描述符给我们带来的编码上的便利,它在实现 保护属性不受修改、属性类型检查 的基本功能,同时有大大提高代码的复用率。
2. 描述符的访问规则
描述符分两种:
- 数据描述符:实现了
__get__和__set__两种方法的描述符 - 非数据描述符:只实现了
__get__一种方法的描述符
你一定会问,他们有什么区别呢?网上的讲解,我看过几个,很多都把一个简单的东西讲得复杂了。
其实就一句话,数据描述器和非数据描述器的区别在于:它们相对于实例的字典的优先级不同。
如果实例字典中有与描述符同名的属性,如果描述符是数据描述符,优先使用数据描述符,如果是非数据描述符,优先使用字典中的属性。
这边还是以上节的成绩管理的例子来说明,方便你理解。
1 | |
需要注意的是,math 是数据描述符,而 chinese 是非数据描述符。从下面的验证中,可以看出,当实例属性和数据描述符同名时,会优先访问数据描述符(如下面的math),而当实例属性和非数据描述符同名时,会优先访问实例属性(__getattribute__)
1 | |
讲完了数据描述符和非数据描述符,我们还需要了解的对象属性的查找规律。
当我们对一个实例属性进行访问时,Python 会按 obj.__dict__ → type(obj).__dict__ → type(obj)的父类.__dict__ 顺序进行查找,如果查找到目标属性并发现是一个描述符,Python 会调用描述符协议来改变默认的控制行为。
3. 基于描述符如何实现property
经过上面的讲解,我们已经知道如何定义描述符,且明白了描述符是如何工作的。
正常人所见过的描述符的用法就是上面提到的那些,我想说的是那只是描述符协议最常见的应用之一,或许你还不知道,其实有很多 Python 的特性的底层实现机制都是基于 描述符协议 的,比如我们熟悉的@property 、@classmethod 、@staticmethod 和 super 等。
先来说说 property 吧。
有了前面的基础,我们知道了 property 的基本用法。这里我直接切入主题,从第一篇的例子里精简了一下。
1 | |
不防再简单回顾一下它的用法,通过property装饰的函数,如例子中的 math 会变成 Student 实例的属性。而对 math 属性赋值会进入 使用 math.setter 装饰函数的逻辑代码块。
为什么说 property 底层是基于描述符协议的呢?通过 PyCharm 点击进入 property 的源码,很可惜,只是一份类似文档一样的伪源码,并没有其具体的实现逻辑。
不过,从这份伪源码的魔法函数结构组成,可以大体知道其实现逻辑。
这里我自己通过模仿其函数结构,结合「描述符协议」来自己实现类 property 特性。
代码如下:
1 | |
然后 Student 类,我们也相应改成如下
1 | |
为了尽量让你少产生一点疑惑,我这里做两点说明:
使用
TestProperty装饰后,math不再是一个函数,而是TestProperty类的一个实例。所以第二个math函数可以使用math.setter来装饰,本质是调用TestProperty.setter来产生一个新的TestProperty实例赋值给第二个math。第一个
math和第二个math是两个不同TestProperty实例。但他们都属于同一个描述符类(TestProperty),当对 math 对于赋值时,就会进入TestProperty.__set__,当对math 进行取值里,就会进入TestProperty.__get__。仔细一看,其实最终访问的还是Student实例的_math属性。
说了这么多,还是运行一下,更加直观一点。
1 | |
对于以上理解 property 的运行原理有困难的同学,请务必参照我上面写的两点说明。如有其他疑问,可以加微信与我进行探讨。
4. 基于描述符如何实现staticmethod
说完了 property ,这里再来讲讲 @classmethod 和 @staticmethod 的实现原理。
我这里定义了一个类,用了两种方式来实现静态方法。
1 | |
这两种写法是等价的,就好像在 property 一样,其实以下两种写法也是等价的。
1 | |
话题还是转回到 staticmethod 这边来吧。
由上面的注释,可以看出 staticmethod 其实就相当于一个描述符类,而myfunc 在此刻变成了一个描述符。关于 staticmethod 的实现,你可以参照下面这段我自己写的代码,加以理解。
调用这个方法可以知道,每调用一次,它都会经过描述符类的 __get__ 。
1 | |
5. 基于描述符如何实现classmethod
同样的 classmethod 也是一样。
1 | |
验证结果如下
1 | |
讲完了 property、staticmethod和classmethod 与 描述符的关系。我想你应该对描述符在 Python 中的应用有了更深的理解。对于 super 的实现原理,就交由你来自己完成。
6. 所有实例共享描述符
通过以上内容的学习,你是不是觉得自己已经对描述符足够了解了呢?
可在这里,我想说以上的描述符代码都有问题。
问题在哪里呢?请看下面这个例子。
1 | |
Student 里没有像前面那样写了构造函数,但是关键不在这儿,没写只是因为没必要写。
然后来看一下会出现什么样的问题呢
1 | |
从结果上来看,std2 居然共享了 std1 的属性值,只要其中一个实例的变量发生改变,另一个实例的变量也会跟着改变。
探其根因,是由于此时 math,chinese,english 三个全部是类变量,导致 std2 和 std1 在访问 math,chinese,english 这三个变量时,其实都是访问类变量。
问题是不是来了?小明和小强的分数怎么可能是绑定的呢?这很明显与实际业务不符。
使用描述符给我们制造了便利,却无形中给我们带来了麻烦,难道这也是描述符的特性吗?
描述符是个很好用的特性,会出现这个问题,是由于我们之前写的描述符代码都是错误的。
描述符的机制,在我看来,只是抢占了访问顺序,而具体的逻辑却要因地制宜,视情况而定。
如果要把 math,chinese,english 这三个变量变成实例之间相互隔离的属性,应该这么写。
1 | |
引导程序逻辑进入描述符之后,不管你是获取属性,还是设置属性,都是直接作用于 instance 的。
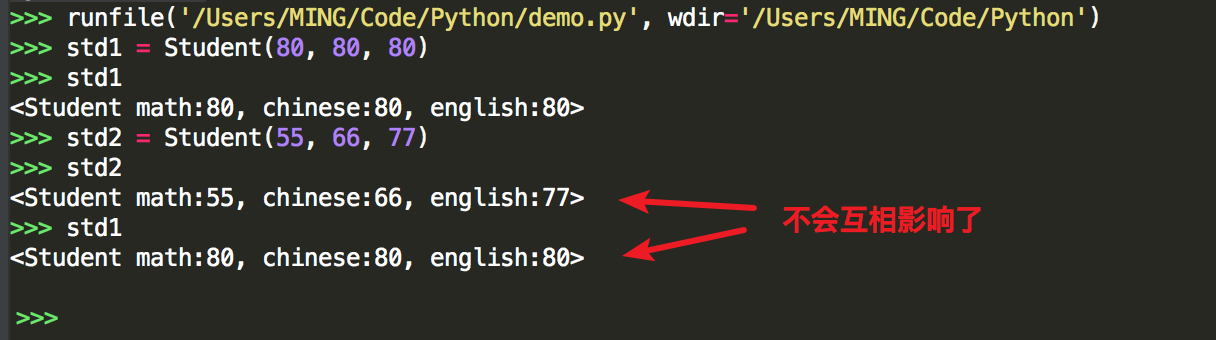
这段代码,你可以仔细和前面的对比一下。
不难看出:
- 之前的错误代码,更像是把描述符当做了存储节点。
- 之后的正确代码,则是把描述符直接当做代理,本身不存储值。
以上便是我对描述符的全部分享,希望能对你有所帮助。
参考文档
第八章:包与模块
8.1 【基础】什么是包、模块和库?
Python 中除了函数库以外,还有非常多且优秀的第三方库、包、模块。
那么问题就来了,库、模块和包各是什么意思?
它们之间有什么区别呢?今天就一起来学习下。
1. 模块
以 .py 为后缀的文件,我们称之为 模块,英文名 Module。
模块让你能够有逻辑地组织你的 Python 代码段,把相关的代码分配到一个模块里能让你的代码更好用,更易懂。
假设现在有一个名为 demo.py 的文件,文件内容如下
1 | |
直接使用 import 语句就可以导入,导入之后,就可以使用 模块名.变量名 的方式访问这个变量。
1 | |
在导入模块的时候,有一个非常重要的全局变量需要掌握,那就是 __name__ 这个变量。
现在把 demo.py 的内容改成
1 | |
- 当模块被直接执行时,
__name__的值为__main__
1 | |
- 当模块被导入时,
__name__的值为 模块名
1 | |
当该模块被导入后,会在当前目录下产生一个 叫做 __pycache__ 的缓存文件夹。
1 | |
这个文件夹有什么用呢?
简单来说,当你导入模块的时候,Python解释器会把模块的代码编译成字节码,并放入 __pycache__文件夹中。
这样以后再次运行的话,如果被调用的模块未发生改变,那就直接跳过编译这一步,直接去__pycache__文件夹中去运行相关的 *.pyc 文件,大大缩短了项目运行前的准备时间。
2. 包
在早一点的 Python 版本(Python 3.3 之前)中,如果一个文件夹下有一个 __init__.py 文件,那我们就称之为包,英文名 Package。
在后来的 Python 版本(Python 3.3 开始)中,就没有这个要求了,只要是文件夹就可以当做包,我们称之为空间命名包,为做区分,我把上面那种包称之为 传统包。
考虑到很多人其实并不需要接触到空间命名包,所以我将空间命名包的内容单独放在一节里,为选读章节。
今天这节里主要讲讲传统包的内容。
传统包里的 __init__.py 可以为空文件,但一定要有该文件,它是包的标志性文件,在需要情况下可以在里面进行一些包的初始化工作。
1 | |
一个包里可以有多个模块,比如上面的 foo.py 和 bar.py 都属于 demo 模块。
如果要使用这些模块,就需要这样导入
1 | |
或者这样
1 | |
3. 库
Python 库是指一定功能的代码集合,通常认为他是一个完整的项目打包。
库->包->模块,是从大到小的层级关系!
- 库:一个库可能由多个包和模块组成
- 包:一个包可能由多个模块组成
- 模块:一堆函数、类、变量的集合
8.2 【基础】安装第三方包的八种方法
1. 使用 easy_install
easy_install 这应该是最古老的包安装方式了,目前基本没有人使用了。下面是 easy_install 的一些安装示例
1 | |
2. 使用 pip install
pip 是最主流的包管理方案,使用 pip install xxx 就可以从 PYPI 上搜索并安装 xxx (如果该包存在的话)。
下面仅列出一些常用的 pip install 的安装示例
1 | |
更多 pip 的使用方法,可参考本系列教程后面的文章,介绍得非常清楚:8.8 pip 的详细使用指南
3. 使用 pipx
pipx 是一个专门用于安装和管理 cli 应用程序的工具,使用它安装的 Python 包会单独安装到一个全新的独有虚拟环境。
由于它是一个第三方工具,因此在使用它之前,需要先安装
1 | |
安装就可以使用 pipx 安装cli 工具了。
1 | |
更多 pipx 的使用方法,可参考本系列教程后面的文章,介绍得非常清楚:12.4 pipx 安装程序的使用指南
4. 使用 setup.py
如果你有编写 setup.py 文件,可以使用如下命令直接安装
1 | |
5. 使用 yum
Python 包在使用 setup.py 构建的时候(具体内容可阅读后面的内容:8.15 超详细讲解 setup.py 的编写),对于包的发布格式有多种选项,其中有一个选项是 bdist_rpm,以这个选项发布出来的包是 rpm 的包格式。
1 | |
对于rpm 这种格式,你需要使用 yum install xxx 或者 rpm install xxx 来安装。
1 | |
6. 使用 pipenv
如果你在使用 pipenv 创建的虚拟环境中,可以使用下面这条命令把包安装到虚拟环境中
1 | |
7. 使用 poetry
如果你有使用 poetry 管理项目依赖,那么可以使用下面这条命令安装包
1 | |
8. 使用 curl + 管道
有一些第三方工具包提供的安装方法,是直接使用 curl 配置管道来安装,比如上面提到的 poetry 就可以用这种方法安装。
1 | |
8.3 【基础】导入单元的构成
导入单元有多种,可以是模块、包及变量等。
对于这些基础的概念,对于新手还是有必要介绍一下它们的区别。
模块:类似 *.py,*.pyc, *.pyd ,*.so,*.dll 这样的文件,是 Python 代码载体的最小单元。
包 还可以细分为两种:
- Regular packages:是一个带有
__init__.py文件的文件夹,此文件夹下可包含其他子包,或者模块 - Namespace packages
关于 Namespace packages,有的人会比较陌生,我这里摘抄官方文档的一段说明来解释一下。
Namespace packages 是由多个 部分 构成的,每个部分为父包增加一个子包。 各个部分可能处于文件系统的不同位置。 部分也可能处于 zip 文件中、网络上,或者 Python 在导入期间可以搜索的其他地方。 命名空间包并不一定会直接对应到文件系统中的对象;它们有可能是无实体表示的虚拟模块。
命名空间包的 __path__ 属性不使用普通的列表。 而是使用定制的可迭代类型,如果其父包的路径 (或者最高层级包的 sys.path) 发生改变,这种对象会在该包内的下一次导入尝试时自动执行新的对包部分的搜索。
命名空间包没有 parent/__init__.py 文件。 实际上,在导入搜索期间可能找到多个 parent 目录,每个都由不同的部分所提供。 因此 parent/one 的物理位置不一定与 parent/two 相邻。 在这种情况下,Python 将为顶级的 parent 包创建一个命名空间包,无论是它本身还是它的某个子包被导入。
8.4 【基础】导入包的标准写法
当我们 import 导入模块或包时,Python 提供两种导入方式:
- 相对导入(relative import ):from . import B 或 from ..A import B,其中.表示当前模块,..表示上层模块
- 绝对导入(absolute import):import foo.bar 或者 from foo import bar
你可以根据实际需要进行选择,但有必要说明的是,在早期的版本( Python2.6 之前),Python 默认使用的相对导入。而后来的版本中( Python2.6 之后),都以绝对导入为默认使用的导入方式。
使用绝对路径和相对路径各有利弊:
- 当你在开发维护自己的项目时,应当使用相对路径导入,这样可以避免硬编码带来的麻烦。
- 而使用绝对路径,会让你模块导入结构更加清晰,而且也避免了重名的包冲突而导入错误。
在 PEP8 中对模块的导入提出了要求,遵守 PEP8规范能让你的代码更具有可读性,我这边也列一下:
- import 语句应当分行书写
1 | |
- import语句应当使用absolute import
1 | |
import语句应当放在文件头部,置于模块说明及docstring之后,全局变量之前
import语句应该按照顺序排列,每组之间用一个空格分隔,按照内置模块,第三方模块,自己所写的模块调用顺序,同时每组内部按照字母表顺序排列
1 | |
8.5 【进阶】常规包与空间命名包
1. 常规包
在 Python 3.3 之前或者说 Python 2 中,一个包想要被导入使用,那么该包内必须要有 __init__.py 文件,这个文件是 Python 识别一个文件夹是否是一个 Python 的重要标志。
举个例子,现在有如下的目录树,demo 及子文件夹 foo 和 bar 下都有 __init__.py 文件。
1 | |
在该目录下进入 Python Console 模式,然后就可以正常导入了
1 | |
如果此时我把 demo 目录下的 __init__.py 删除
1 | |
再导入就会报错。
1 | |
2. 命名空间包
在 Python 3.3 之后(PEP 420),即使一个文件夹中没有定义 __init__.py,也是可以被导入的,只不过它不是以 Python 包的形式导入,而是以命名空间包 (Namespace package) 的形式被导入,而这一特性是在 Python 3.3 被引入的。
比如还是上面的目录结构:
1 | |
在 Python 3 下进入 Python Console 模式,发现导入是正常的
1 | |
使用 __path__ 查看一下,发现 demo 不再是一个常规包了,而是一个 namespace package
1 | |
3. 空间命名包的好处
利用命名空间包这个技术,可以用来导入目录分散的代码。
比如有如下的目录树
1 | |
在这 xc-pkg 和 xm-pkg 这两个目录里,都有着共同的命名空间 demo。这时候再导入这两个包的时候,发现这两个包被合并到一起了
1 | |
在这里工作的机制被称为命名空间包的一个特征。从本质上讲,命名空间包是一种特殊的封装设计,为合并不同的目录的代码到一个共同的命名空间。
命名空间包的关键是确保顶级目录中没有 __init__.py 文件来作为共同的命名空间。缺失 __init__.py 文件使得在导入包的时候会发生有趣的事情:这并没有产生错误,解释器创建了一个由所有包含匹配包名的目录组成的列表。特殊的包命名空间模块被创建,只读的目录列表副本被存储在其 __path__ 变量中。
1 | |
一个包是否被作为一个包命名空间的主要方法是检查其 __file__ 属性。如果没有,那包是个命名空间。这也可以由其字符表现形式中的 namespace 这个词体现出来。
1 | |
8.6 【进阶】花式导包的八种方法
1. 直接 import
人尽皆知的方法,直接导入即可
1 | |
与此类似的还有,不再细讲
1 | |
一般情况下,使用 import 语句导入模块已经够用的。
但是在一些特殊场景中,可能还需要其他的导入方式。
下面我会一一地给你介绍。
2. 使用 _import_
__import__ 函数可用于导入模块,import 语句也会调用函数。其定义为:
1 | |
参数介绍:
- name (required): 被加载 module 的名称
- globals (optional): 包含全局变量的字典,该选项很少使用,采用默认值 global()
- locals (optional): 包含局部变量的字典,内部标准实现未用到该变量,采用默认值 - local()
- fromlist (Optional): 被导入的 submodule 名称
- level (Optional): 导入路径选项,Python 2 中默认为 -1,表示同时支持 absolute import 和 relative import。Python 3 中默认为 0,表示仅支持 absolute import。如果大于 0,则表示相对导入的父目录的级数,即 1 类似于 ‘.’,2 类似于 ‘..’。
使用示例如下:
1 | |
如果要实现 import xx as yy 的效果,只要修改左值即可
如下示例,等价于 import os as myos:
1 | |
上面说过的 __import__ 是一个内建函数,既然是内建函数的话,那么这个内建函数必将存在于 __buildins__ 中,因此我们还可以这样导入 os 的模块:
1 | |
3. 使用 importlib 模块
importlib 是 Python 中的一个标准库,importlib 能提供的功能非常全面。
它的简单示例:
1 | |
如果要实现 import xx as yy效果,可以这样
1 | |
4. 使用 imp 模块
imp 模块提供了一些 import 语句内部实现的接口。例如模块查找(find_module)、模块加载(load_module)等等(模块的导入过程会包含模块查找、加载、缓存等步骤)。可以用该模块来简单实现内建的 __import__ 函数功能:
1 | |
从 python 3 开始,内建的 reload 函数被移到了 imp 模块中。而从 Python 3.4 开始,imp 模块被否决,不再建议使用,其包含的功能被移到了 importlib 模块下。即从 Python 3.4 开始,importlib 模块是之前 imp 模块和 importlib 模块的合集。
5. 使用 execfile
在 Python 2 中有一个 execfile 函数,利用它可以用来执行一个文件。
语法如下:
1 | |
参数有这么几个:
- filename:文件名。
- globals:变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
- locals:变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
1 | |
6. 使用 exec 执行
execfile 只能在 Python2 中使用,Python 3.x 里已经删除了这个函数。
但是原理值得借鉴,你可以使用 open … read 读取文件内容,然后再用 exec 去执行模块。
示例如下:
1 | |
7. import_from_github_com
有一个包叫做 import_from_github_com,从名字上很容易得知,它是一个可以从 github 下载安装并导入的包。为了使用它,你需要做的就是按照如下命令使用pip 先安装它。
1 | |
这个包使用了PEP 302中新的引入钩子,允许你可以从github上引入包。这个包实际做的就是安装这个包并将它添加到本地。你需要 Python 3.2 或者更高的版本,并且 git 和 pip 都已经安装才能使用这个包。
pip 要保证是较新版本,如果不是请执行如下命令进行升级。
1 | |
确保环境 ok 后,你就可以在 Python shell 中使用 import_from_github_com
示例如下
1 | |
看了 import_from_github_com的源码后,你会注意到它并没有使用importlib。实际上,它的原理就是使用 pip 来安装那些没有安装的包,然后使用Python的__import__()函数来引入新安装的模块。
8. 远程导入模块
在后面有一篇文章里,深入剖析了导入模块的内部原理,并在最后手动实现了从远程服务器上读取模块内容,并在本地成功将模块导入的导入器。
具体内容非常的多,你可以点击这个链接进行深入学习。
示例代码如下:
1 | |
并且在远程服务器上开启 http 服务(为了方便,我仅在本地进行演示),并且手动编辑一个名为 my_info 的 python 文件,如果后面导入成功会打印 ok。
1 | |
一切准备好,验证开始。
1 | |
好了,8 种方法都给大家介绍完毕,对于普通开发者来说,其实只要掌握 import 这种方法足够了,而对于那些想要自己开发框架的人来说,深入学习__import__以及 importlib 是非常有必要的。## 8.7 【进阶】包导入的三个冷门知识点
1. 使用 _all_ 控制可被导入的变量
使用 from module import * 默认情况下会导入 module 里的所有变量,若你只想从模块中导入其中几个变量,可以在 module 中使用 __all__ 来控制想要被其他模块导入的变量。
1 | |
打开 python console 验证一下
1 | |
__all__ 仅对于使用from module import * 这种情况适用。
它经常在一个包的 __init__.py 中出现。
2. 命名空间包的神奇之处
命名空间包,一个陌生的名字。
与我们熟悉的常规包不同的是,它没有 __init__.py 文件。
更为特殊的是,它可以跨空间地将两个不相邻的子包,合并成一个虚拟机的包,我们将其称之为 命名空间包。
例如,一个项目的部分代码布局如下
1 | |
在这2个目录里,都有着共同的命名空间spam。在任何一个目录里都没有_init_.py文件。
让我们看看,如果将foo-package和bar-package都加到python模块路径并尝试导入会发生什么?
1 | |
当一个包为命名空间包时,他就不再和常规包一样具有 __file_ 属性,取而代之的是 __path__
1 | |
3. 模块重载中的一个坑
由于有 sys.modules 的存在,当你导入一个已导入的模块时,实际上是没有效果的。
为了达到模块的重载,有的人会将已导入的包从 sys.modules 中移除后再导入
就像下面这样子
1 | |
上面的例子里我使用的是import foo.bar ,如果你使用的是 from foo import bar 这种导入形式,会发现重载是同样是无效的。
这应该算是一个小坑,不知道的人,会掉入坑中爬不出来。
1 | |
因此,在生产环境中可能需要避免重新加载模块。而在调试模式中,它会提供一定的便利,但你要知道这个重载的弊端,以免掉入坑里。
8.8 【基础】pip 的超全使用指南
所有的 Python 开发者都清楚,Python 之所以如此受欢迎,能够在众多高级语言中,脱颖而出,除了语法简单,上手容易之外,更多还要归功于 Python 生态的完备,有数以万计的 Python 爱好者愿意以 Python 为基础封装出各种有利于开发的第三方工具包。
这才使用我们能够以最快的速度开发出一个满足基本需要的项目,而不是每次都重复造轮子。
Python 从1991年诞生到现在,已经过去28个年头了,这其间产生了数以万计的第三方包,且每个包都会不断更新,会有越来越多的版本。
当你在一个复杂的项目环境中,如果没有一个有效的依赖包管理方案,项目的维护将会是一个大问题。
pip 是官方推荐的包管理工具,在大多数开发者眼里,pip 几乎是 Python 的标配。
当然也有其他的包管理工具
distutils:仅用于打包和安装,严格来讲不算是包管理工具
setuptools:distutils的增强版,扩展了distutils,提供更多的功能,引入包依赖的管理,easy_install就是它的一个命令行工具,引入了 egg 的文件格式。
Pipenv:一个集依赖包管理(pip)及虚拟环境管理(virtualenv)的工具
还有其他的,这里不一一列出。
今天的主角是 pip ,大家肯定不会陌生。但我相信不少人,只是熟悉几个常用的用法,而对于其他几个低频且实用的用法,却知之甚少,这两天,我查阅官方文档,把这些用法整理了一下,应该是网络上比较全的介绍。
1. 查询软件包
查询当前环境安装的所有软件包
1 | |
查询 pypi 上含有某名字的包
1 | |
查询当前环境中可升级的包
1 | |
查询一个包的详细内容
1 | |
2. 下载软件包
在不安装软件包的情况下下载软件包到本地
1 | |
下载完,总归是要安装的,可以指定这个目录中安装软件包,而不从 pypi 上安装。
1 | |
当然你也从你下载的包中,自己构建生成 wheel 文件
1 | |
3. 安装软件包
使用 pip install <pkg> 可以很方便地从 pypi 上搜索下载并安装 python 包。
如下所示
1 | |
这是安装包的基本格式,我们也可以为其添加更多参数来实现不同的效果。
3.1 只从本地安装,而不从 pypi 安装
1 | |
3.2 限定版本进行软件包安装
以下三种,对单个 python 包的版本进行了约束
1 | |
以下命令用于管理/控制整个 python 环境的包版本
1 | |
3.3 限制不使用二进制包安装
由于默认情况下,wheel 包的平台是运行 pip download 命令 的平台,所以可能出现平台不适配的情况。
比如在 MacOS 系统下得到的 pymongo-2.8-cp27-none-macosx_10_10_intel.whl 就不能在 linux_x86_64 安装。
使用下面这条命令下载的是 tar.gz 的包,可以直接使用 pip install 安装。
比 wheel 包,这种包在安装时会进行编译,所以花费的时间会长一些。
1 | |
3.4 指定代理服务器安装
当你身处在一个内网环境中时,无法直接连接公网。这时候你使用pip install 安装包,就会失败。
面对这种情况,可以有两种方法:
- 下载离线包拷贝到内网机器中安装
- 使用代理服务器转发请求
第一种方法,虽说可行,但有相当多的弊端
- 步骤繁杂,耗时耗力
- 无法处理包的依赖问题
这里重点来介绍,第二种方法:
1 | |
每次安装包就发输入长长的参数,未免有些麻烦,为此你可以将其写入配置文件中:$HOME/.config/pip/pip.conf
对于这个路径,说明几点
- 不同的操作系统,路径各不相同
1 | |
- 若在你的机子上没有此文件,则自行创建即可
如何配置,这边给个样例:
1 | |
3.5 安装用户私有软件包
很多人可能还不清楚,python 的安装包是可以用户隔离的。
如果你拥有管理员权限,你可以将包安装在全局环境中。在全局环境中的这个包可被该机器上的所有拥有管理员权限的用户使用。
如果一台机器上的使用者不只一样,自私地将在全局环境中安装或者升级某个包,是不负责任且危险的做法。
面对这种情况,我们就想能否安装单独为我所用的包呢?
庆幸的是,还真有。
我能想到的有两种方法:
- 使用虚拟环境
- 将包安装在用户的环境中
虚拟环境,之前写过几篇文章,这里不再展开讲。
今天的重点是第二种方法,教你如何安装用户私有的包?
命令也很简单,只要加上 --user 参数,pip 就会将其安装在当前用户的 ~/.local/lib/python3.x/site-packages 下,而其他用户的 python 则不会受影响。
1 | |
来举个例子
1 | |
当你身处个人用户环境中,python 导包时会先检索当前用户环境中是否已安装这个包,已安装则优先使用,未安装则使用全局环境中的包。
验证如下:
1 | |
3.6 延长超时时间
若网络情况不是很好,在安装某些包时经常会因为 ReadTimeout 而失败。
对于这种情况,一般重试几次就好了。
但是这样难免有些麻烦,有没有更好的解决方法呢?
有的,可以通过延长超时时间。
1 | |
4. 卸载软件包
就一条命令,不再赘述
1 | |
5. 升级软件包
想要对现有的 python 进行升级,其本质上也是先从 pypi 上下载最新版本的包,再对其进行安装。所以升级也是使用 pip install,只不过要加一个参数 --upgrade。
1 | |
在升级的时候,其实还有一个不怎么用到的选项 --upgrade-strategy,它是用来指定升级策略。
它的可选项只有两个:
eager:升级全部依赖包only-if-need:只有当旧版本不能适配新的父依赖包时,才会升级。
在 pip 10.0 版本之后,这个选项的默认值是 only-if-need,因此如下两种写法是一互致的。
1 | |
6. 配置文件
由于在使用 pip 安装一些包时,默认会使用 pip 的官方源,所以经常会报网络超时失败。
常用的解决办法是,在安装包时,使用 -i 参数指定一个国内的镜像源。但是每次指定就很麻烦呀,还要打超长的一串字母。
这时候,其实可以将这个源写进 pip 的配置文件里。以后安装的时候,就默认从你配置的这个 源里安装了。
那怎么配置呢?文件文件在哪?
使用 win+r 输入 %APPDATA% 进入用户资料文件夹,查看有没有一个 pip 的文件夹,若没有则创建之。
然后进入这个 文件夹,新建一个 pip.ini 的文件,内容如下
1 | |
以上几乎包含了 pip 的所有常用使用场景,为了方便,我将其整理成一张表格。
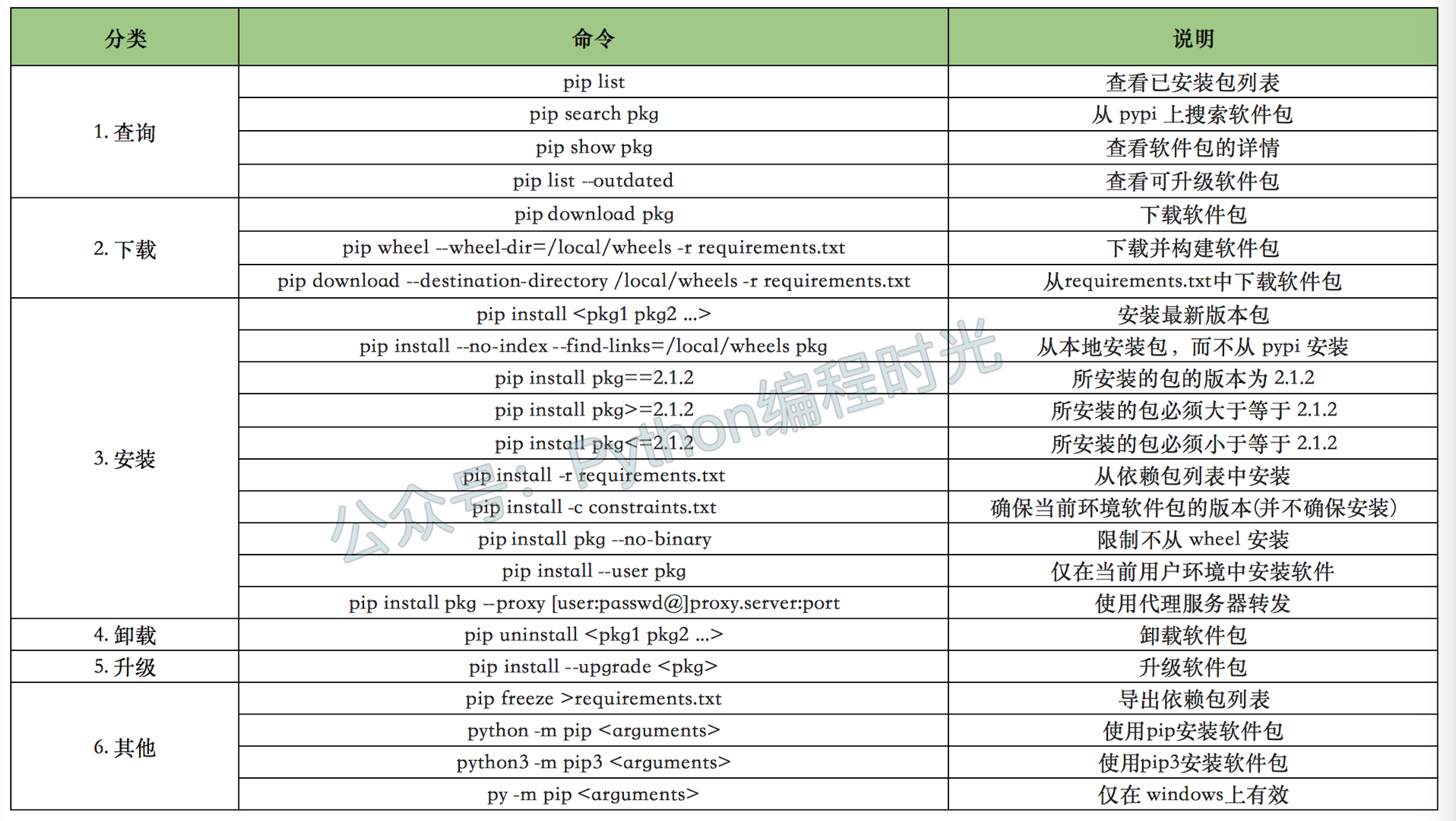
8.9 【进阶】理解模块的缓存
在一个模块内部重复引用另一个相同模块,实际并不会导入两次,原因是在使用关键字 import 导入模块时,它会先检索 sys.modules 里是否已经载入这个模块了,如果已经载入,则不会再次导入,如果不存在,才会去检索导入这个模块。
来实验一下,在 my_mod02 这个模块里,我 import 两次 my_mod01 这个模块,按逻辑每一次 import 会一次 my_mod01 里的代码(即打印 in mod01),但是验证结果是,只打印了一次。
1 | |
该现象的解释是:因为有 sys.modules 的存在。
sys.modules 是一个字典(key:模块名,value:模块对象),它存放着在当前 namespace 所有已经导入的模块对象。
1 | |
运行结果如下,可见在 导入后 json 模块后,sys.modules 才有了 json 模块的对象。
1 | |
由于有缓存的存在,使得我们无法重新载入一个模块。
但若你想反其道行之,可以借助 importlib 这个神奇的库来实现。事实也确实有此场景,比如在代码调试中,在发现代码有异常并修改后,我们通常要重启服务再次载入程序。这时候,若有了模块重载,就无比方便了,修改完代码后也无需服务的重启,就能继续调试。
还是以上面的例子来理解,my_mod02.py 改写成如下
1 | |
使用 python3 来执行这个模块,与上面不同的是,这边执行了两次 my_mod01.py
1 | |
8.10 【进阶】理解查找器与加载器
如果指定名称的模块在 sys.modules 找不到,则将发起调用 Python 的导入协议以查找和加载该模块。
此协议由两个概念性模块构成,即 查找器 和 加载器。
一个 Python 的模块的导入,其实可以再细分为两个过程:
- 由查找器实现的模块查找
- 由加载器实现的模块加载
1. 查找器是什么?
查找器(finder),简单点说,查找器定义了一个模块查找机制,让程序知道该如何找到对应的模块。
其实 Python 内置了多个默认查找器,其存在于 sys.meta_path 中。
但这些查找器对应使用者来说,并不是那么重要,因此在 Python 3.3 之前, Python 解释将其隐藏了,我们称之为隐式查找器。
1 | |
由于这点不利于开发者深入理解 import 机制,在 Python 3.3 后,所有的模块导入机制都会通过 sys.meta_path 暴露,不会在有任何隐式导入机制。
1 | |
观察一下 Python 默认的这几种查找器 (finder),可以分为三种:
- 一种知道如何导入内置模块
- 一种知道如何导入冻结模块
- 一种知道如何导入来自 import path 的模块 (即 path based finder)。
那我们能不能自已定义一个查找器呢?当然可以,你只要
- 定义一个实现了 find_module 方法的类(py2和py3均可),或者实现 find_loader 类方法(仅 py3 有效),如果找到模块需要返回一个 loader 对象或者 ModuleSpec 对象(后面会讲),没找到需要返回 None
- 定义完后,要使用这个查找器,必须注册它,将其插入在 sys.meta_path 的首位,这样就能优先使用。
1 | |
查找器可以分为两种:
1 | |
这里需要注意的是,在 3.4 版前,查找器会直接返回 加载器(Loader)对象,而在 3.4 版后,查找器则会返回模块规格说明(ModuleSpec),其中 包含加载器。
而关于什么是 加载器 和 模块规格说明, 请继续往后看。
2. 加载器是什么?
查找器只负责查找定位找模,而真正负责加载模块的,是加载器(loader)。
一般的 loader 必须定义名为 load_module() 的方法。
为什么这里说一般,因为 loader 还分多种:
1 | |
通过查看源码可知,不同的加载器的抽象方法各有不同。
加载器通常由一个 finder 返回。详情参见 PEP 302,对于 abstract base class 可参见 importlib.abc.Loader。
那如何自定义我们自己的加载器呢?
你只要
- 定义一个实现了 load_module 方法的类
- 对与导入有关的属性(点击查看详情)进行校验
- 创建模块对象并绑定所有与导入相关的属性变量到该模块上
- 将此模块保存到 sys.modules 中(顺序很重要,避免递归导入)
- 然后加载模块(这是核心)
- 若加载出错,需要能够处理抛出异常( ImportError)
- 若加载成功,则返回 module 对象
若你想看具体的例子,可以接着往后看。
3. 模块规格说明
导入机制在导入期间会使用有关每个模块的多种信息,特别是加载之前。 大多数信息都是所有模块通用的。 模块规格说明的目的是基于每个模块来封装这些导入相关信息。
模块的规格说明会作为模块对象的 __spec__ 属性对外公开。 有关模块规格的详细内容请参阅 ModuleSpec。
在 Python 3.4 后,查找器不再返回加载器,而是返回 ModuleSpec 对象,它储存着更多的信息
- 模块名
- 加载器
- 模块绝对路径
那如何查看一个模块的 ModuleSpec ?
这边举个例子
1 | |
从 ModuleSpec 中可以看到,加载器是包含在内的,那我们如果要重新加载一个模块,是不是又有了另一种思路了?
来一起验证一下。
现在有两个文件:
一个是 my_info.py
1 | |
另一个是:main.py
1 | |
在 main.py 处,我加了一个断点,目的是当运行到断点处时,我修改 my_info.py 里的 name 为 ming ,以便验证重载是否有效?
1 | |
从结果来看,重载是有效的。
4. 导入器是什么?
导入器(importer),也许你在其他文章里会见到它,但其实它并不是个新鲜的东西。
它只是同时实现了查找器和加载器两种接口的对象,所以你可以说导入器(importer)是查找器(finder),也可以说它是加载器(loader)。
8.11 【进阶】实现远程导入模块
由于 Python 默认的 查找器和加载器 仅支持本地的模块的导入,并不支持实现远程模块的导入。
为了让你更好的理解 Python Import Hook 机制,我下面会通过实例演示,如何自己实现远程导入模块的导入器。
1. 动手实现导入器
当导入一个包的时候,Python 解释器首先会从 sys.meta_path 中拿到查找器列表。
默认顺序是:内建模块查找器 -> 冻结模块查找器 -> 第三方模块路径(本地的 sys.path)查找器
若经过这三个查找器,仍然无法查找到所需的模块,则会抛出ImportError异常。
因此要实现远程导入模块,有两种思路。
- 一种是实现自己的元路径导入器;
- 另一种是编写一个钩子,添加到sys.path_hooks里,识别特定的目录命名模式。
我这里选择第一种方法来做为示例。
实现导入器,我们需要分别查找器和加载器。
首先是查找器
由源码得知,路径查找器分为两种
- MetaPathFinder
- PathEntryFinder
这里使用 MetaPathFinder 来进行查找器的编写。
在 Python 3.4 版本之前,查找器必须实现 find_module() 方法,而 Python 3.4+ 版,则推荐使用 find_spec() 方法,但这并不意味着你不能使用 find_module(),但是在没有 find_spec() 方法时,导入协议还是会尝试 find_module() 方法。
我先举例下使用 find_module() 该如何写。
1 | |
若使用 find_spec() ,要注意此方法的调用需要带有两到三个参数。
第一个是被导入模块的完整限定名称,例如 foo.bar.baz。 第二个参数是供模块搜索使用的路径条目。 对于最高层级模块,第二个参数为 None,但对于子模块或子包,第二个参数为父包 __path__ 属性的值。 如果相应的 __path__ 属性无法访问,将引发 ModuleNotFoundError。 第三个参数是一个将被作为稍后加载目标的现有模块对象。 导入系统仅会在重加载期间传入一个目标模块。
1 | |
接下来是加载器
由源码得知,路径查找器分为三种
- FileLoader
- SourceLoader
按理说,两种加载器都可以实现我们想要的功能,我这里选用 SourceLoader 来示范。
在 SourceLoader 这个抽象类里,有几个很重要的方法,在你写实现加载器的时候需要注意
- get_code:获取源代码,可以根据自己场景实现实现。
- exec_module:执行源代码,并将变量赋值给
module.__dict__ - get_data:抽象方法,必须实现,返回指定路径的字节码。
- get_filename:抽象方法,必须实现,返回文件名
在一些老的博客文章中,你会经常看到 加载器 要实现 load_module() ,而这个方法早已在 Python 3.4 的时候就被废弃了,当然为了兼容考虑,你若使用 load_module() 也是可以的。
1 | |
当你使用这种旧模式实现自己的加载时,你需要注意两点,很重要:
- execute_module 必须重载,而且不应该有任何逻辑,即使它并不是抽象方法。
- load_module,需要你在查找器里手动执行,才能实现模块的加载。。
做为替换,你应该使用 execute_module() 和 create_module() 。由于基类里已经实现了 execute_module 和 create_module(),并且满足我们的使用场景。我这边可以不用重复实现。和旧模式相比,这里也不需要在设查找器里手动执行 execute_module()。
1 | |
查找器和加载器都有了,别忘了往sys.meta_path 注册我们自定义的查找器(UrlMetaFinder)。
1 | |
所有的代码都解析完毕后,我们将其整理在一个模块(my_importer.py)中
1 | |
2. 搭建远程服务端
最开始我说了,要实现一个远程导入模块的方法。
我还缺一个在远端的服务器,来存放我的模块,为了方便,我使用python自带的 http.server 模块用一条命令即可实现。
1 | |
一切准备好,我们就可以验证了。
1 | |
至此,我实现了一个简易的可以导入远程服务器上的模块的导入器。
8.12 【基础】分发工具:distutils和setuptools
1. 包分发的始祖:distutils
distutils 是 Python 的一个标准库,从命名上很容易看出它是一个分发(distribute)工具(utlis),它是 Python 官方开发的一个分发打包工具,所有后续的打包工具,全部都是基于它进行开发的。
distutils 的精髓在于编写 setup.py,它是模块分发与安装的指导文件。
那么如何编写 setup.py 呢?这里面的内容非常多,我会在后面进行详细的解析,请你耐心往下看。
你有可能没写过 setup.py ,但你绝对使用过 setup.py 来做一些事情,比如下面这条命令,我们经常用它来进行模块的安装。
1 | |
这样的安装方法是通过源码安装,与之对应的是通过二进制软件包的安装,同样我也会在后面进行介绍。
2. 分发工具升级:setuptools
setuptools 是 distutils 增强版,不包括在标准库中。其扩展了很多功能,能够帮助开发者更好的创建和分发 Python 包。大部分 Python 用户都会使用更先进的 setuptools 模块。
distribute,或许你在其他地方也见过它,这里也提一下。
distribute 是 setuptools 有一个分支版本,分支的原因可能是有一部分开发者认为 setuptools 开发太慢了。但现在,distribute 又合并回了 setuptools 中。因此,我们可以认为它们是同一个东西。
还有一个大包分发工具是 distutils2,其试图尝试充分利用distutils,detuptools 和 distribute 并成为 Python 标准库中的标准工具。但该计划并没有达到预期的目的,且已经是一个废弃的项目。
因此,setuptools 是一个优秀的,可靠的 Python 包安装与分发工具。
那么如何在一个干净的环境中安装 setuptools 呢?
主要有两种方法:
- 源码安装:在 https://pypi.org/project/setuptools/#files 中下载 zip 包 解压执行
python setup.py install安装 - 通过引导程序安装:下载引导程序,它可以用来下载或者更新最新版本的 setuptools
1 | |
8.13 【基础】源码包与二进制包有什么区别?
Python 包的分发可以分为两种:
- 以源码包的方式发布
源码包安装的过程,是先解压,再编译,最后才安装,所以它是跨平台的,由于每次安装都要进行编译,相对二进包安装方式来说安装速度较慢。
源码包的本质是一个压缩包,其常见的格式有:
- 以二进制包形式发布
二进制包的安装过程省去了编译的过程,直接进行解压安装,所以安装速度较源码包来说更快。
由于不同平台的编译出来的包无法通用,所以在发布时,需事先编译好多个平台的包。
二进制包的常见格式有:
8.14 【基础】eggs与wheels 有什么区别?
Egg 格式是由 setuptools 在 2004 年引入,而 Wheel 格式是由 PEP427 在 2012 年定义。Wheel 的出现是为了替代 Egg,它的本质是一个zip包,其现在被认为是 Python 的二进制包的标准格式。
以下是 Wheel 和 Egg 的主要区别:
- Wheel 有一个官方的 PEP427 来定义,而 Egg 没有 PEP 定义
- Wheel 是一种分发格式,即打包格式。而 Egg 既是一种分发格式,也是一种运行时安装的格式,并且是可以被直接 import
- Wheel 文件不会包含 .pyc 文件
- Wheel 使用和 PEP376 兼容的 .dist-info 目录,而 Egg 使用 .egg-info 目录
- Wheel 有着更丰富的命名规则。
- Wheel 是有版本的。每个 Wheel 文件都包含 wheel 规范的版本和打包的实现
- Wheel 在内部被 sysconfig path type 管理,因此转向其他格式也更容易
wheel 包可以通过 pip 来安装,只不过需要先安装 wheel 模块,然后再使用 pip 的命令。
1 | |
8.15 【进阶】超详细讲解 setup.py 的编写
1. setup.py 的编写
1、构建源码发布包。
用于发布一个 Python 模块或项目,将源码打包成 tar.gz (用于 Linux 环境中)或者 zip 压缩包(用于 Windows 环境中)
1 | |
那这种包如何安装呢?
答案是,使用 setuptools 中提供的 easy_install 工具。
1 | |
使用 sdist 将根据当前平台创建默认格式的存档。在类 Unix 平台上,将创建后缀后为 .tar.gz 的 gzip 压缩的tar文件分发包,而在Windows上为 ZIP 文件。
当然,你也可以通过指定你要的发布包格式来打破这个默认行为
1 | |
你可以指定的格式有哪些呢?
创建一个压缩的tarball和一个zip文件。可用格式为:

对以上的格式,有几点需要注意一下:
- 在版本3.5中才添加了对
xztar格式的支持 - zip 格式需要你事先已安装相应的模块:zip程序或zipfile模块(已成为Python的标准库)
- ztar 格式正在弃用,请尽量不要使用
另外,如果您希望归档文件的所有文件归root拥有,可以这样指定
1 | |
2、构建二进制分发包。
在windows中我们习惯了双击 exe 进行软件的安装,Python 模块的安装也同样支持 打包成 exe 这样的二进制软件包。
1 | |
而在 Linux 中,大家也习惯了使用 rpm 来安装包,对此你可以使用这条命令实现 rpm 包的构建
1 | |
若你喜欢使用 easy_install 或者 pip 来安装离线包。你可以将其打包成 egg 包
1 | |
若你的项目,需要安装多个平台下,既有 Windows 也有 Linux,按照上面的方法,多种格式我们要执行多次命令,为了方便,你可以一步到位,执行如下这条命令,即可生成多个格式的进制包
1 | |
2. 使用 setup.py 安装包
正常情况下,我们都是通过以上构建的源码包或者二进制包进行模块的安装。
但在编写 setup.py 的过程中,可能不能一步到位,需要多次调试,这时候如何测试自己写的 setup.py 文件是可用的呢?
这时候你可以使用这条命令,它会将你的模块安装至系统全局环境中
1 | |
如若你的项目还处于开发阶段,频繁的安装模块,也是一个麻烦事。
这时候你可以使用这条命令安装,该方法不会真正的安装包,而是在系统环境中创建一个软链接指向包实际所在目录。这边在修改包之后不用再安装就能生效,便于调试。
1 | |
8.16 【进阶】打包辅助神器 PBR 是什么?
pbr 是 setuptools 的辅助工具,最初是为 OpenStack 开发(https://launchpad.net/pbr),基于`d2to1`。
pbr 会读取和过滤setup.cfg中的数据,然后将解析后的数据提供给 setup.py 作为参数。包含如下功能:
- 从git中获取Version、AUTHORS and ChangeLog信息
- Sphinx Autodoc。pbr 会扫描project,找到所有模块,生成stub files
- Requirements。pbr会读取requirements.txt,生成setup函数需要的
install_requires/tests_require/dependency_links
这里需要注意,在 requirements.txt 文件的头部可以使用:--index https://pypi.python.org/simple/,这一行把一个抽象的依赖声明如 requests==1.2.0 转变为一个具体的依赖声明 requests 1.2.0 from pypi.python.org/simple/
- long_description。从README.rst, README.txt or README file中生成
long_description参数
使用pbr很简单:
1 | |
使用pbr时,setup.cfg中有一些配置。在[files]中,有三个key:packages:指定需要包含的包,行为类似于setuptools.find_packagesnamespace_packages:指定namespace packagesdata_files: 指定目的目录和源文件路径,一个示例:
1 | |
[entry_points] 段跟 setuptools 的方式相同。
到此,我讲了三种编写使用 setup.py 的方法
- 使用命令行参数指定,一个一个将参数传递进去(极不推荐)
- 在 setup.py 中的setup函数中指定(推荐使用)
- 使用 pbr ,在 setup.cfg 中指定(易于管理,更推荐)## 8.17 【进阶】开源自己的包到 PYPI 上
通过前面的学习,你一定已经学会了如何打包自己的项目,若你觉得自己开发的模块非常不错,想要 share 给其他人使用,你可以将其上传到 PyPi (Python Package Index)上,它是 Python 官方维护的第三方包仓库,用于统一存储和管理开发者发布的 Python 包。
如果要发布自己的包,需要先到 pypi 上注册账号。然后创建 ~/.pypirc 文件,此文件中配置 PyPI 访问地址和账号。如的.pypirc文件内容请根据自己的账号来修改。
典型的 .pypirc 文件
1 | |
然后使用这条命令进行信息注册,完成后,你可以在 PyPi 上看到项目信息。
1 | |
注册完了后,你还要上传源码包,别人才使用下载安装
1 | |
或者也可以使用 twine 工具注册上传,它是一个专门用于与 pypi 进行交互的工具,详情可以参考官网:https://www.ctolib.com/twine.html,这里不详细讲了。
第九章:调试技巧
9.1 【调试技巧】超详细图文教你调试代码
1. 调试的过程
调试可以说是每个开发人员都必备一项技能,在日常开发和排查 bug 都非常有用。
调试的过程分为三步:
第一步:在你想要调试的地方,打上断点
第二步:使用调试模式来运行这个 python 程序
第三步:使用各种手段开始代码调试
首先第一步和第二步,我用下面这张图表示
点击上图中的小蜘蛛,开启调试模式后,在 PyCharm 下方会弹出一个选项卡。
这个选项卡的按键非常多,包括
- 变量查看窗口
- 调试控制窗口
- 线程控制窗口
- 程序控制窗口
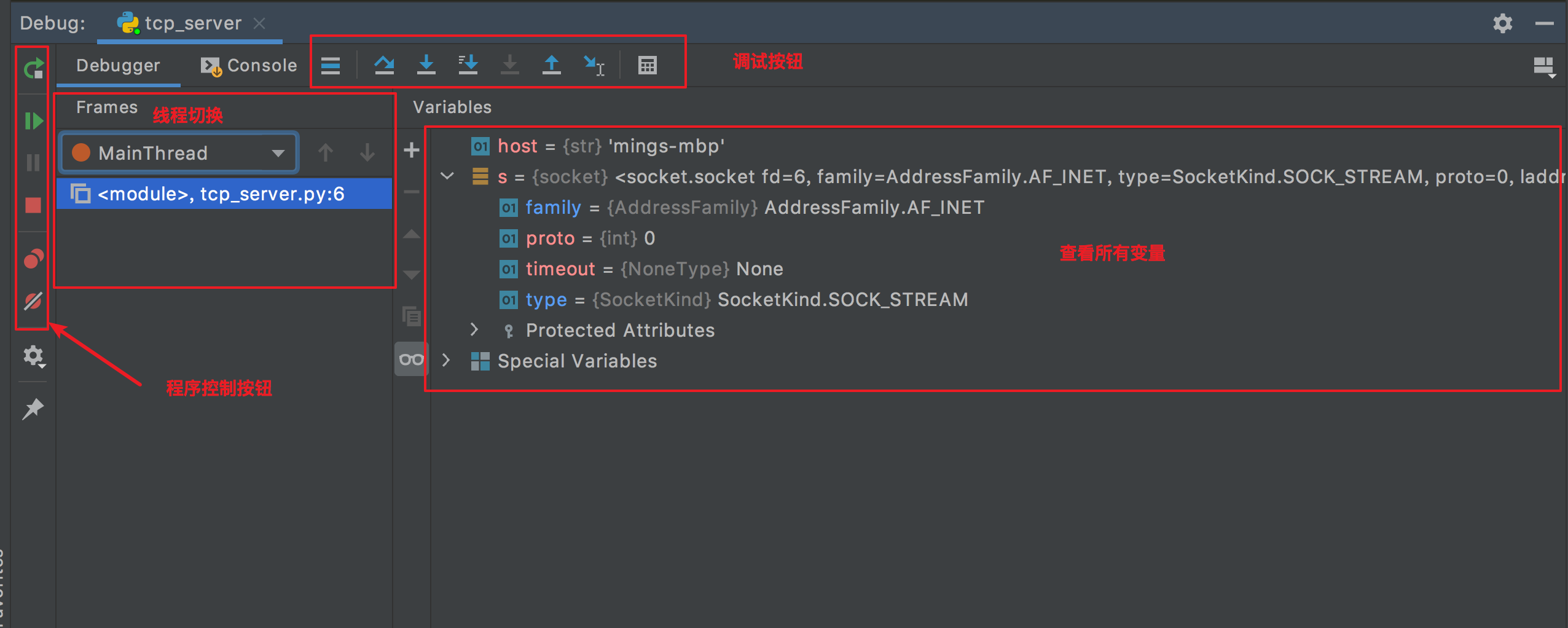
在变量查看窗口,你可以查看当前程序进行到该断点处,所有的普通变量和特殊变量,你每往下执行一行代码,这些变量都有可能跟着改变。
如果你的程序是多线程的,你可以通过线程控制窗口的下拉框来切换线程。
以上两个窗口,都相对比较简单,我一笔带过,下面主要重点讲下调试控制按钮和程序控制按钮。
在调试控制窗口,共有 8 个按钮,他们的作用分别是什么呢?
- Show Execution Point:无论你的代码编辑 窗口的光标在何处,只要点下该按钮,都会自动跳转到程序运行的地方。
- Step Over:在单步执行时,在函数内遇到子函数时不会进入子函数内单步执行,而是将子函数整个执行完再停止,也就是把子函数整个作为一步。在不存在子函数的情况下是和step into效果一样的。简单的说就是,程序代码越过子函数,但子函数会执行,且不进入。
- Step Into:在单步执行时,遇到子函数就进入并且继续单步执行,有的会跳到源代码里面去执行。
- Step Into My Code:在单步执行时,遇到子函数就进入并且继续单步执行,不会进入到源码中。
- Step Out:假如进入了一个函数体中,你看了两行代码,不想看了,跳出当前函数体内,返回到调用此函数的地方,即使用此功能即可。
- Run To Cursor:运行到光标处,省得每次都要打一个断点。
- Evaluate Expression:计算表达式,在里面可以自己执行一些代码。
以上七个功能,就是最常用的功能,一般操作步骤就是,设置好断点,debug运行,然后 F8 单步调试,遇到想进入的函数 F7 进去,想出来在 shift + F8,跳过不想看的地方,直接设置下一个断点,然后 F9 过去。
看这张图就行了(下面第6点有误,应该是运行到光标处,而不是下一断点处)
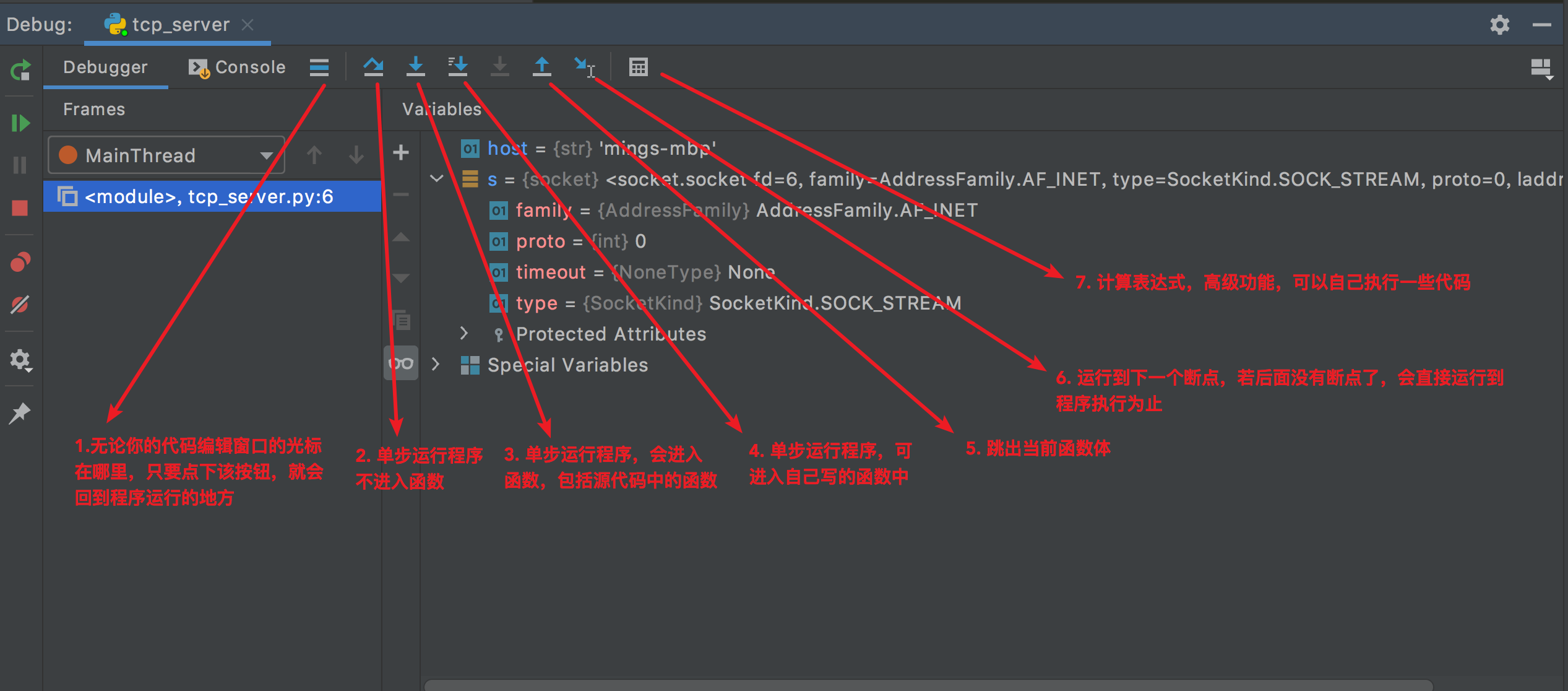
在程序控制窗口,共有 6 个按钮,他们的作用分别又是什么呢?同时看下面这张图就行了。
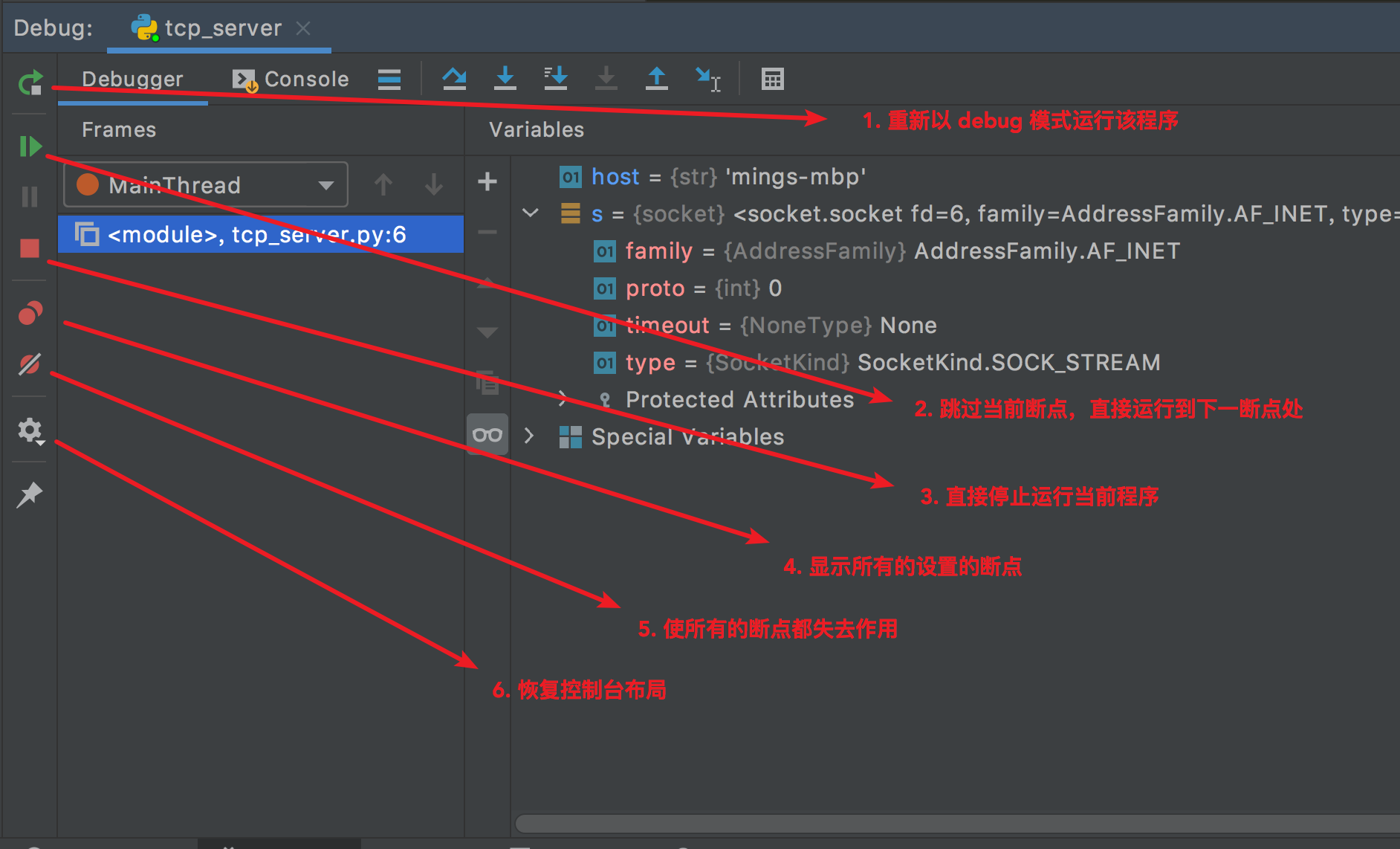
2. 调试相关的快捷键
⇧ + F9:调试当前文件
⌥ + ⇧ + F9:弹出菜单,让你选择调试哪一个文件
F8:单步执行,不进入函数
F7:单步执行,进入函数
⌥ + ⇧ +F7:单步执行,只进入自己写的函数
⇧ + F8:跳出函数体
F9:运行到下一断点
⌥ + F9:运行到光标处
⇧ + ⌘ + F8:查看所有设置的断点
⌘ + F8:切换断点(有断点则取消断点,没有则加上断点)
⌥ + F5:重新以调试模式运行
⌥ + F8 计算表达式(可以更改变量值使其生效)
9.2 【调试技巧】PyCharm 中指定参数调试程序
你在 Pycharm 运行你的项目,通常是怎么执行的?我的做法是,右键,然后点击 Run,或者使用快捷键 Shift + F10 。
有时候,在运行/调试脚本的时候,我们需要指定一些参数,这在命令行中,直接指定即可。
假设在命令行中,运行脚本的命令是这样
1 | |
对于刚使用 Pycharm 的同学,可能并不知道 Pycharm 也是可以指定参数的。点击下图位置
进入设置面板,在 Script parameters 中填入参数即可。
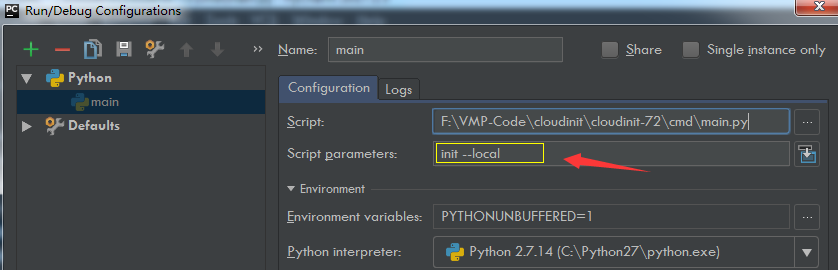
同时在上图的底部,你可以看到,这里可以很方便的切换 解释器,比你跑到这边来要容易得多吧
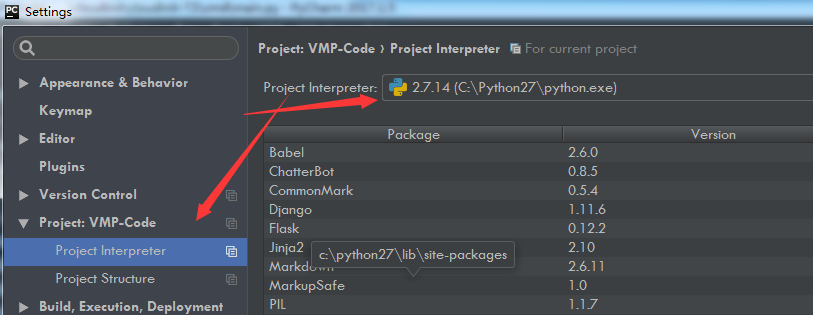
9.3 【调试技巧】PyCharm跑完后立即进入调试模式
假如我们在一个爬虫的项目中,会使用到 正则表达式 来匹配我们想要抓取的内容。正则这种东西,有几个人能够一步到位的呢,通常都需要经过很多次的调试才能按预期匹配。在我们改了一次正则后,运行了下,需要重新向网站抓取请求,才能发现没有匹配上,然后又改了一版,再次运行同样需要发起请求,结果还是发现还是没有匹配上,往往复复,正则不好的同学可能要进行几十次的尝试。
(上面这个例子可能不太贴切,毕竟是有很多种方法实现不用重新发请求,只是列举了一种很笨拙且低效的调试过程,你看看就好了)
而我们在这几十次的调试中,向同一网站发起请求都是没有意义的重复工作。如果在 Pycharm 中可以像 IPython Shell 和 Jupyter Notebook 那样,可以记住运行后所有的变量信息,可以在不需要重新运行项目或脚本,就可以通过执行命令表达式,来调整我们的代码,进行我们的正则调试。
答案当然是有。
假如我在调试如下几行简单的代码。在第 3 行处打了个断点。然后点击图示位置 Show Python Prompt 按钮。
就进入了 Python Shell 的界面,这个Shell 环境和我们当前运行的程序环境是打通的,变量之间可以互相访问,这下你可以轻松地进行调试了。
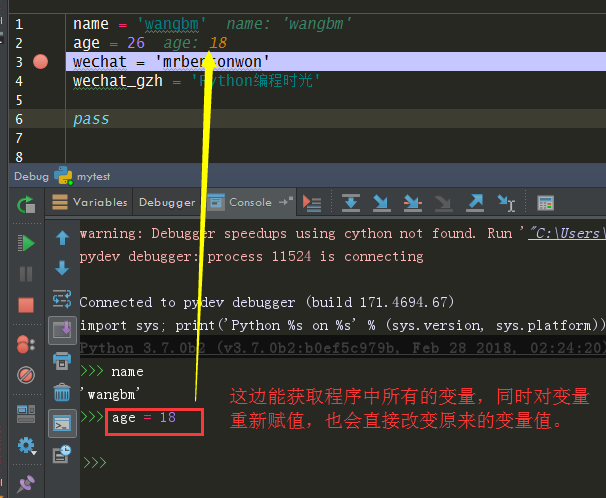
上面我们打了个断点,是为了方便说明这个效果。并不是说一定要打断点。如果不打断点,在脚本执行完成后,也仍然可以在这个界面查看并操作所有变量。
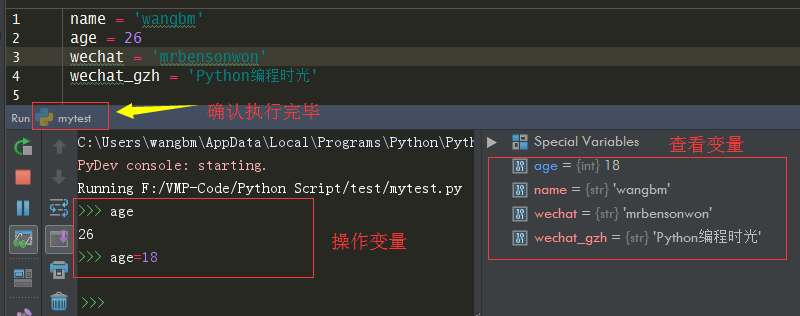
现在我们已经可以满足我们的调试的需求,但是每次运行脚本,都要手动点击 Show Python Prompt ,有点麻烦。嗯?其实这个有地方可以设置默认打开的。这个开关还比较隐秘,一般人还真发现不了。
你需要点击图示位置 Edit Configurations 处。
然后在这里打勾选中。
设置上之后,之后你每次运行后脚本后,都会默认为你存储所有变量的值,并为你打开 console 命令行调试界面。
除了上面这种方法,其实还有一种方法可以在调试过程中,执行命令表达式,而这种大家可能比较熟悉了,这边也提一下,就当是汇总一下。但是从功能上来说,是没有上面这种方法来得方便易用的。因为这种方法,必须要求你使用 debug 模式运行项目,并打断点。
使用方法就是,在你打了断点后,在图示位置处,点击右键使用 Evaluate Expression
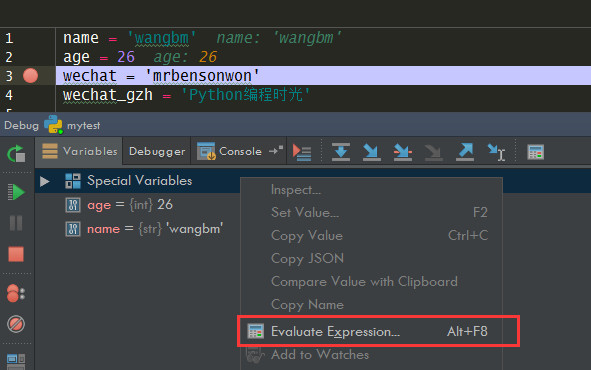
就弹出了一个 Evaluate Expression 窗口,这里 可以运行命令表达式,直接操作变量。
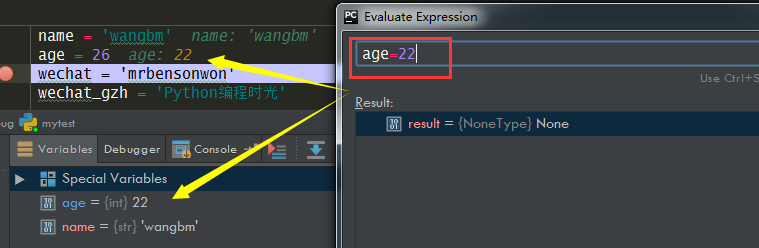
9.4 【调试技巧】脚本报错后立即进入调试模式
当你在使用 python xxx.py 这样的方法,执行 Python 脚本时,若因为代码 bug 导致异常未捕获,那整个程序便会终止退出。
这个时候,我们通常会去排查是什么原因导致的程序崩溃。
大家都知道,排查问题的思路,第一步肯定是去查看日志,若这个 bug 隐藏的比较深,只有在特定场景下才会现身,那么还需要开发者,复现这个 bug,方能优化代码。
复现有时候很难,有时候虽然简单,但是要伪造各种数据,相当麻烦。
如果有一种方法能在程序崩溃后,立马进入调试模式该有多好啊?
明哥都这么问了,那肯定是带着解决方案来的。
只要你在执行脚本行,加上 -i 参数,即可在脚本执行完毕后进入 Python Shell 模式,方便你进行调试。
具体演示如下:

需要注意的是:脚本执行完毕,有两种情况:
- 正常退出
- 异常退出
这两种都会进入 Python Shell,如果脚本并无异常,最终也会进入 Python Shell 模式,需要你手动退出

9.5 【调试技巧】使用 PDB 进行无界面调试
Pycharm 的图形化界面虽然好用,但是在某些场景中,是无法使用的。而 Python 本身已经给我们提供了一个调试神器 – pdb,可能你还不知道它,为了讲解这个神器,我写了这篇文章来帮助你轻松的理解它。
1. 准备文件
在调试之前先将这两个文件准备好(做为演示用),并放在同级目录中。
utils.py
1 | |
pdb_demo.py
1 | |
2. 进入调试模式
主要有两种方法
做为脚本调用,方法很简单,就像正常执行python脚本一样,只是多加了-m pdb
1 | |
使用这个方式进入调试模式,会在脚本的第一行开始单步调试。
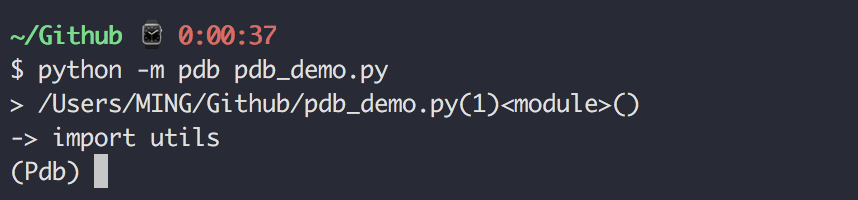
对于单文件的脚本并没有什么问题,如果是一个大型的项目,项目里有很多的文件,使用这种方式只能大大降低我们的效率。
一般情况下,都会直接在你需要的地方打一个断点,那如何打呢?
只需在你想要打断点的地方加上这两行。
1 | |
然后执行时,也不需要再指定-m pdb了,直接python pdb_demo.py ,就会直接在这个地方暂停。
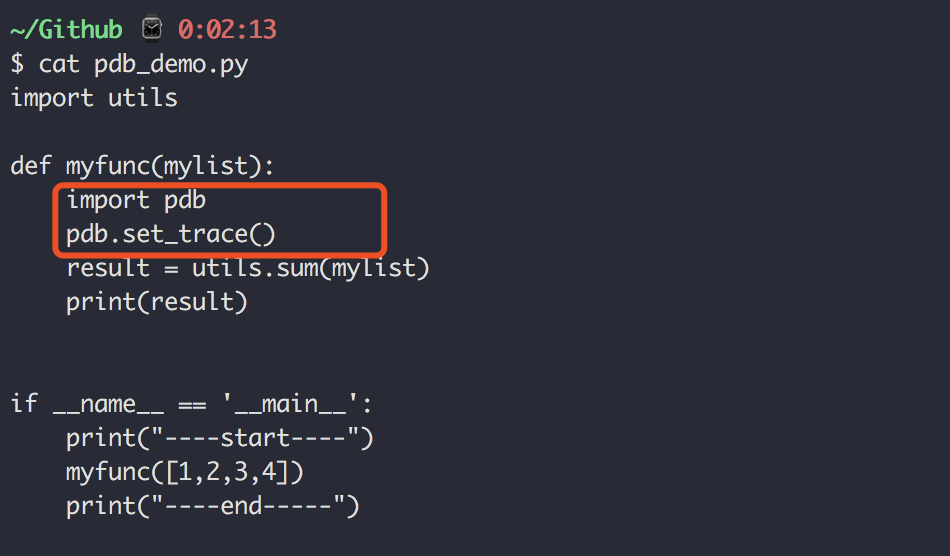
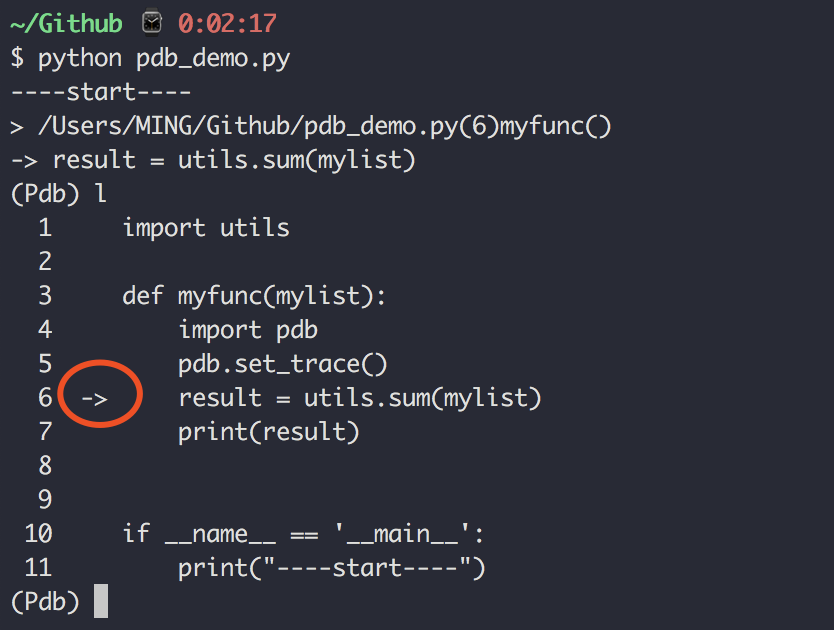
3. 调试指令
熟悉 Pycharm 的人都知道,我们执行下一步,执行到下一个断点是
同样的,pdb 也需要你更多记这样的命令。
当你看到pdb模式的标识符 (Pdb)时,就可以输入这样的命令。
我在这里将这些指令按使用频度分为三个等级。
最常用
| 指令 | 英文 | 解释 |
|---|---|---|
| n | Next | 下一步 |
| l | list | 列出当前断点处源码 |
| p | 打印变量 | |
| s | step into | 执行当前行,可以进入函数 |
| r | return | 运行完当前函数,返回结果 |
| c | continue | 执行到下一断点或者结束 |
| b | break | 设置断点 |
| q | quit | 退出程序 |
有时使用
| 指令 | 英文 | 解释 |
|---|---|---|
| a | args | 列出当前函数的参数 |
| pp | pprint | 一种可视化更好的打印 |
| j | jump | 跳到指定行 |
| cl | clear | 清除断点 |
| w | where | 打印当前堆栈 |
| u | up | 执行跳转到当前堆栈的上一层 |
| unt | until | 行数递增执行(忽略循环和函数) |
| ll | longlist | 列出更多的源码 |
| run/restart | run | 重新启动 debug(-m pdb) |
几乎不用
| 指令 | 英文 | 解释 |
|---|---|---|
| tbreak | temporary break | 临时断点 |
| disable | 停用断点 | |
| enable | 启用断点 | |
| alias | 设置别名 | |
| unalias | 删除别名 | |
| whatis | 打印对象类型 | |
| ignore | 设置忽略的断点 | |
| source | 列出给定对象的源码 |
其上全部是我翻译自官方文档,原文在这里:https://docs.python.org/3/library/pdb.html
其实你大可不必死记这些命令,忘记的时候,只要敲入help并回车,就可以看所有的指令了。
4. 开始调试
这里就几个最常用的指定,来演示一遍。

这个调试过程,我加了些注释,你应该能够很轻易地理解这种调试方式。
9.6 【调试技巧】如何调试已经运行的程序?
官方原始wiki:https://wiki.python.org/moin/DebuggingWithGdb
在CentOS 下,安装包过程,官方给的不够详细。这里记录一下
先安装 yum-utils,装完后就能使用 debuginfo
1 | |
然后使用debuginfo 安装 glibc,不过在安装之前,有可能 你需要先配置debuginfo的仓库,编辑/etc/yum.repos.d/CentOS-Debuginfo.repo
1 | |
然后就可以安装 glibc 了。
1 | |
最后安装 python-debuginfo
1 | |
9.7 【调试技巧】使用 PySnopper 调试疑难杂症
对于每个程序开发者来说,调试几乎是必备技能。
代码写到一半卡住了,不知道这个函数执行完的返回结果是怎样的?调试一下看看
代码运行到一半报错了,什么情况?怎么跟预期的不一样?调试一下看看
调试的方法多种多样,不同的调试方法适合不同的场景和人群。
- 如果你是刚接触编程的小萌新,对很多工具的使用还不是很熟练,那么 print 和 log 大法好
- 如果你在本地(Win或者Mac)电脑上开发,那么 IDE 的图形化界面调试无疑是最适合的;
- 如果你在服务器上排查BUG,那么使用 PDB 进行无图形界面的调试应该是首选;
- 如果你要在本地进行开发,但是项目的进行需要依赖复杂的服务器环境,那么可以了解下 PyCharm 的远程调试
除了以上,今天明哥再给你介绍一款非常好用的调试工具,它能在一些场景下,大幅度提高调试的效率, 那就是 PySnooper,它在 Github 上已经收到了 13k 的 star,获得大家的一致好评。
有了这个工具后,就算是小萌新也可以直接无门槛上手,从此与 print 说再见~
1. 快速安装
执行下面这些命令进行安装 PySnooper
1 | |
2. 简单案例
下面这段代码,定义了一个 demo_func 的函数,在里面生成一个 profile 的字典变量,然后去更新它,最后返回。
代码本身没有什么实际意义,但是用来演示 PySnooper 已经足够。
1 | |
现在我使用终端命令行的方式来运行它
1 | |
可以看到 PySnooper 把函数运行的过程全部记录了下来,包括:
- 代码的片段、行号等信息,以及每一行代码是何时调用的?
- 函数内局部变量的值如何变化的?何时新增了变量,何时修改了变量。
- 函数的返回值是什么?
- 运行函数消耗了多少时间?
而作为开发者,要得到这些如此详细的调试信息,你需要做的非常简单,只要给你想要调试的函数上带上一顶帽子(装饰器) – @pysnooper.snoop() 即可。
3. 详细使用
2.1 重定向到日志文件
@pysnooper.snoop() 不加任何参数时,会默认将调试的信息输出到标准输出。
对于单次调试就能解决的 BUG ,这样没有什么问题,但是有一些 BUG 只有在特定的场景下才会出现,需要你把程序放在后面跑个一段时间才能复现。
这种情况下,你可以将调试信息重定向输出到某一日志文件中,方便追溯排查。
1 | |
2.2 跟踪非局部变量值
PySnooper 是以函数为单位进行调试的,它默认只会跟踪函数体内的局部变量,若想跟踪全局变量,可以给 @pysnooper.snoop() 加上 watch 参数
1 | |
如此一来,PySnooper 会在 out["foo"] 值有变化时,也将其打印出来
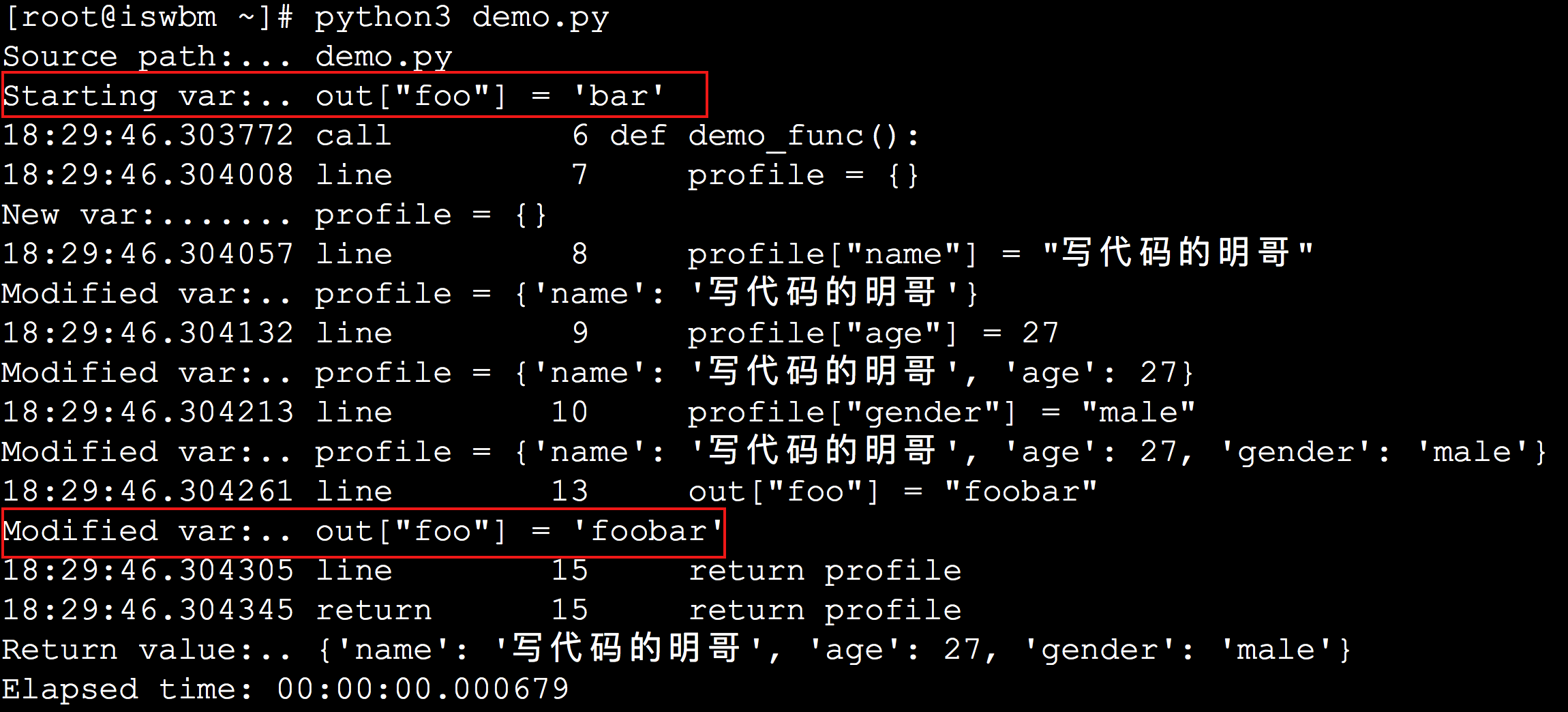
watch 参数,接收一个可迭代对象(可以是list 或者 tuple),里面的元素为字符串表达式,什么意思呢?看下面例子就知道了
1 | |
和 watch 相对的,pysnooper.snoop() 还可以接收一个函数 watch_explode,表示除了这几个参数外的其他所有全局变量都监控。
1 | |
2.3 设置跟踪函数的深度
当你使用 PySnooper 调试某个函数时,若该函数中还调用了其他函数,PySnooper 是不会傻傻的跟踪进去的。
如果你想继续跟踪该函数中调用的其他函数,可以通过指定 depth 参数来设置跟踪深度(不指定的话默认为 1)。
1 | |
2.4 设置调试日志的前缀
当你在使用 PySnooper 跟踪多个函数时,调试的日志会显得杂乱无章,不方便查看。
在这种情况下,PySnooper 提供了一个参数,方便你为不同的函数设置不同的标志,方便你在查看日志时进行区分。
1 | |
效果如下
2.5 设置最大的输出长度
默认情况下,PySnooper 输出的变量和异常信息,如果超过 100 个字符,被会截断为 100 个字符。
当然你也可以通过指定参数 进行修改
1 | |
您也可以使用max_variable_length=None它从不截断它们。
1 | |
2.6 支持多线程调试模式
PySnooper 同样支持多线程的调试,通过设置参数 thread_info=True,它就会在日志中打印出是在哪个线程对变量进行的修改。
1 | |
效果如下
2.7 自定义对象的格式输出
pysnooper.snoop() 函数有一个参数是 custom_repr,它接收一个元组对象。
在这个元组里,你可以指定特定类型的对象以特定格式进行输出。
这边我举个例子。
假如我要跟踪 person 这个 Person 类型的对象,由于它不是常规的 Python 基础类型,PySnooper 是无法正常输出它的信息的。
因此我在 pysnooper.snoop() 函数中设置了 custom_repr 参数,该参数的第一个元素为 Person,第二个元素为 print_persion_obj 函数。
PySnooper 在打印对象的调试信息时,会逐个判断它是否是 Person 类型的对象,若是,就将该对象传入 print_persion_obj 函数中,由该函数来决定如何显示这个对象的信息。
1 | |
完整的代码如下
1 | |
运行一下,观察一下效果。
如果你要自定义格式输出的有很多个类型,那么 custom_repr 参数的值可以这么写
1 | |
还有一点我提醒一下,元组的第一个元素可以是类型(如类名Person 或者其他基础类型 list等),也可以是一个判断对象类型的函数。
也就是说,下面三种写法是等价的。
1 | |
以上就是明哥今天给大家介绍的一款调试神器(PySnooper) 的详细使用手册,是不是觉得还不错?## 9.8 【调试技巧】使用 PyCharm 进行远程调试
一般情况下,我们开发调试都是在个人PC上完成,遇到问题,开一下 Pycharm 的调试器,很快就能找到问题所在。
可有些时候,项目代码的运行会对运行环境有依赖,必须在部署了相关依赖组件的服务器上才可以运行,这就直接导致了我们不能在本地进行调试。
对于这种特殊的场景,就我所知,有如下两种解决方案:
- pdb
- Remote Debug
本篇文章会先讲第二种方案,它是 专业版Pycharm 才开放的功能,需要你安装专业版的Pycharm,具体升级破解步骤,请自行 Google,这里不涉及。
远程调试的意思,是让我们可以在我们在 PC 上用 Pycharm 的图形化界面来进行调试代码,它和本地调试没有太大的区别,原来怎么调试的现在还是怎么调试。
区别就在于,本地调试不需要事前配置,只要你的代码准备好了,随时可以开始 Debug 。而远程调试需要不少前置步骤,这些设置过程,也是本文的主要内容。
1. 新建一个项目
首先,要在Pycharm中新建一个空的项目,后面我们拉服务器上的项目代码就会放置在这个项目目录下。我这边的名字是 NOVA,你可以自己定义。
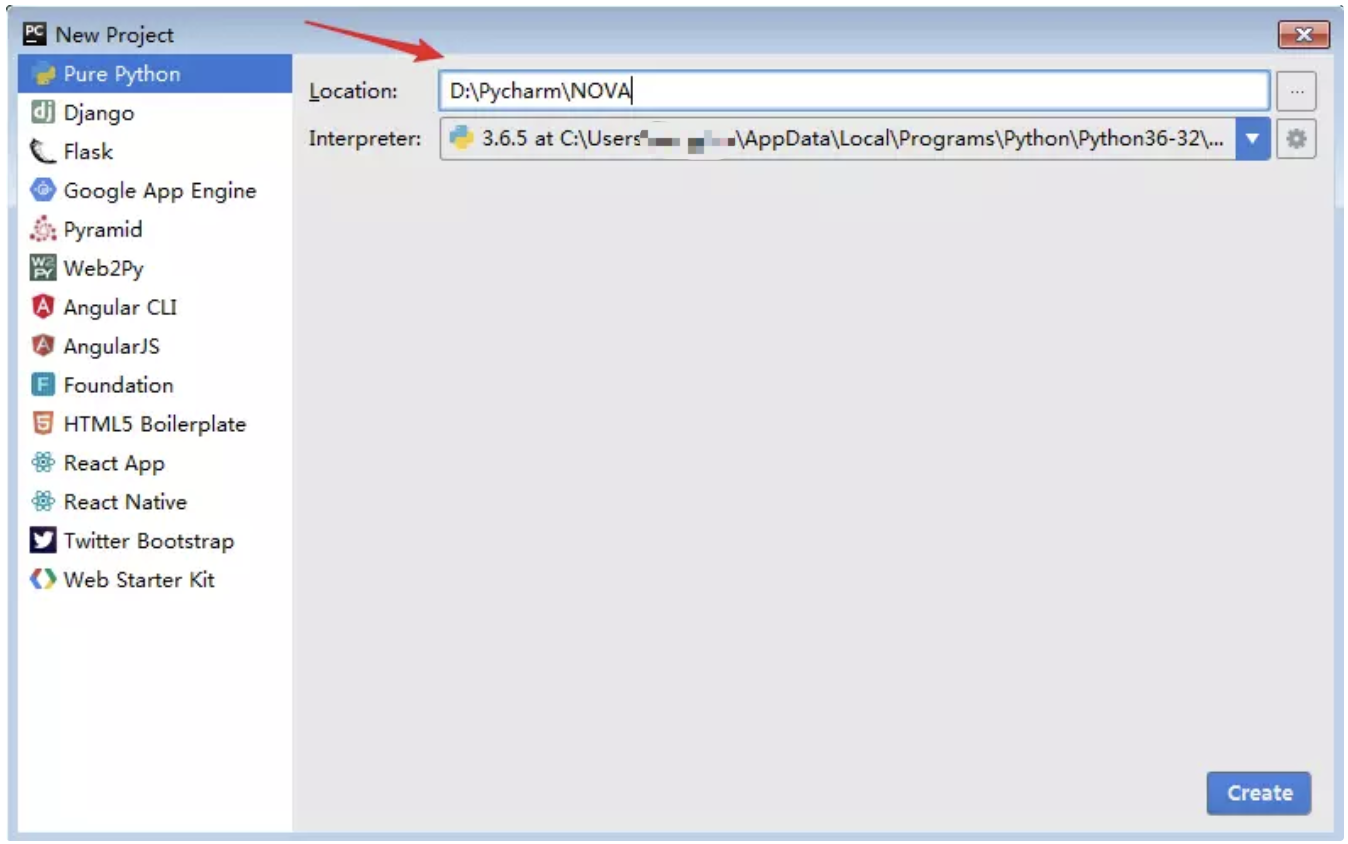
2. 配置连接服务器
Tools -> Deployment -> configuration
添加一个Server
Name:填你的服务器的IP
Type:设定为SFTP
点击OK后,进入如下界面,你可以按我的备注,填写信息:
- SFTP host:公网ip
- Port:服务器开放的ssh端口
- Root path:你要调试的项目代码目录
- Username:你登陆服务器所用的用户
- Auth type:登陆类型,若用密码登陆的就是Password
- Password:选密码登陆后,这边输入你的登陆密码,可以选择保存密码。
这里请注意,要确保你的电脑可以ssh连接到你的服务器,不管是密钥登陆还是密码登陆,如果开启了白名单限制要先解除。
填写完成后,切换到Mappings选项卡,在箭头位置,填写\
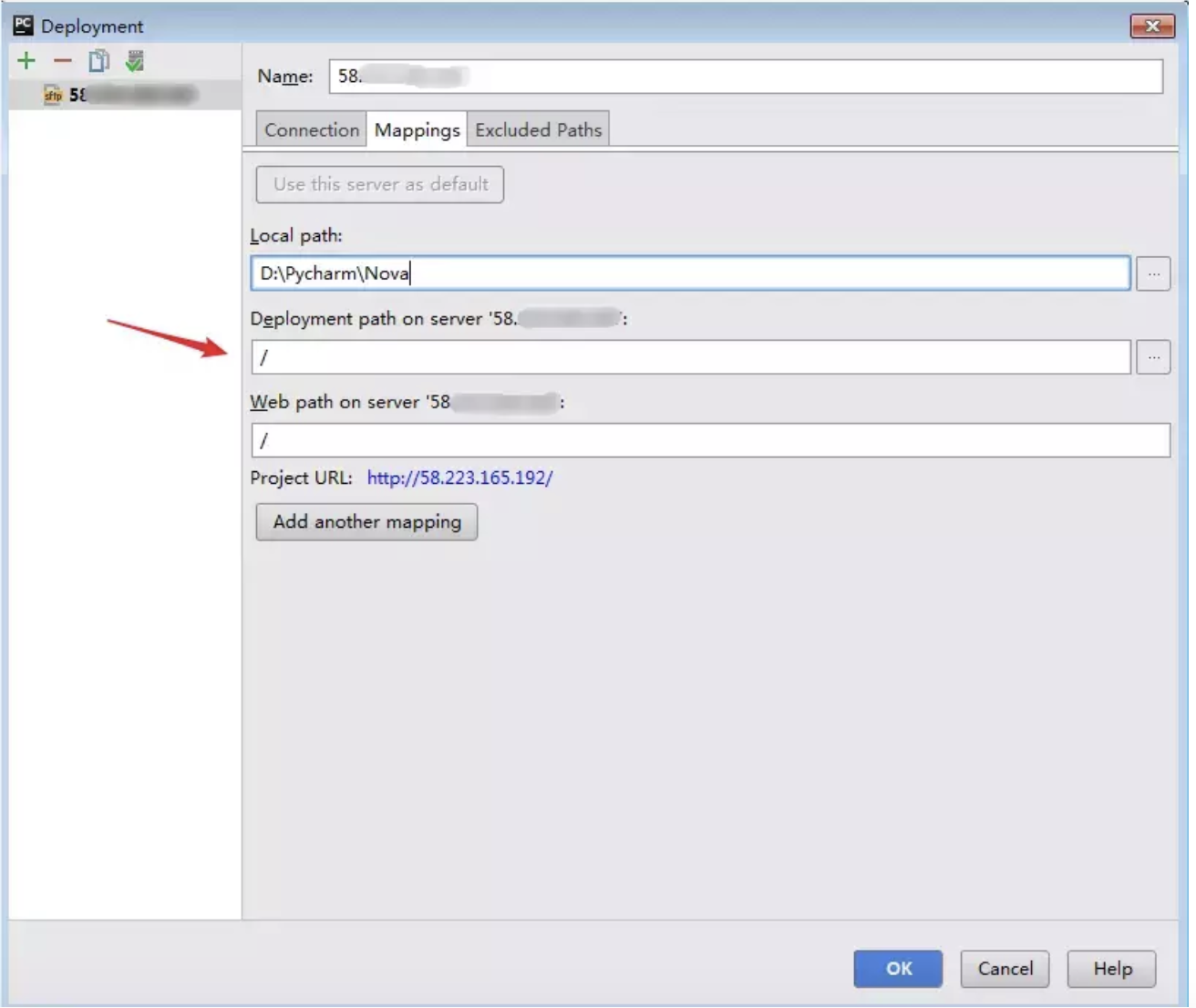
以上服务器信息配置,全部正确填写完成后,点击OK
接下来,我们要连接远程服务器了。
Tools -> Deployment -> Browse Remote Host
3. 下载项目代码
如果之前填写的服务器登陆信息准确无误的话,现在就可以看到远程的项目代码。
选择下载远程代码要本地。
下载完成提示。
现在的IDE界面应该是这样子的。
4. 下载远程解释器
为什么需要这步呢?
远程调试是在远端的服务器上运行的,它除了依赖其他组件之外,还会有一些很多Python依赖包我们本地并没有。
进入 File -> Settings
按图示,添加远程解释器。
填写远程服务器信息,跟之前的一样,不再赘述。
点击OK后,会自动下载远程解释器。如果你的项目比较大,这个时间可能会比较久,请耐心等待。
5. 添加程序入口
因为我们要在本地DEBUG,所以你一定要知道你的项目的入口程序。如果这个入口程序已经包含在你的项目代码中,那么请略过这一步。
如果没有,就请自己生成入口程序。
比如,我这边的项目,在服务器上是以一个服务运行的。而我们都知道服务的入口是Service文件。cat /usr/lib/systemd/system/openstack-nova-compute.service
1 | |
看到那个ExecStart没有?那个就是我们程序的入口。
我们只要将其拷贝至我们的Pycharm中,并向远程同步该文件。
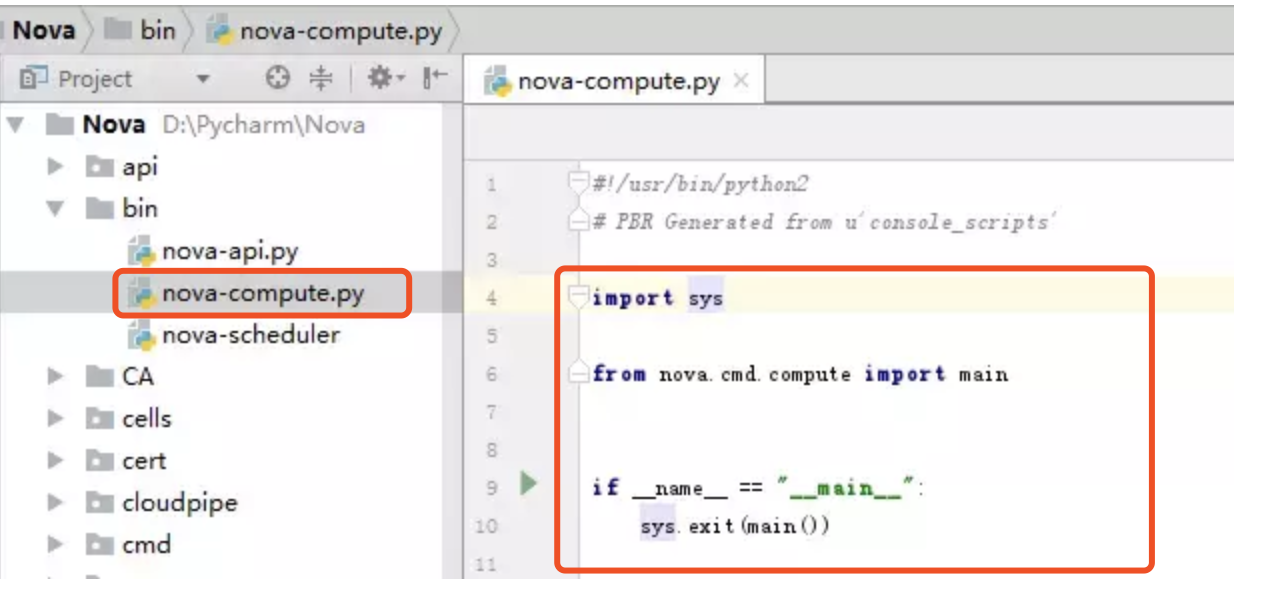
6. 调试前设置
开启代码自动同步,这样,我们对代码的修改Pycharm都能识别,并且为我们提交到远程服务器。
开启 Gevent compatible,如果不开启,在调试过程中,很可能出现无法调试,或者无法追踪/查看变量等问题。
7. 开始调试代码
在你的程序入口文件处,点击右键,选择Debug即可。
如果你的程序入口,需要引入参数,这是经常有的事,可以的这里配置。
配置完点击保存即可。
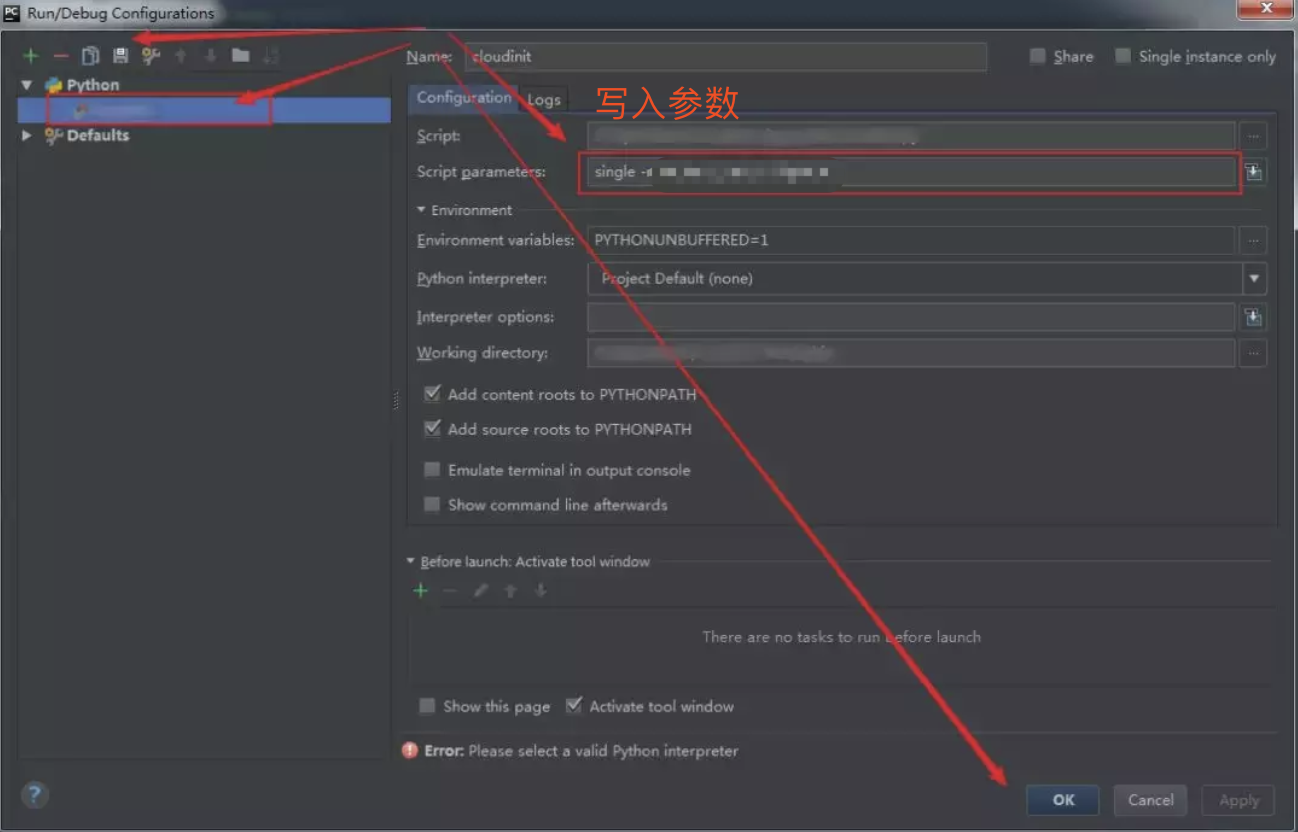
8. 友情提醒
按照文章的试调试代码,会自动同步代码至远端,千万不要在生产环境使用,一定要在开发环境中使用,否则后果自负。
调试工具给了程序员提供了很大的便利,但还是希望你不要过度依赖。尽量在每次写代码的时候,都追求一次成型,提高自己的编码能力。
9.10 【调试技巧】报错后直接切换pdb调试
前面的文章里介绍了两种 pdb 的调试入口,也是大部分所熟知的。
这里再带大家回顾一下
第一种:指定 -m pdb 来开启
1 | |
第二种:使用 pdb.set_trace() 在代码中设置断点
1 | |
但其实,pdb 还另外两种调试方法,第一种方法,可能有 99% 的开发者都没用过,甚至连见过都没有。
这两种方法,是配合 Python Console 的交互界面来实现的。
首先我准备好一个名为 utils.py 的 Python文件,里面定义了一个 sum 的工具函数(仅作演示用)。
1 | |
然后在终端敲入 Python 进入 Console 的模式,导入这个模块,并调用 sum 函数,在正常情况下,函数可以正常工作。
1 | |
但如果你的参数类型传成了 str,函数就会报错啦~
1 | |
由于这里的报错是我刻意触发的,从报错来看,是很容易定位的。
但是在实际应用中,难免会遇到一些无法从报错信息直接判断 bug 所在的情况。
这个时候,如果可以在报错后,切换到 pdb 的调试模式就好了~
事实上,pdb 是支持这种用法的。
只要你在当前的会话中,导入 pdb,再执行 pdb.pn(),就可以切换到熟悉的 pdb 调试界面,并在抛错的地方打上断点,然后你就可以任意的查看运行时的变量信息。

如果你不是想等报错了再调试,而是一开始就想进入调试模式,可以使用 pdb.runcall() 函数
有的同学可能还会想到 pdb.run() 和 pdb.runeval() 这两个函数,但这两种方法,是需要提前在函数调试断点的,这就比较麻烦了,一般情况下不推荐使用。
综上所述,今天 给大家介绍了两种新的 pdb 调试入口:
pdb.pm():在出错后直接切换到调试模式,并定位到报错位置。 – 今天的重点pdb.runcall():可以在不设置断点的情况下,直接调试代码片段。
第十章:并发编程
10.1 【并发编程】从性能角度初探并发编程
1. 基本概念
在开始讲解理论知识之前,先过一下几个基本概念。虽然咱是进阶教程,但我也希望写得更小白,更通俗易懂。
串行:一个人在同一时间段只能干一件事,譬如吃完饭才能看电视;并行:一个人在同一时间段可以干多件事,譬如可以边吃饭边看电视;
在Python中,多线程 和 协程 虽然是严格上来说是串行,但却比一般的串行程序执行效率高得很。
一般的串行程序,在程序阻塞的时候,只能干等着,不能去做其他事。就好像,电视上播完正剧,进入广告时间,我们却不能去趁广告时间是吃个饭。对于程序来说,这样做显然是效率极低的,是不合理的。
当然,学完这个课程后,我们就懂得,利用广告时间去做其他事,灵活安排时间。这也是我们多线程和协程 要帮我们要完成的事情,内部合理调度任务,使得程序效率最大化。
虽然 多线程 和 协程 已经相当智能了。但还是不够高效,最高效的应该是一心多用,边看电视边吃饭边聊天。这就是我们的 多进程 才能做的事了。
为了更帮助大家更加直观的理解,在网上找到两张图,来生动形象的解释了多线程和多进程的区别。(侵删)
多线程,交替执行,另一种意义上的串行。多进程,并行执行,真正意义上的并发。
2. 单线程VS多线程VS多进程
文字总是苍白无力的,不如用代码直接来测试一下。
在开始之前呢,我要声明一下,本文作为并发章节的第一篇文章,只为了让你对单线程、多线程、多进程有个直观的了解。因此下面的代码中,会有多线程和多进程的的知识点,这些知识点在后面几节才会讲到,如果你看不明白也没有关系。
我的实验环境配置如下

开始对比之前,首先定义四种类型的场景
- CPU计算密集型
- 磁盘IO密集型
- 网络IO密集型
- 【模拟】IO密集型
为什么是这几种场景,这和多线程 多进程的适用场景有关。结论里,我再说明。
1 | |
比拼的指标,我们用时间来考量。时间耗费得越少,说明效率越高。
为了方便,使得代码看起来,更加简洁,我这里先定义是一个简单的 时间计时器 的装饰器。
如果你对装饰器还不是很了解,也没关系,你只要知道它是用于 计算函数运行时间的东西就可以了。
1 | |
第一步,先来看看单线程的
1 | |
看看结果
1 | |
第二步,再来看看多线程的
1 | |
看看结果
1 | |
第三步,最后来看看多进程
1 | |
看看结果
1 | |
3. 性能对比成果总结
将结果汇总一下,制成表格。
我们来分析下这个表格。
首先是CPU密集型,多线程以对比单线程,不仅没有优势,显然还由于要不断的加锁释放GIL全局锁,切换线程而耗费大量时间,效率低下,而多进程,由于是多个CPU同时进行计算工作,相当于十个人做一个人的作业,显然效率是成倍增长的。
然后是IO密集型,IO密集型可以是磁盘IO,网络IO,数据库IO等,都属于同一类,计算量很小,主要是IO等待时间的浪费。通过观察,可以发现,我们磁盘IO,网络IO的数据,多线程对比单线程也没体现出很大的优势来。这是由于我们程序的的IO任务不够繁重,所以优势不够明显。
所以我还加了一个「模拟IO密集型」,用sleep来模拟IO等待时间,就是为了体现出多线程的优势,也能让大家更加直观的理解多线程的工作过程。单线程需要每个线程都要sleep(2),10个线程就是20s,而多线程,在sleep(2)的时候,会切换到其他线程,使得10个线程同时sleep(2),最终10个线程也就只有2s.
可以得出以下几点结论
- 单线程总是最慢的,多进程总是最快的。
- 多线程适合在IO密集场景下使用,譬如爬虫,网站开发等
- 多进程适合在对CPU计算运算要求较高的场景下使用,譬如大数据分析,机器学习等
- 多进程虽然总是最快的,但是不一定是最优的选择,因为它需要CPU资源支持下才能体现优势
10.2 【并发编程】创建多线程的几种方法
今天的内容会比较基础,主要是为了让新手也能无障碍地阅读,所以还是要再巩固下基础。学完了基础,你们也就能很顺畅地跟着我的思路理解以后的文章。
经过总结,Python创建多线程主要有如下两种方法:
- 函数
- 类
接下来,我们就来揭开多线程的神秘面纱。
1. 用函数创建多线程
在Python3中,Python提供了一个内置模块 threading.Thread,可以很方便地让我们创建多线程。
threading.Thread() 一般接收两个参数:
- 线程函数名:要放置线程让其后台执行的函数,由我们自已定义,注意不要加
(); - 线程函数的参数:线程函数名所需的参数,以元组的形式传入。若不需要参数,可以不指定。
举个例子
1 | |
可以看到输出
1 | |
2. 用类创建多线程
相比较函数而言,使用类创建线程,会比较麻烦一点。
首先,我们要自定义一个类,对于这个类有两点要求,
- 必须继承
threading.Thread这个父类; - 必须复写
run方法。
这里的 run 方法,和我们上面线程函数的性质是一样的,可以写我们的业务逻辑程序。在 start() 后将会调用。
来看一下例子
为了方便对比,run函数我复用上面的main。
1 | |
当然结果也是一样的。
1 | |
3. 线程对象的方法
上面介绍了当前 Python 中创建线程两种主要方法。
创建线程是件很容易的事,但要想用好线程,还需要学习线程对象的几个函数。
经过我的总结,大约常用的方法有如下这些:
1 | |
10.3 【并发编程】谈谈线程中的“锁机制”
1. 什么是锁?
在开发中,锁 可以理解为通行证。
当你对一段逻辑代码加锁时,意味着在同一时间有且仅能有一个线程在执行这段代码。
在 Python 中的锁可以分为两种:
- 互斥锁
- 可重入锁
2. 互斥锁的使用
来简单看下代码,学习如何加锁,获取钥匙,释放锁。
1 | |
需要注意的是,lock.acquire() 和 lock.release()必须成对出现。否则就有可能造成死锁。
很多时候,我们虽然知道,他们必须成对出现,但是还是难免会有忘记的时候。
为了,规避这个问题。我推荐使用使用上下文管理器来加锁。
1 | |
with 语句会在这个代码块执行前自动获取锁,在执行结束后自动释放锁。
3. 为何要使用锁?
你现在肯定还是一脸懵逼,这么麻烦,我不用锁不行吗?有的时候还真不行。
那么为了说明锁存在的意义。我们分别来看下,不用锁的情形有怎样的问题。
定义两个函数,分别在两个线程中执行。这两个函数 共用 一个变量 n 。
1 | |
看代码貌似没什么问题,执行下看看输出
1 | |
是不是很乱?完全不是我们预想的那样。
解释下这是为什么?因为两个线程共用一个全局变量,又由于两线程是交替执行的,当job1 执行三次 +1 操作时,job2就不管三七二十一 给n做了+10操作。两个线程之间,执行完全没有规矩,没有约束。所以会看到输出当然也很乱。
加了锁后,这个问题也就解决,来看看
1 | |
由于job1的线程,率先拿到了锁,所以在for循环中,没有人有权限对n进行操作。当job1执行完毕释放锁后,job2这才拿到了锁,开始自己的for循环。
看看执行结果,真如我们预想的那样。
1 | |
这里,你应该也知道了,加锁是为了对锁内资源(变量)进行锁定,避免其他线程篡改已被锁定的资源,以达到我们预期的效果。
为了避免大家忘记释放锁,后面的例子,我将都使用with上下文管理器来加锁。大家注意一下。
4. 可重入锁(RLock)
有时候在同一个线程中,我们可能会多次请求同一资源,俗称锁嵌套。
如果还是按照常规的做法,会造成死锁的。比如,下面这段代码,你可以试着运行一下。会发现并没有输出结果。
1 | |
是因为第二次获取锁(通行证)时,发现锁(通行证)已经被同一线程的人拿走了,拿东西总有个先来后到,别人拿走了,你要想用,你就得干等着,直到有人归还锁(通行证),假如别人一直不归还,那程序就会在这里一直阻塞。
上面的代码中,使用了嵌套锁,在锁还没有释放的时候,又再一次请求锁,这就当然会造成死锁了。
那么如何解决这个问题呢?
threading模块除了提供Lock锁之外,还提供了一种可重入锁RLock,专门来处理这个问题。
1 | |
执行一下,发现已经有输出了。
1 | |
需要注意的是,可重入锁(RLock),只在同一线程里放松对锁(通行证)的获取,意思是,只要在同一线程里,程序就当你是同一个人,这个锁就可以复用,其他的话与Lock并无区别。
5. 防止死锁的加锁机制
在编写多线程程序时,可能无意中就会写了一个死锁。可以说,死锁的形式有多种多样,但是本质都是相同的,都是对资源不合理竞争的结果。
以本人的经验总结,死锁通常以下几种
- 同一线程,嵌套获取同把互斥锁,造成死锁。
- 多个线程,不按顺序同时获取多个锁。造成死锁
对于第一种,上面已经说过了,使用可重入锁。
主要是第二种。可能你还没明白,是如何死锁的。
举个例子。
线程1,嵌套获取A,B两个锁,线程2,嵌套获取B,A两个锁。
由于两个线程是交替执行的,是有机会遇到线程1获取到锁A,而未获取到锁B,在同一时刻,线程2获取到锁B,而未获取到锁A。由于锁B已经被线程2获取了,所以线程1就卡在了获取锁B处,由于是嵌套锁,线程1未获取并释放B,是不能释放锁A的,这是导致线程2也获取不到锁A,也卡住了。两个线程,各执一锁,各不让步。造成死锁。
经过数学证明,只要两个(或多个)线程获取嵌套锁时,按照固定顺序就能保证程序不会进入死锁状态。
那么问题就转化成如何保证这些锁是按顺序的?
有两个办法
- 人工自觉,人工识别。
- 写一个辅助函数来对锁进行排序。
第一种,就不说了。
第二种,可以参考如下代码
1 | |
如何使用呢?
1 | |
看到没有,表面上thread_1的先获取锁x,再获取锁y,而thread_2是先获取锁y,再获取x。
但是实际上,acquire函数,已经对x,y两个锁进行了排序。所以thread_1,hread_2都是以同一顺序来获取锁的,是不是造成死锁的。
6. 饱受争议的GIL(全局锁)
在第一节的时候,我就和大家介绍到,多线程和多进程是不一样的。
多进程是真正的并行,而多线程是伪并行,实际上他只是交替执行。
是什么导致多线程,只能交替执行呢?是一个叫GIL(Global Interpreter Lock,全局解释器锁)的东西。
什么是GIL呢?
任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
需要注意的是,GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。而Python解释器,并不是只有CPython,除它之外,还有PyPy,Psyco,JPython,IronPython等。
在绝大多数情况下,我们通常都认为 Python == CPython,所以也就默许了Python具有GIL锁这个事。
都知道GIL影响性能,那么如何避免受到GIL的影响?
- 使用多进程代替多线程。
- 更换Python解释器,不使用CPython
10.4 【并发编程】线程消息通信机制
前面我已经向大家介绍了,如何使用创建线程,启动线程。相信大家都会有这样一个想法,线程无非就是创建一下,然后再start()下,实在是太简单了。
可是要知道,在真实的项目中,实际场景可要我们举的例子要复杂的多得多,不同线程的执行可能是有顺序的,或者说他们的执行是有条件的,是要受控制的。如果仅仅依靠前面学的那点浅薄的知识,是远远不够的。
那今天,我们就来探讨一下如何控制线程的触发执行。
要实现对多个线程进行控制,其实本质上就是消息通信机制在起作用,利用这个机制发送指令,告诉线程,什么时候可以执行,什么时候不可以执行,执行什么内容。
经过我的总结,线程中通信方法大致有如下三种:
- threading.Event
- threading.Condition
- queue.Queue
接下来我们来一一探讨下。
1. Event事件
Python提供了非常简单的通信机制 Threading.Event,通用的条件变量。多个线程可以等待某个事件的发生,在事件发生后,所有的线程都会被激活。
关于Event的使用也超级简单,就三个函数
1 | |
举个例子来看下。
1 | |
执行一下,看看结果
1 | |
可见在所有线程都启动(start())后,并不会执行完,而是都在self.event.wait()止住了,需要我们通过event.set()来给所有线程发送执行指令才能往下执行。
2. Condition
Condition和Event 是类似的,并没有多大区别。
同样,Condition也只需要掌握几个函数即可。
1 | |
举个网上一个比较趣的捉迷藏的例子来看看
1 | |
通过cond来通信,阻塞自己,并使对方执行。从而,达到有顺序的执行。
看下结果
1 | |
3. Queue队列
最后一个,队列,它是本节的重点,因为它是我们日常开发中最使用频率最高的。
从一个线程向另一个线程发送数据最安全的方式可能就是使用 queue 库中的队列了。创建一个被多个线程共享的 Queue 对象,这些线程通过使用put() 和 get() 操作来向队列中发送和获取元素。
同样,对于Queue,我们也只需要掌握几个函数即可。
1 | |
以下三个方法,知道就好,一般不需要使用
1 | |
函数会比之前的多一些,同时也从另一方面说明了其功能更加丰富。
我来举个老师点名的例子。
1 | |
运行结果如下
1 | |
其实 queue 还有一个很重要的方法,Queue.task_done()
如果不明白它的原理,我们在写程序,就很有可能卡死。
当我们使用 Queue.get() 从队列取出数据后,这个数据有没有被正常消费,是很重要的。
如果数据没有被正常消费,那么Queue会认为这个任务还在执行中,此时你使用 Queue.join() 会一直阻塞,即使此时你的队列里已经没有消息了。
那么如何解决这种一直阻塞的问题呢?
就是在我们正常消费完数据后,记得调用一下 Queue.task_done(),说明队列这个任务已经结束了。
当队列内部的任务计数器归于零时,调用 Queue.join() 就不会再阻塞了。
要理解这个过程,请参考 https://python.iswbm.com/c02/c02_06.html 里自定义线程池的的例子。
4. 消息队列的先进先出
消息队列可不是只有queue.Queue这一个类,除它之外,还有queue.LifoQueue和queue.PriorityQueue这两个类。
从名字上,对于他们之间的区别,你大概也能猜到一二吧。
queue.Queue:先进先出队列queue.LifoQueue:后进先出队列queue.PriorityQueue:优先级队列
先来看看,我们的老朋友,queue.Queue。
所谓的先进先出(FIFO,First in First Out),就是先进入队列的消息,将优先被消费。
这和我们日常排队买菜是一样的,先排队的人肯定是先买到菜。
用代码来说明一下
1 | |
看看输出,符合我们先进先出的预期。存入队列的顺序是01234,被消费的顺序也是01234。
1 | |
再来看看Queue.LifoQueue,后进先出,就是后进入消息队列的,将优先被消费。
这和我们羽毛球筒是一样的,最后放进羽毛球筒的球,会被第一个取出使用。
用代码来看下
1 | |
来看看输出,符合我们后进后出的预期。存入队列的顺序是01234,被消费的顺序也是43210。
1 | |
最后来看看Queue.PriorityQueue,优先级队列。
这和我们日常生活中的会员机制有些类似,办了金卡的人比银卡的服务优先,办了银卡的人比不办卡的人服务优先。
来用代码看一下
1 | |
来看看输出,符合我们的预期。我们存入入队列的顺序是25341,对应的优先级也是25341,可是被消费的顺序丝毫不受传入顺序的影响,而是根据指定的优先级来消费。
1 | |
5. 总结一下
学习了以上三种通信方法,我们很容易就能发现Event 和 Condition 是threading模块原生提供的模块,原理简单,功能单一,它能发送 True 和 False 的指令,所以只能适用于某些简单的场景中。
而Queue则是比较高级的模块,它可能发送任何类型的消息,包括字符串、字典等。其内部实现其实也引用了Condition模块(譬如put和get函数的阻塞),正是其对Condition进行了功能扩展,所以功能更加丰富,更能满足实际应用。
10.5 【并发编程】线程中的信息隔离
上一篇我们说,线程与线程之间要通过消息通信来控制程序的执行。
讲完了消息通信,今天就来探讨下线程里的信息隔离是如何做到的。
1. 初步认识信息隔离
什么是信息隔离?
比如说,咱有两个线程,线程A里的变量,和线程B里的变量值不能共享。这就是信息隔离。
你可能要说,那变量名取不一样不就好啦?
是的,如果所有的线程都不是由一个class实例化出来的同一个对象,确实是可以。这个问题我们暂且挂着,后面我再说明。
那么,如何实现信息隔离呢?
在Python中,其提供了threading.local这个类,可以很方便的控制变量的隔离,即使是同一个变量,在不同的线程中,其值也是不能共享的。
用代码来看下
1 | |
来看看输出结果
1 | |
从输出来看,我们可以知道,local实际是一个字典型的对象,其内部可以以key-value的形式存入你要做信息隔离的变量。local实例可以是全局唯一的,只有一个。因为你在给local存入或访问变量时,它会根据当前的线程的不同从不同的存储空间存入或获取。
基于此,我们可以得出以下三点结论:
- 主线程中的变量,不会因为其是全局变量,而被子线程获取到;
- 主线程也不能获取到子线程中的变量;
- 子线程与子线程之间的变量也不能互相访问。
所以如果想在当前线程保存一个全局值,并且各自线程(包括主线程)互不干扰,使用local类吧。
2. 信息隔离的意义何在
细心的你,一定已经发现了,上面那个例子,即使我们不用threading.local来做信息隔离,两个线程self.getName()本身就是隔离的,没有任何关系的。因为这两个线程是由一个class实例出的两个不同的实例对象。自然是可以不用做隔离,因为其本身就是隔离的。
但是,现实开发中。不可排除有多个线程,是由一个class实例出的同一个实例对象而实现的。
譬如,现在新手特别喜欢的爬虫项目。通常都是先给爬虫一个主页,然后获取主页下的所有链接,对这个链接再进行遍历,一直往下,直到把所有的链接都爬完,获取到我们所需的内容。
由于单线程的爬取效率实在是太低了,我们考虑使用多线程来工作。先使用socket和www.sina.con.cn建立一个TCP连接。然后在这个连接的基础上,对主页上的每个链接(我们这里只举news.sina.com.cn和blog.sina.com.cn这两个子链接做例子)创建一个线程,这样效率就高多了。
友情提醒:
以下代码,若要理解,可能需要你了解下socket的网络编程相关内容。我在前几天的文章中有发布一篇相关的文章,没有基础的同学可以先去看看那篇文章。
1 | |
输出结果
1 | |
如果是在这种场景下,要做到线程之间的状态信息的隔离,就肯定要借助threading.local,所以threading.local的存在是有存在的意义的。其他还有很多场景是必须借助threading.local才能实现的,而这些就要靠你们在真正的业务开发中去发现咯。
10.6 【并发编程】线程池创建的几种方法
1. 线程池的创建
使用内置模块
在使用多线程处理任务时也不是线程越多越好,由于在切换线程的时候,需要切换上下文环境,依然会造成cpu的大量开销。为解决这个问题,线程池的概念被提出来了。预先创建好一个合理数量的线程池,让过来的任务立刻能够使用,就形成了线程池。
在Python3中,创建线程池是通过concurrent.futures函数库中的ThreadPoolExecutor类来实现的。
1 | |
创建线程池还可以使用更优雅的方式,就是使用上下文管理器
1 | |
直接运行代码,从输出可以看出,前面我们设置线程池最大线程数,会保证“同时”仅有五个线程在工作。
1 | |
示例完毕,来说明一下:
使用 with 语句 ,通过 ThreadPoolExecutor 构造实例,同时传入 max_workers 参数来设置线程池中最多能同时运行的线程数目。
使用 submit 函数来提交线程需要执行的任务到线程池中,并返回该任务的句柄(类似于文件、画图),注意 submit() 不是阻塞的,而是立即返回。
通过使用 done() 方法判断该任务是否结束。上面的例子可以看出,提交任务后立即判断任务状态,显示四个任务都未完成。在延时2.5后,task1 和 task2 执行完毕,task3 仍在执行中。
使用 result() 方法可以获取任务的返回值。
自定义线程池
除了使用上述第三方模块的方法之外,我们还可以自己结合前面所学的消息队列来自定义线程池。
这里我们就使用queue来实现一个上面同样效果的例子,大家感受一下。
1 | |
输出是和上面是完全一样的效果
1 | |
构建线程池的方法,是可以很灵活的,大家有空可以自己多研究。但是建议只要掌握一种自己熟悉的,能快速上手的就好了。
10.7 【并发编程】从 yield 开始入门协程
简单介绍 yield
本篇文章会先向你介绍一个陌生的 Python 关键词,他和 return 就像一对新兄弟,有相似之处,又各有不同。
相似的是:yield 和 return 都可以在一个函数里将值返回给调用方;
不同的是:return 后,函数运行就终止了,而 yield 则只是暂停运行。
关于 yield 的简单使用,请先看如下例子
1 | |
重点有如下几个:
- 含有 yield 的函数,不再是普通的函数,直接调用含有 yield 的函数,返回的是一个生成器对象(generator object)
- 可以使用 for 循环(实际还可以使用 list 或者 next 函数)来遍历该生成器对象,将 yield 的内容一个一个打印出来
更多关于 yield 和生成器的内容,请前往前面的文章,里面有非常详细的讲解:3.6 【基础】生成器
向生成器中发送消息
函数暂停之后,如果调用者能在下一次恢复函数运行的时候,向它传递一些信息,那么整个程序的灵活性会大大提升。
下面通过一个简明的演示来看看,如何往生成器中发送消息:
1 | |
输出。
1 | |
这里解释下为什么这么输出。
重点是jump = yield index这个语句。
分成两部分:
yield index是将indexreturn给外部调用程序。jump = yield可以接收外部程序通过send()发送的信息,并赋值给jump
下一节,我将讲一个Python3.5新引入的语法:yield from。篇幅也比较多,所以就单独拿出来讲。
10.8 【并发编程】深入理解yield from语法
1. 为什么要使用协程
在上一篇中,我们从生成器的基本认识与使用,成功过渡到了协程。
但一定有许多人,只知道协程是个什么东西,但并不知道为什么要用协程?换句话来说,并不知道在什么情况下用协程?
它相比多线程来说,有哪些过人之处呢?
在开始讲yield from 之前,我想先解决一下这个给很多人带来困惑的问题。
举个例子。
假如我们做一个爬虫。我们要爬取多个网页,这里简单举例两个网页(两个spider函数),获取HTML(耗IO耗时),然后再对HTML对行解析取得我们感兴趣的数据。
我们的代码结构精简如下:
1 | |
我们都知道,get_html()等待返回网页是非常耗IO的,一个网页还好,如果我们爬取的网页数据极其庞大,这个等待时间就非常惊人,是极大的浪费。
聪明的程序员,当然会想如果能在get_html()这里暂停一下,不用傻乎乎地去等待网页返回,而是去做别的事。等过段时间再回过头来到刚刚暂停的地方,接收返回的html内容,然后还可以接下去解析parse_html(html)。
利用常规的方法,几乎是没办法实现如上我们想要的效果的。所以Python想得很周到,从语言本身给我们实现了这样的功能,这就是yield语法。可以实现在某一函数中暂停的效果。
试着思考一下,假如没有协程,我们要写一个并发程序。可能有以下问题
- 使用最常规的同步编程要实现异步并发效果并不理想,或者难度极高。
- 由于GIL锁的存在,多线程的运行需要频繁的加锁解锁,切换线程,这极大地降低了并发性能;
而协程的出现,刚好可以解决以上的问题。它的特点有
- 协程是在单线程里实现任务的切换的
- 利用同步的方式去实现异步
- 不再需要锁,提高了并发性能
2. yield from的用法详解
yield from 是在Python3.3才出现的语法。所以这个特性在Python2中是没有的。
yield from 后面需要加的是可迭代对象,它可以是普通的可迭代对象,也可以是迭代器,甚至是生成器。
2.1 简单应用:拼接可迭代对象
我们可以用一个使用yield和一个使用yield from的例子来对比看下。
使用yield
1 | |
使用yield from
1 | |
由上面两种方式对比,可以看出,yield from后面加上可迭代对象,他可以把可迭代对象里的每个元素一个一个的yield出来,对比yield来说代码更加简洁,结构更加清晰。
2.2 复杂应用:生成器的嵌套
如果你认为只是 yield from 仅仅只有上述的功能的话,那你就太小瞧了它,它的更强大的功能还在后面。
当 yield from 后面加上一个生成器后,就实现了生成的嵌套。
当然实现生成器的嵌套,并不是一定必须要使用yield from,而是使用yield from可以让我们避免让我们自己处理各种料想不到的异常,而让我们专注于业务代码的实现。
如果自己用yield去实现,那只会加大代码的编写难度,降低开发效率,降低代码的可读性。既然Python已经想得这么周到,我们当然要好好利用起来。
讲解它之前,首先要知道这个几个概念
1、
调用方:调用委派生成器的客户端(调用方)代码
2、委托生成器:包含yield from表达式的生成器函数
3、子生成器:yield from后面加的生成器函数
你可能不知道他们都是什么意思,没关系,来看下这个例子。
这个例子,是实现实时计算平均值的。
比如,第一次传入10,那返回平均数自然是10.
第二次传入20,那返回平均数是(10+20)/2=15
第三次传入30,那返回平均数(10+20+30)/3=20
1 | |
认真阅读以上代码,你应该很容易能理解,调用方、委托生成器、子生成器之间的关系。我就不多说了
委托生成器的作用是:在调用方与子生成器之间建立一个双向通道。
所谓的双向通道是什么意思呢?
调用方可以通过send()直接发送消息给子生成器,而子生成器yield的值,也是直接返回给调用方。
你可能会经常看到有些代码,还可以在yield from前面看到可以赋值。这是什么用法?
你可能会以为,子生成器yield回来的值,被委托生成器给拦截了。你可以亲自写个demo运行试验一下,并不是你想的那样。
因为我们之前说了,委托生成器,只起一个桥梁作用,它建立的是一个双向通道,它并没有权利也没有办法,对子生成器yield回来的内容做拦截。
为了解释这个用法,我还是用上述的例子,并对其进行了一些改造。添加了一些注释,希望你能看得明白。
按照惯例,我们还是举个例子。
1 | |
运行后,输出
1 | |
3. 为什么要使用yield from
学到这里,我相信你肯定要问,既然委托生成器,起到的只是一个双向通道的作用,我还需要委托生成器做什么?我调用方直接调用子生成器不就好啦?
高能预警~~~
下面我们来一起探讨一下,到底yield from 有什么过人之处,让我们非要用它不可。
3.1 因为它可以帮我们处理异常
如果我们去掉委托生成器,而直接调用子生成器。那我们就需要把代码改成像下面这样,我们需要自己捕获异常并处理。而不像使yield from那样省心。
1 | |
此时的你,可能会说,不就一个StopIteration的异常吗?自己捕获也没什么大不了的。
你要是知道yield from在背后为我们默默无闻地做了哪些事,你就不会这样说了。
具体yield from为我们做了哪些事,可以参考如下这段代码。
1 | |
以上的代码,稍微有点复杂,有兴趣的同学可以结合以下说明去研究看看。
- 迭代器(即可指子生成器)产生的值直接返还给调用者
- 任何使用send()方法发给委派生产器(即外部生产器)的值被直接传递给迭代器。如果send值是None,则调用迭代器next()方法;如果不为None,则调用迭代器的send()方法。如果对迭代器的调用产生StopIteration异常,委派生产器恢复继续执行yield from后面的语句;若迭代器产生其他任何异常,则都传递给委派生产器。
- 子生成器可能只是一个迭代器,并不是一个作为协程的生成器,所以它不支持.throw()和.close()方法,即可能会产生AttributeError 异常。
- 除了GeneratorExit 异常外的其他抛给委派生产器的异常,将会被传递到迭代器的throw()方法。如果迭代器throw()调用产生了StopIteration异常,委派生产器恢复并继续执行,其他异常则传递给委派生产器。
- 如果GeneratorExit异常被抛给委派生产器,或者委派生产器的close()方法被调用,如果迭代器有close()的话也将被调用。如果close()调用产生异常,异常将传递给委派生产器。否则,委派生产器将抛出GeneratorExit 异常。
- 当迭代器结束并抛出异常时,yield from表达式的值是其StopIteration 异常中的第一个参数。
- 一个生成器中的return expr语句将会从生成器退出并抛出 StopIteration(expr)异常。
没兴趣看的同学,只要知道,yield from帮我们做了很多的异常处理,而且全面,而这些如果我们要自己去实现的话,一个是编写代码难度增加,写出来的代码可读性极差,这些我们就不说了,最主要的是很可能有遗漏,只要哪个异常没考虑到,都有可能导致程序崩溃什么的
10.9 【并发编程】初识异步IO框架:asyncio 上篇
通过前两节的铺垫(关于协程的使用),今天我们终于可以来介绍我们整个系列的重点 – asyncio。
asyncio是Python 3.4版本引入的标准库,直接内置了对异步IO的支持。
有些同学,可能很疑惑,既然有了以生成器为基础的协程,我们直接使用yield 和 yield from 不就可以手动实现对IO的调度了吗? 为何Python吃饱了没事干,老重复造轮子。
这个问题很好回答,就跟为什么会有Django,为什么会有Scrapy,是一个道理。
他们都是框架,将很多很重复性高,复杂度高的工作,提前给你做好,这样你就可以专注于业务代码的研发。
跟着小明学完了协程的那些个难点,你是不是也发现了,协程的知识点我已经掌握了,但是我还是不知道怎么用,如何使用,都说它可以实现并发,但是我还是不知道如何入手?
那是因为,我们现在还缺少一个成熟的框架,帮助你完成那些复杂的动作。这个时候,ayncio就这么应运而生了。
1. 如何定义/创建协程
还记得在前两章节的时候,我们创建了生成器,是如何去检验我们创建的是不是生成器对象吗?
我们是借助了isinstance()函数,来判断是否是collections.abc 里的Generator类的子类实现的。
同样的方法,我们也可以用在这里。
只要在一个函数前面加上 async 关键字,这个函数对象是一个协程,通过isinstance函数,它确实是Coroutine类型。
1 | |
前两节,我们说,生成器是协程的基础,那我们是不是有办法,将一个生成器,直接变成协程使用呢。答案是有的。
1 | |
2. asyncio的几个概念
在了解asyncio的使用方法前,首先有必要先介绍一下,这几个贯穿始终的概念。
event_loop 事件循环:程序开启一个无限的循环,程序员会把一些函数(协程)注册到事件循环上。当满足事件发生的时候,调用相应的协程函数。coroutine 协程:协程对象,指一个使用async关键字定义的函数,它的调用不会立即执行函数,而是会返回一个协程对象。协程对象需要注册到事件循环,由事件循环调用。future 对象: 代表将来执行或没有执行的任务的结果。它和task上没有本质的区别task 任务:一个协程对象就是一个原生可以挂起的函数,任务则是对协程进一步封装,其中包含任务的各种状态。Task 对象是 Future 的子类,它将 coroutine 和 Future 联系在一起,将 coroutine 封装成一个 Future 对象。async/await 关键字:python3.5 用于定义协程的关键字,async定义一个协程,await用于挂起阻塞的异步调用接口。其作用在一定程度上类似于yield。
这几个概念,干看可能很难以理解,没事,往下看实例,然后再回来,我相信你一定能够理解。
3. 学习协程是如何工作的
协程完整的工作流程是这样的
- 定义/创建协程对象
- 将协程转为task任务
- 定义事件循环对象容器
- 将task任务扔进事件循环对象中触发
光说不练假把戏,一起来看下
1 | |
输出结果,当然显而易见
1 | |
4. await与yield对比
前面我们说,await用于挂起阻塞的异步调用接口。其作用在一定程度上类似于yield。
注意这里是,一定程度上,意思是效果上一样(都能实现暂停的效果),但是功能上却不兼容。就是你不能在生成器中使用await,也不能在async 定义的协程中使用yield from。
小明不是胡说八道的。有实锤。
再来一锤。
除此之外呢,还有一点很重要的。
yield from后面可接可迭代对象,也可接future对象/协程对象;await后面必须要接future对象/协程对象
如何验证呢?
yield from 后面可接 可迭代对象,这个前两章已经说过了,这里不再赘述。
接下来,就只要验证,yield from和await都可以接future对象/协程对象就可以了。
验证之前呢,要先介绍一下这个函数:asyncio.sleep(n),这货是asyncio自带的工具函数,他可以模拟IO阻塞,他返回的是一个协程对象。
1 | |
还有,要学习如何创建Future对象,不然怎么验证。
前面概念里说过,Task是Future的子类,这么说,我们只要创建一个task对象即可。
1 | |
好了,接下来,开始验证。
5. 绑定回调函数
异步IO的实现原理,就是在IO高的地方挂起,等IO结束后,再继续执行。在绝大部分时候,我们后续的代码的执行是需要依赖IO的返回值的,这就要用到回调了。
回调的实现,有两种,一种是绝大部分程序员喜欢的,利用的同步编程实现的回调。
这就要求我们要能够有办法取得协程的await的返回值。
1 | |
输出
1 | |
还有一种是通过asyncio自带的添加回调函数功能来实现。
1 | |
输出
1 | |
和上面的结果是一样的。非常好。
10.10 【并发编程】深入异步IO框架:asyncio 中篇
今天的内容其实还挺多的,我准备了三天,到今天才整理完毕。希望大家看完,有所收获的,能给小明一个赞。这就是对小明最大的鼓励了。
为了更好地衔接这一节,我们先来回顾一下上一节的内容。
上一节,我们首先介绍了,如何创建一个协程对象.
主要有两种方法
- 通过
async关键字, - 通过
@asyncio.coroutine装饰函数。
然后有了协程对象,就需要一个事件循环容器来运行我们的协程。其主要的步骤有如下几点:
- 将协程对象转为task任务对象
- 定义一个事件循环对象容器用来存放task
- 将task任务扔进事件循环对象中并触发
为了让大家,对生成器和协程有一个更加清晰的认识,我还介绍了yield和async/await的区别。
最后,我们还讲了,如何给一个协程添加回调函数。
好了,用个形象的比喻,上一节,其实就只是讲了协程中的单任务。哈哈,是不是还挺难的?希望大家一定要多看几遍,多敲代码,不要光看。
那么这一节,我们就来看下,协程中的多任务。
1. 协程中的并发
协程的并发,和线程一样。举个例子来说,就好像 一个人同时吃三个馒头,咬了第一个馒头一口,就得等这口咽下去,才能去啃第其他两个馒头。就这样交替换着吃。
asyncio实现并发,就需要多个协程来完成任务,每当有任务阻塞的时候就await,然后其他协程继续工作。
第一步,当然是创建多个协程的列表。
1 | |
第二步,如何将这些协程注册到事件循环中呢。
有两种方法,至于这两种方法什么区别,稍后会介绍。
使用
asyncio.wait()1
2loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))使用
asyncio.gather()1
2
3## 千万注意,这里的 「*」 不能省略
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.gather(*tasks))
最后,return的结果,可以用task.result()查看。
1 | |
完整代码如下
1 | |
输出结果
1 | |
2. 协程中的嵌套
使用async可以定义协程,协程用于耗时的io操作,我们也可以封装更多的io操作过程,这样就实现了嵌套的协程,即一个协程中await了另外一个协程,如此连接起来。
来看个例子。
1 | |
如果这边,使用的是asyncio.gather(),是这么用的
1 | |
输出还是一样的。
1 | |
仔细查看,可以发现这个例子完全是由 上面「协程中的并发」例子改编而来。结果完全一样。只是把创建协程对象,转换task任务,封装成在一个协程函数里而已。外部的协程,嵌套了一个内部的协程。
其实你如果去看下asyncio.await()的源码的话,你会发现下面这种写法
1 | |
看似没有嵌套,实际上内部也是嵌套的。
这里也把源码,贴出来,有兴趣可以看下,没兴趣,可以直接跳过。
1 | |
3. 协程中的状态
还记得我们在讲生成器的时候,有提及过生成器的状态。同样,在协程这里,我们也了解一下协程(准确的说,应该是Future对象,或者Task任务)有哪些状态。
Pending:创建future,还未执行Running:事件循环正在调用执行任务Done:任务执行完毕Cancelled:Task被取消后的状态
可手工 python3 xx.py 执行这段代码,
1 | |
顺利执行的话,将会打印 Pending -> Pending:Runing -> Finished 的状态变化
假如,执行后 立马按下 Ctrl+C,则会触发task取消,就会打印 Pending -> Cancelling -> Cancelling 的状态变化。
4. gather与wait
还记得上面我说,把多个协程注册进一个事件循环中有两种方法吗?
使用
asyncio.wait()1
2loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))使用
asyncio.gather()1
2
3## 千万注意,这里的 「*」 不能省略
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.gather(*tasks))
asyncio.gather 和 asyncio.wait 在asyncio中用得的比较广泛,这里有必要好好研究下这两货。
还是照例用例子来说明,先定义一个协程函数
1 | |
5. 接收参数方式
asyncio.wait
接收的tasks,必须是一个list对象,这个list对象里,存放多个的task。
它可以这样,用asyncio.ensure_future转为task对象
1 | |
也可以这样,不转为task对象。
1 | |
asyncio.gather
接收的就比较广泛了,他可以接收list对象,但是 * 不能省略
1 | |
还可以这样,和上面的 * 作用一致,这是因为asyncio.gather()的第一个参数是 *coros_or_futures,它叫 非命名键值可变长参数列表,可以集合所有没有命名的变量。
1 | |
甚至还可以这样
1 | |
6. 返回结果不同
asyncio.wait
asyncio.wait 返回dones和pendings
dones:表示已经完成的任务pendings:表示未完成的任务
如果我们需要获取,运行结果,需要手工去收集获取。
1 | |
asyncio.gather
asyncio.gather 它会把值直接返回给我们,不需要手工去收集。
1 | |
7. wait有控制功能
1 | |
输出结果
1 | |
10.11 【并发编程】实战异步IO框架:asyncio 下篇
1. 动态添加协程
在实战之前,我们要先了解下在asyncio中如何将协程态添加到事件循环中的。这是前提。
如何实现呢,有两种方法:
- 主线程是同步的
1 | |
由于是同步的,所以总共耗时6+3=9秒.
输出结果
1 | |
- 主线程是异步的,这是重点,一定要掌握。。
1 | |
输出结果
由于是异步的,所以总共耗时max(6, 3)=6秒
1 | |
2. 利用redis实现动态添加任务
对于并发任务,通常是用生成消费模型,对队列的处理可以使用类似master-worker的方式,master主要用户获取队列的msg,worker用户处理消息。
为了简单起见,并且协程更适合单线程的方式,我们的主线程用来监听队列,子线程用于处理队列。这里使用redis的队列。主线程中有一个是无限循环,用户消费队列。
先安装Redis
到 https://github.com/MicrosoftArchive/redis/releases 下载
解压到你的路径。
然后,在当前路径运行cmd,运行redis的服务端。
服务开启后,我们就可以运行我们的客户端了。
并依次输入key=queue,value=5,3,1的消息。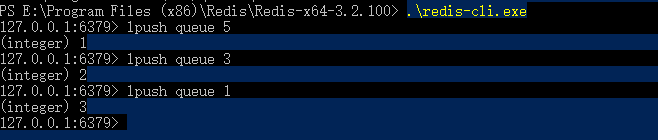
一切准备就绪之后,我们就可以运行我们的代码了。
1 | |
稍微讲下代码
loop_thread:单独的线程,运行着一个事件对象容器,用于实时接收新任务。consumer_thread:单独的线程,实时接收来自Redis的消息队列,并实时往事件对象容器中添加新任务。
输出结果
1 | |
我们在Redis,分别发起了5s,3s,1s的任务。
从结果来看,这三个任务,确实是并发执行的,1s的任务最先结束,三个任务完成总耗时5s
运行后,程序是一直运行在后台的,我们每一次在Redis中输入新值,都会触发新任务的执行。。
10.12 【并发编程】生成器与协程,你分清了吗?
如你所见,下面这代码将定义一个生成器的。
1 | |
运行一下,从结果中可以看出,不管我们塞给小明什么东西,小明都将只能将他们当成面包吃。
1 | |
那再来看一下协程的。
1 | |
运行一下,从结果中可以看出,小明已经可以感知我们塞给他的是什么食物。
1 | |
仔细观察一下,上面两段代码并没有太大的区别,我们将主要关注点集中在 yield 关键词上。
可以发现,生成器里 yield 左边并没有变量,而在协程里,yield 左边有一个变量。
在函数被调用后,一个生成器就产生了,而一般的生成器不能再往生成器内部传递参数了,而这个当生成器里的 yield 左边有变量时,就不一样了,它仍然可以在外部接收新的参数。这就是生成器与协程的最大区别。
协程的优点:
线程属于系统级别调度,而协程是程序员级别的调度。使用协程避免了无意义的调度,减少了线程上下文切换的开销,由此可以提高性能。
高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
无需原子操作锁定及同步的开销
方便切换控制流,简化编程模型
协程的缺点:
(1)无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上.当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用。
(2)进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序
协程很类似于Javascript单线程下异步处理的概念,协程同样是单线程的,之所以能够进行并发是因为通过某种方式保存了执行栈的上下文,在一定条件下将执行权交由其他栈,在一定条件下又通过执行栈上下文恢复栈。
10.14 【并发编程】浅谈线程安全那些事儿
在并发编程时,如果多个线程访问同一资源,我们需要保证访问的时候不会产生冲突,数据修改不会发生错误,这就是我们常说的 线程安全 。
那什么情况下,访问数据时是安全的?什么情况下,访问数据是不安全的?如何知道你的代码是否线程安全?要如何访问数据才能保证数据的安全?
本篇文章会一一回答你的问题。
1. 线程不安全是怎样的?
要搞清楚什么是线程安全,就要先了解线程不安全是什么样的。
比如下面这段代码,开启两个线程,对全局变量 number 各自增 10万次,每次自增 1。
1 | |
正常我们的预期输出结果,一个线程自增100万,两个线程就自增 200 万嘛,输出肯定为 2000000 。
可事实却并不是你想的那样,不管你运行多少次,每次输出的结果都会不一样,而这些输出结果都有一个特点是,都小于 200 万。
以下是执行三次的结果
1 | |
这种现象就是线程不安全,究其根因,其实是我们的操作 number += 1 ,不是原子操作,才会导致的线程不安全。
2. 什么是原子操作?
原子操作(atomic operation),指不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,中间不会切换到其他线程。
它有点类似数据库中的 事务。
在 Python 的官方文档上,列出了一些常见原子操作
1 | |
而下面这些就不是原子操作
1 | |
像上面的我使用自增操作 number += 1,其实等价于 number = number + 1,可以看到这种可以拆分成多个步骤(先读取相加再赋值),并不属于原子操作。
这样就导致多个线程同时读取时,有可能读取到同一个 number 值,读取两次,却只加了一次,最终导致自增的次数小于预期。
当我们还是无法确定我们的代码是否具有原子性的时候,可以尝试通过 dis 模块里的 dis 函数来查看
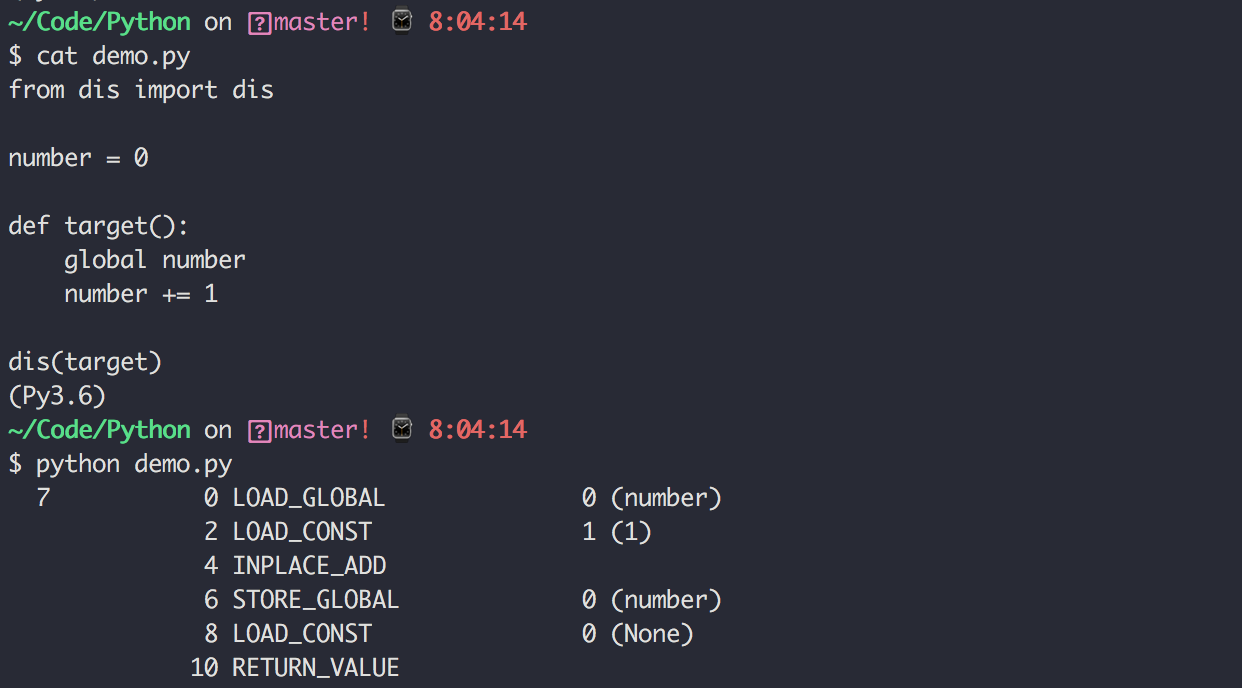
当我们执行这段代码时,可以看到 number += 1 这一行代码,由两条字节码实现。
BINARY_ADD:将两个值相加STORE_GLOBAL: 将相加后的值重新赋值
每一条字节码指令都是一个整体,无法分割,他实现的效果也就是我们所说的原子操作。
当一行代码被分成多条字节码指令的时候,就代表在线程线程切换时,有可能只执行了一条字节码指令,此时若这行代码里有被多个线程共享的变量或资源时,并且拆分的多条指令里有对于这个共享变量的写操作,就会发生数据的冲突,导致数据的不准确。
为了对比,我们从上面列表的原子操作拿一个出来也来试试,是不是真如官网所说的原子操作。
这里我拿字典的 update 操作举例,代码和执行过程如下图
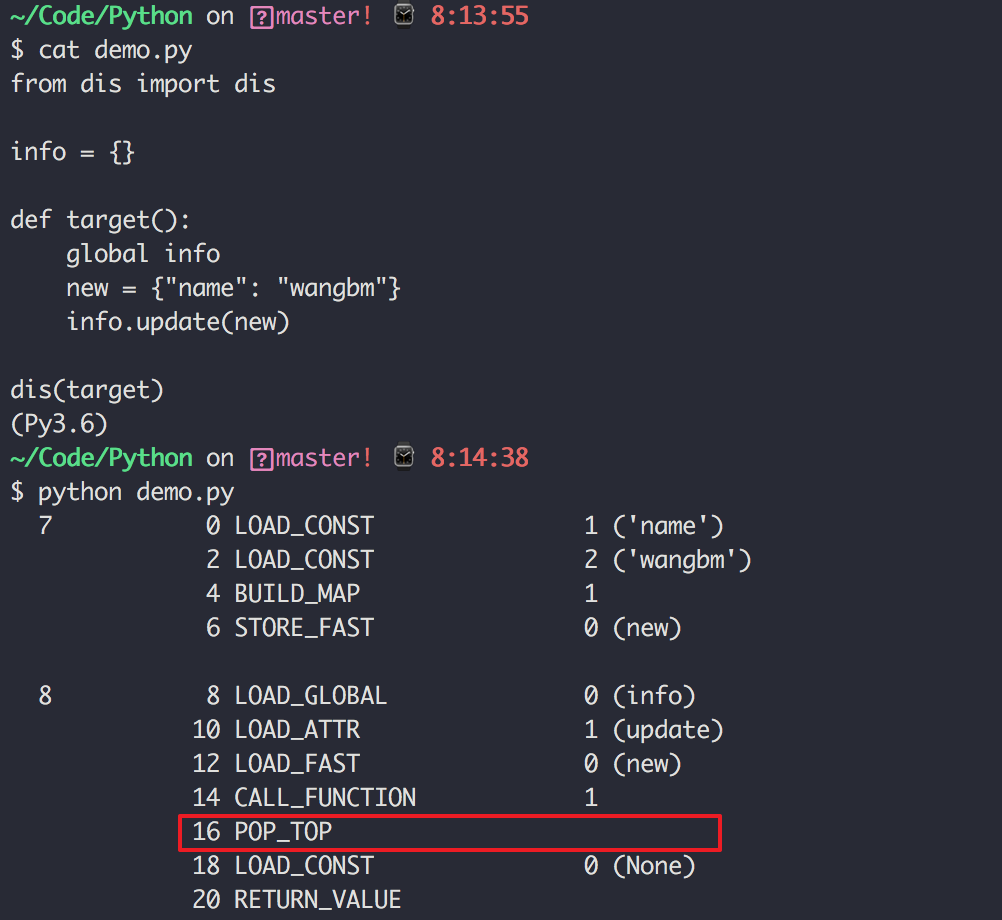
从截图里可以看到,info.update(new) 虽然也分为好几个操作
LOAD_GLOBAL:加载全局变量LOAD_ATTR: 加载属性,获取 update 方法LOAD_FAST:加载 new 变量CALL_FUNCTION:调用函数POP_TOP:执行更新操作
但我们要知道真正会引导数据冲突的,其实不是读操作,而是写操作。
上面这么多字节码指令,写操作都只有一个(POP_TOP),因此字典的 update 方法是原子操作。
3. 实现人工原子操作
在多线程下,我们并不能保证我们的代码都具有原子性,因此如何让我们的代码变得具有 “原子性” ,就是一件很重要的事。
方法也很简单,就是当你在访问一个多线程间共享的资源时,加锁可以实现类似原子操作的效果,一个代码要嘛不执行,执行了的话就要执行完毕,才能接受线程的调度。
因此,我们使用加锁的方法,对例子一进行一些修改,使其具备原子性。
1 | |
此时,不管你执行多少遍,输出都是 2000000.
4. 为什么 Queue 是线程安全的?
Python 的 threading 模块里的消息通信机制主要有如下三种:
- Event
- Condition
- Queue
使用最多的是 Queue,而我们都知道它是线程安全的。当我们对它进行写入和提取的操作不会被中断而导致错误,这也是我们在使用队列时,不需要额外加锁的原因。
他是如何做到的呢?
其根本原因就是 Queue 实现了锁原语,因此他能像第三节那样实现人工原子操作。
原语指由若干个机器指令构成的完成某种特定功能的一段程序,具有不可分割性;即原语的执行必须是连续的,在执行过程中不允许被中断。
参考文章:
https://zhuanlan.zhihu.com/p/34150765
https://juejin.im/post/5b129a1be51d45068a6c91d4#comment
第十一章:代码美化
11.1 【代码美化】如何更好进行变量的命名?
命名是一件困难的事情,要想出一个恰到好处的命名需要一番功夫,尤其我们的母语还不是编程语言所通用的英语。不过这一切都是值得了,好的命名让你的代码更直观,更有表达力。
在进行变量的命名时,应注意:
- 变量名,最好能体现 『变量用途』,『数据类型』,『单复数』等
- 变量名,请不要过于随便,如使用数字 1,和字母 a
- 变量名,不要如不能正确引导,至少要做到不误导。比如 user_list 不应该是一个字典类型
- 变量名,请使用蛇形命名法(如 user_info),而不是使用驼峰命名法(userInfo)。
11.2 【代码美化】写好函数的 6 个建议
Python 虽然好用,但用好真的很难。
尤其是函数部分,只要写不好,后面的一连串人都会遭殃。
看又看不懂,测试起来也麻烦,维护又维护不动,真是让人头疼。
那怎么写好一个 Python 函数呢?
《Writing Idiomatic Python》一书的作者在 Medium 上发表了一篇文章,给出了 6 个建议。
希望能够给你带来帮助。
0. 怎样算是好函数?
“好”的 Python 函数和“差”的 Python 函数之间有什么差别呢?每个人都有自己的理解。基于我的理解,如果一个 Python 函数能够符合下面的大部分条件,我会认为它是一个“好”函数:
- 命名合理
- 单一功能
- 包括文档字符串
- 返回一个值
- 不超过 50 行
- 是幂等函数或纯函数
对许多人来说,这些要求可能显得过于苛刻了。
不过,我保证,如果你的函数遵循这些规则,你的代码会非常漂亮,会让其他的程序员都“馋哭”的。
下面,我将一一讨论这些规则,然后总结它们是如何创造“好”函数的。
1. 注意命名
在这个问题上,我最喜欢的一句话是:
计算机科学中只有两件事很让人头疼:缓存失效和命名。
尽管这听起来很莫名其妙,但给一个事情命名太难了。下面是一个反面案例:
1 | |
原文中这个代码没有放上去,我们根据上下文信息进行了补充。
这个函数命名的第一个问题是它使用了缩写。
对于那些并不出名的缩略词来说,使用完整的英语单词会更好。缩写单词的唯一原因是为了节省打字时间,但是每个现代编辑器都有自动填充功能,所以你只需要键入一次全名就可以了。
缩写通常是特定领域的。在上面的代码中,KNN 指的是“K-Nearest Neighbors”,df 指的是“DataFrame”,这是一个数据结构。如果另一个不熟悉这些首字母缩写的程序员正在阅读代码,几乎很难看懂。
关于这个函数的名字还有另外两个小瑕疵:
- “get”这个词是无关紧要的。对于大多数命名比较好的函数来说,很明显有一些东西会从函数中返回,它的名字将反映这一点。
- from_df 也不是必要的。如果没有明确的参数名称,函数的文档字符串或类型注释会描述参数的类型。
那么我们如何重命名这个函数呢?很简单:
1 | |
即使是外行,这个函数要计算的内容也很清楚,参数的名称(dataframe)也清楚地表明了参数类型。
2. 单一功能
单一功能原则不仅适用于类和模块,也同样适用于函数。
一个函数应该只有一个功能。也就是说,它应该只做一件事。
一个重要的原因是,如果每个函数只做一件事,只有这件事发生了变化,才需要改变这个函数。
此外,如果这个函数的单个功能不再需要了,直接把它删了就行了。
还是用例子来说明吧。下面这个函数,可以做不止一件“事情”:
1 | |
这个函数做了两件事:一是计算一组关于数字列表的统计数据,二是将它们打印到 STDOUT。
如果需要计算新的或不同的统计数据,或者需要改变输出的格式,就需要对这个函数进行调整。
所以,这个函数最好写成两个独立的函数:一个用来执行并返回计算结果,另一个用来获取这些结果并打印出来。
这种处理方式,不仅能让测试函数更容易,并且还允许这两个部分有了迁移性,如果合适的话,还可能一起应用到不同的模块中。
在编程中,你会发现好多函数都可以做很多很多事情。同样,为了可读性和可测试性,这些函数应该被分解成更小的函数,每个函数只有一个功能。
3. 文档字符串(Docstrings)
虽然每个人似乎都知道 PEP - 8,它定义了 Python 的样式指南,但是很少有人知道 PEP - 257,它是关于文档字符串的。我再这里不简单地重复 PEP - 257 的内容了,你可以在闲暇时读一下。其中的关键内容是:
- 每个函数都需要有一个文档字符串
- 使用适当的语法和标点符号;用完整的句子写
- 首先对函数的作用进行一句话的总结
- 使用说明性语言而不是描述性语言
在编写函数时,要养成写文档字符串的习惯,并在编写函数代码之前尝试写一下。
如果你不能写一个清晰的文档字符串来描述函数做什么,就说明你需要再考虑考虑为什么要写这个函数了。
4. 返回值
函数可以被认为是一些独立的程序。它们以参数的形式接受一些输入,并返回一些结果。
参数有没有都可以,但从 Python 内部的角度来看,返回值是必须要有的。你不可能创建一个没有返回值的函数。如果函数没有返回值,Python 会“强制”返回 None。你可以测试一下这段代码:
1 | |
你会发现 b 的返回值实际上是 None。即使你写的函数没有返回语句,它仍然会返回一些东西。而且,每个函数都应该返回一个有用的值,测试起来也会更方便。毕竟,你写的代码应该能够被测试。
试想一下,测试上面的 add 函会有多艰难。遵循这个概念,我们应该这样写代码:
1 | |
if line.strip().lower().endswith(‘cat’): 这一行能够工作,是因为每个字符串方法( strip ( )、lower ( )、end swith ( ) )都返回一个字符串作为调用函数的结果。
当给定函数没有返回值时,有一些常见的原因:
“它所做的只是[一些与 I/O 相关的事情,比如将一个值保存到数据库中]。我不能返回任何有用的东西。”
我不同意。如果操作顺利完成,函数可以返回 True。
“我们修改了其中一个参数,将其用作参考参数。”
这里有两点需要注意。首先,尽最大努力避免这种做法。用好了令人惊讶,用不好非常危险。
其次,即使这样做不可行,复制某个参数的成本太高,你也可以回到上一条建议。
“我需要返回多个值。单独返回一个值是没有意义的。”
可以使用元组返回多个值。
总是返回一个有用的值,调用者总是可以自由地忽略它们。
5. 函数长度
让你读一个 200 行的函数,并说出它是做什么的,你是什么感受?
函数的长度直接影响可读性,从而影响可维护性。所以要保持你的函数简短。50 行是一个随意的数字,在我看来是合理的。你编写的大多数函数应该要短一些。
如果一个函数遵循单一功能原则,它很可能是相当短的。如果它是纯函数或是幂等的(下面讨论) ,它也可能是短的。
那么,如果函数太长,应该怎么做?重构。这会改变程序的结构而不改变其行为。
从一个长函数中提取几行代码,并把它们变成自己的函数。这是缩短长函数的最快、也是最常见的方式。
加上你给所有这些新函数取了合适的名称,因此生成的代码读起来也会更容易。
6. 幂等和函数纯度
不管被调用了多少次,幂等函数总是在给定相同参数集的情况下返回相同的值。
结果不依赖于非局部变量、参数的可变性或来自任何 I / O 流的数据。下面的这个 add_three(number)函数是幂等函数:
1 | |
不管一个人调用 add_three(7)多少次,答案总是 10。以下是一个非幂等函数:
1 | |
这个函数的返回值取决于 I / O,即用户输入的数字。对 add_three()的每次调用都会返回不同的值。
如果它被调用两次,用户可以第一次输入 3,第二次输入 7,分别调用 add_three()返回 6 和 10。
幂等性的一个现实中例子是在电梯前点击“向上”按钮。第一次按时,电梯会被“通知”你要上去。因为按按钮是幂等的,所以反复按它都没有什么影响。结果是一样的。
6.1 为什么幂等很重要?
可维护性和可维护性。幂等函数很容易测试,因为在使用相同的参数时,它们总是返回相同的结果。
测试仅仅是检查通过不同调用返回值的预期值。更重要的是,这些测试很快,这是单元测试中一个重要且经常被忽视的问题。
而在处理幂等函数时,重构是轻而易举的事情。无论如何在函数之外更改代码,使用相同的参数调用它的结果总是一样的。
6.2 什么是纯函数?
在函数编程中,如果一个函数既幂等又没有可观察到的副作用,它就被认为是纯函数。函数外部的任何东西都不会影响这个值。
然而,这并不意味着函数不能影响非局部变量或 I / O 流之类的事情。例如,如果上面 add_three(number)的幂等版本在返回结果之前打印了结果,那么它仍然被认为是幂等的,因为当它访问 I / O 流时,这个访问与从函数返回的值无关。
调用 print()只是一个副作用:除了返回值之外,还与程序的其他部分或系统本身进行了一些交互。
让我们把我们的 add_three(number)示例再向前推进一步。我们可以编写下面的代码片段来确定调用 add_three(number)的次数:
1 | |
我们现在正在打印到控制台(一个副作用)并修改一个非局部变量(另一个副作用),但是由于这两者都不影响函数返回的值,它仍然是幂等的。
纯函数没有副作用。它不仅不使用任何“外部数据”来计算值,除了计算和返回所述值之外,它与系统/程序的其余部分都没有交互。因此,虽然我们新的 add_three(number)定义仍然是幂等的,但它不再是纯的。
纯函数没有日志语句或 print()调用。它们不使用数据库或互联网连接。它们不访问或修改非局部变量。它们不调用任何其他非纯函数。
简而言之,它们无法做到爱因斯坦所说的“远距离幽灵般的行动”(在计算机科学环境中)。它们不会以任何方式修改程序或系统的其余部分。
在命令式编程(编写 Python 代码时所做的那种)中,它们是所有函数中最安全的函数。
它们也很容易被测试和维护,甚至比只是幂等函数更重要的是,测试它们基本上可以和执行它们一样快。
测试本身很简单:没有数据库连接或其他外部资源进行模拟,也不需要安装代码,之后也没有什么需要清理的。
明确地说,幂等性和纯函数只是一种期望,不是必需的。也就是说,由于好处很多,我们可能会希望只编写纯函数或幂等函数,但这不现实。
重要的是,我们要有意识开始写代码来隔离副作用和外部依赖性。这会使得我们编写的每一行代码都更容易被测试。## 11.3 【代码美化】自觉遵守 PEP8 代码风格
每个编程语言都有自己的编码,而在 Python 中最受认可的是 PEP 8的编码风格规范。每个写 Python 代码的人都有必要过一遍 PEP 8的内容 ,它可以让你的代码“ 更好看”,更容易被阅读。
1. 代码编排
- 缩进。4个空格的缩进(编辑器都可以完成此功能),不使用Tap,更不能混合使用Tap和空格。
- 每行最大长度79,换行可以使用反斜杠,最好使用圆括号。换行点要在操作符的后边敲回车。
- 类和top-level函数定义之间空两行;类中的方法定义之间空一行;函数内逻辑无关段落之间空一行;其他地方尽量不要再空行。
2. 文档编排
- 模块内容的顺序:模块说明和docstring—import—globals&constants—其他定义。其中import部分,又按标准、三方和自己编写顺序依次排放,之间空一行。
- 不要在一句import中多个库,比如import os, sys不推荐。
- 如果采用from XX import XX引用库,可以省略 module,都是可能出现命名冲突,这时就要采用import XX。
3. 空格的使用
总体原则,避免不必要的空格。
- 各种右括号前不要加空格。
- 逗号、冒号、分号前不要加空格。
- 函数的左括号前不要加空格。如Func(1)。
- 序列的左括号前不要加空格。如list[2]。
- 操作符左右各加一个空格,不要为了对齐增加空格。
- 函数默认参数使用的赋值符左右省略空格。
- 不要将多句语句写在同一行,尽管使用‘;’允许。
- if/for/while语句中,即使执行语句只有一句,也必须另起一行。
4. 注释
总体原则,错误的注释不如没有注释。所以当一段代码发生变化时,第一件事就是要修改注释!注释必须使用英文,最好是完整的句子,首字母大写,句后要有结束符,结束符后跟两个空格,开始下一句。如果是短语,可以省略结束符。
1、块注释,在一段代码前增加的注释。在‘#’后加一空格。段落之间以只有‘#’的行间隔。比如:
1 | |
2、行注释,在一句代码后加注释。比如:(但是这种方式尽量少使用)
1 | |
3、避免无谓的注释。
5. 文档描述
- 为所有的共有模块、函数、类、方法写docstrings;非共有的没有必要,但是可以写注释(在def的下一行)。
- 如果docstring要换行,参考如下例子,详见PEP 257
1 | |
6. 命名规范
总体原则,新编代码必须按下面命名风格进行,现有库的编码尽量保持风格。
- 尽量单独使用小写字母‘l’,大写字母‘O’等容易混淆的字母。
- 模块命名尽量短小,使用全部小写的方式,可以使用下划线。
- 包命名尽量短小,使用全部小写的方式,不可以使用下划线。
4.类的命名使用CapWords的方式,模块内部使用的类采用_CapWords的方式。 - 异常命名使用CapWords+Error后缀的方式。
- 全局变量尽量只在模块内有效,类似C语言中的static。实现方法有两种,一是all机制;二是前缀一个下划线。
- 函数命名使用全部小写的方式,可以使用下划线。
- 常量命名使用全部大写的方式,可以使用下划线。
- 类的属性(方法和变量)命名使用全部小写的方式,可以使用下划线。
- 类的属性有3种作用域public、non-public和subclass API,可以理解成C++中的public、private、protected,non-public属性前,前缀一条下划线。
- 类的属性若与关键字名字冲突,后缀一下划线,尽量不要使用缩略等其他方式。
- 为避免与子类属性命名冲突,在类的一些属性前,前缀两条下划线。比如:类Foo中声明__a,访问时,只能通过Foo._Foo__a,避免歧义。如果子类也叫Foo,那就无能为力了。
- 类的方法第一个参数必须是self,而静态方法第一个参数必须是cls。## 11.4 【代码美化】Pythonic 代码的 15 个案例
Python由于语言的简洁性,让我们以人类思考的方式来写代码,新手更容易上手,老鸟更爱不释手。
要写出 Pythonic(优雅的、地道的、整洁的)代码,还要平时多观察那些大牛代码,这里明哥收集了一些比较常见的 Pythonic 写法,帮助你养成写优秀代码的习惯。
01. 变量交换
交换两个变量的值,正常都会想利用一个中间临时变量来过渡。
1 | |
能用一行代码解决的(并且不影响可读性的),决不用三行代码。
1 | |
02. 列表推导
下面是一个非常简单的 for 循环。
1 | |
在一个 for 循环中,如果逻辑比较简单,不如试用一下列表的列表推导式,虽然只有一行代码,但也逻辑清晰。
1 | |
03. 单行表达式
上面两个案例,都将多行代码用另一种方式写成了一行代码。
这并不意味着,代码行数越少,就越 Pythonic 。
比如下面这样写,就不推荐。
1 | |
建议还是按照如下的写法来
1 | |
04. 带索引遍历
使用 for 循环时,如何取得对应的索引,初学者习惯使用 range + len 函数
1 | |
更好的做法是利用 enumerate 这个内置函数
1 | |
05. 序列解包
使用 * 可以对一个列表解包
1 | |
06. 字符串拼接
如果一个列表(或者可迭代对象)中的所有元素都是字符串对象,想要将他们连接起来,通常做法是
1 | |
更推荐的做法是使用 join 函数
1 | |
07. 真假判断
判断一个变量是否为真(假),新手习惯直接使用 == 与 True、False、None 进行对比
1 | |
实际上,""、[]、{} 这些没有任何元素的容器都是假值,可直接使用 if not xx 来判断。
1 | |
08. 访问字典元素
当直接使用 [] 来访问字典里的元素时,若key不存在,是会抛异常的,所以新会可能会先判断一下是否有这个 key,有再取之。
1 | |
更推荐的做法是使用 get 来取,如果没有该 key 会默认返回 None(当然你也可以设置默认返回值)
1 | |
09. 操作列表
下面这段代码,会根据条件过滤过列表中的元素
1 | |
实际上可以使用列表推导或者高阶函数 filter 来实现
1 | |
除了 filter 之外,还有 map、reduce 这两个函数也很好用
1 | |
10. 文件读取
文件读取是非常常用的操作,在使用完句柄后,是需要手动调用 close 函数来关闭句柄的
1 | |
如果代码写得太长,即使你知道需要手动关闭句柄,却也会经常会漏掉。因此推荐养成习惯使用 with open 来读写文件,上下文管理器会自动执行关闭句柄的操作
1 | |
11. 代码续行
将一个长度较长的字符串放在一行中,是很影响代码可读性的(下面代码可向左滑动)
1 | |
稍等注重代码可读性的人,会使用三个引号 \来续写
1 | |
不过,对我来说,我更喜欢这样子写 使用括号包裹 ()
1 | |
导包的时候亦是如此
1 | |
12. 显式代码
有时候出于需要,我们会使用一些特殊的魔法来使代码适应更多的场景不确定性。
1 | |
但若非必要,请不要那么做。无端增加代码的不确定性,会让原先本就动态的语言写出更加动态的代码。
1 | |
13. 使用占位符
对于暂不需要,却又不得不接收的的变量,请使用占位符
1 | |
14. 链式比较
对于下面这种写法
1 | |
其实还有更好的写法
1 | |
如果你理解了上面的链式比较操作,那么你应该知道为什么下面这行代码输出的结果是 False
1 | |
15. 三目运算
对于简单的判断并赋值
1 | |
其实是可以使用三目运算,一行搞定。
1 | |
11.5 【代码美化】写出漂亮 Python 代码的 20条准则
通常,当我们在学校学习时,编程美学不是一个关键问题。用 Python 写代码时,个人也会遵循自己的风格。然而,当我们必须花大把时间来理解一个人的隐式代码时,这项工作肯定不受欢迎,这种情况同样可能发生在别人阅读我们的代码时。所以,让我们聚焦 Python 之禅和一些改进技巧,从而解决问题。
1. Python 之禅?
对于此前没听说过的人,请在 Python 解释器中键入并执行import this,会出现由 Tim Peters 撰写的 19 条指导原则:
- 优美胜于丑陋;
- 明了胜于晦涩;
- 简单胜于复杂;
- 复杂胜于晦涩;
- 扁平胜于嵌套;
- 间隔胜于紧凑;
- 可读性很重要;
- 特例不足以特殊到违背这些原则;
- 实用性胜过纯粹;
- 永远不要默默地忽视错误;
- 除非明确需要这样做;
- 面对模棱两可,拒绝猜测;
- 解决问题最直接的方法应该有一种,最好只有一种;
- 当然这是没法一蹴而就的,除非你是荷兰人;
- 做也许好过不做;
- 但不想就做还不如不做;
- 如果方案难以描述明白,那么一定是个糟糕的方案;
- 如果实现容易描述,那可能是个好方案;
- 命名空间是一种绝妙的理念,多加利用!
在这篇文章中,我将分享自己对这些格言的理解以及我学到的一些有用的 Python 技巧。
2. 优美胜于丑陋
Python 具有语法简单、代码可读性强和命令类似英语等特点,这让编写 Python 代码比使用其他编程语言更容易、更高效。例如,使用or and和|| &&构建语义相同的表达式:
1 | |
此外,代码的布局和组成非常重要,有大量资源涉及这个主题。下面是最受欢迎也是我最喜欢的一个:PEP 8——Python 代码风格指南。
https://www.python.org/dev/peps/pep-0008/
浏览完 PEP8 后,看看下面这些文章,其中展示了一些亮点和应用:
如何参照 PEP 8 编写漂亮的 Python 代码
优雅的 Python 与 PEP8
https://medium.com/@mariasurmenok/stylish-python-with-pep8-c3ca93531418
PEP-8 的陷阱
https://medium.com/@ian.reinert/the-pitfalls-of-pep-8-b6108b006ed9
永远不要弄乱你的代码。要优雅而美丽。
3. 明了胜于晦涩
在 Python 中,良好的命名约定不仅可以提升你的课堂成绩,而且还能让你的代码更明了。幸运的是,你能在 PEP8 中找到一些指导原则,我想在下面强调其中的一些要点。
https://www.python.org/dev/peps/pep-0008/
- 一般来说,避免使用以下名称:
- 太宽泛,如
my_list; - 太冗长,如
list_of_machine_learning_data_set; - 太模糊,如“1”、“I”、“o”、“O”。
- 包 / 模块名应该全部小写:
- 首选使用一个单词命名;
- 当需要使用多个单词时,使用下划线分割它们。
- 类名应遵循 UpperCaseCamelCase 规范
- 变量\方法\函数应该采用小写(如果需要,用下划线分割)
- 常量名必须全大写(如果需要,用下划线分割)
一切都必须清晰易懂。
4. 简单胜于复杂
简单比复杂更难:你必须付出巨大艰辛,化繁为简。但这一切到最后都是值得的,因为一旦你做到了,你便能创造奇迹。——乔布斯
很多时候,在处理迭代器时,我们还需要保存迭代计数。Python 通过提供一个名为enumerate()的内置函数简化这一任务。以下是一种不成熟的方法,然后是推荐方法:
1 | |
另一个示例是使用内置的zip()函数,该函数创建一个迭代器,对来自两个或多个迭代器的元素进行配对。你可以使用它来快速有效地解决常见的编程问题,比如创建字典。
1 | |
化繁为简的能力就是消除不必要的东西,保留必要的东西。
5. 复杂胜于晦涩
复杂(complex )和晦涩(complicated )的区别在于,复杂是指组件的系统层级,晦涩是指难度高。
有时候,尽管我们试图让任务变得简单和傻瓜化,结果可能仍然很糟。
在这种情况下,编程优化变得很有必要,我最喜欢的学习方法是完成 coding challenge websites 上的工作。你可以查看其他人的解决方案,甚至能受到更好算法的启发。
对于入门,HackerRank 提供了适合新手程序员的各种级别任务,这非常棒。之后,可以去尝试更专业的网站,比如 Coderbyte 和 Topcoder。
6. 扁平胜于嵌套
嵌套模块在 Python 中并不常见——至少我之前没有见过像module.class.subclass.function这样的东西——可读性不好。虽然在另一个子模块中构建子模块可能会减少代码行数,但我们不希望用户被不直观的语法所困扰。
7. 间隔胜于紧凑
不要在一行中插入太多代码,这会给读者带来压力。建议最大行长度 79 个字符。这样,当使用代码评审工具时,编辑器窗口宽度限制才能很好工作。
使用 Python 从 Unsplash 下载图片
8. 可读性很重要
代码的阅读次数比编写次数多。考虑下缩进,它让代码更容易阅读,比较下面的代码:
1 | |
在本例中,代码结果相同,但是后一段代码通过使用下划线占位符和 f-string 提供了更好的可读性。在 Python 3.6 发布后,f-string 开始让格式化变得更简单,并且在处理包含更多变量的更长的句子时更强大。
一个作家的风格不应该在他的思想和读者的思想间设置障碍。
9. 特例不足以特殊到违背这些原则
关键是为一般情况提供一贯支持,尝试将一个繁琐的项目重新组织成一个简单形式。例如,根据其功能,结构化类的代码或将其分类到不同的文件中,即使 Python 并不强迫你这样做。由于 Python 是一种多范式编程语言,解决问题的一个强大方法是创建对象,这就是所谓的面向对象编程。
面向对象编程是一种组织程序结构的编程范式,让属性和行为可以被看作是单独对象。它的优点是直观和易于操作,许多教程都很好地解释了这些概念。
10. 实用性胜过纯粹
这句格言与前一句相矛盾,它提醒我们保持它们之间的平衡
11. 永远不要默默地忽视错误
放过错误最终会留下隐式 Bug,并且这些 Bug 更难被发现。Python 提供了健壮的错误处理,与其他语言相比,程序员使用该工具并不难。
1 | |
根据 Python 文档:“即使一个语句或表达式在语法上是正确的,在试图执行它时也可能会导致错误。”特别是对于大型项目,我们不希望在耗时的计算后,代码崩溃。这就是异常管理的魅力所在。
12. 除非明确需要这样做
在某些情况下,小错误不会困扰你。不过,也许你想捕获特定错误。要获得关于特定错误消息的更多细节,我建议阅读官方的内置异常文档并找到你需要的内容。
https://docs.python.org/3/library/exceptions.html
13. 面对模棱两可,拒绝猜测
重要的是要不断学习,享受挑战,容忍歧义。我们都不知道最终会怎样。——玛蒂娜·霍纳
这句话优雅而抒情,但在编程中不是一个好的隐喻。歧义可能是指不清楚的语法、复杂的程序结构或触发错误消息的错误。例如,第一次使用numpy模块时的一个简单错误:
1 | |
ValueError: 具有多个元素的数组的真值不明确,请使用 a.any() 或 a.all()
如果执行上面代码,你将在输出中发现一个由 5 个布尔值组成的数组,表明值在 3 以下。因此,if语句不可能确定状态。消息中显示的内置函数.all() 和.any()用于代替 And/Or。
1 | |
输出表明,.all()仅在所有项都为True时才返回True,而.any()在有一项为True时就返回True。
14. 解决问题最直接的方法应该有一种,最好只有一种
想想为什么 Python 被描述为一种易于学习的编程语言。Python 具有非凡的内置函数 / 库和高度的可扩展性,它鼓励程序员优雅地编写代码。尽管有更多的解决方案可以提供灵活性,但对于同一个问题,它们可能会花费更多时间。

输入 import antigravity 并执行
15. 当然这是没法一蹴而就的,除非你是荷兰人
Python 之父 Guido van Rossum 是一位荷兰程序员,他让这句格言变得无可争议。你不会声称自己比他更了解 Python……至少我不会。
16. 做也许好过不做
你可以拖延,但时间不会,失去的时间一去不复返。——本杰明·富兰克林
对于那些像我一样患有拖延症,正在寻求改变的人,看看这个,和恐慌怪兽合作。
https://embed.ted.com/talks/tim_urban_inside_the_mind_of_a_master_procrastinator
另一方面,这个格言的另一个方面是阻止你过度计划,这并不比看 Netflix 更有效率。
拖延和过度计划的共同特征就是“什么都做不了。”
17. 不想就做还不如不做
“做也许好过不做”并不意味着计划没用。把你的想法写下来,设定一个要征服的目标,比不想就做要好。
例如,我通常在每个星期天花一个小时来制定我的周计划,并在睡觉前更新我明天的计划,看看有什么需要推迟的事情。
18. 如果解决方案难以解释清楚,那一定很糟糕
回想一下“复杂胜于晦涩”的理念。通常,晦涩的代码意味着弱设计,特别是在像 Python 这样的高级编程语言中。
然而,在某些情况下,其领域知识的复杂性可能会让实现难以解释,而如何优化让其明晰易懂至关重要。这里有一个规划项目指南,可以给你提供帮助。
https://docs.python-guide.org/writing/structure/
19. 如果实现容易描述,那可能是个好方案
使设计(甚至人们的生活)更容易,即使背景知识可能很深刻,这是编程的专业知识,我认为也是编程中最困难的部分。
利用 Python 的简单性和可读性来实现一些疯狂的想法。
20. 命名空间是一种绝妙的理念,多加利用!
最后但同样重要的是,命名空间是一组符号,用于组织各种对象,以便这些对象可以通过惟一的名称引用。在 Python 中,命名空间是由以下元素组成的系统:
- 内置命名空间:可以在不创建自定义函数或导入模块(如
print()函数)的情况下调用。 - 全局命名空间:当用户创建一个类或函数时,将创建一个全局命名空间。
- 局部命名空间:局部作用域中的命名空间。
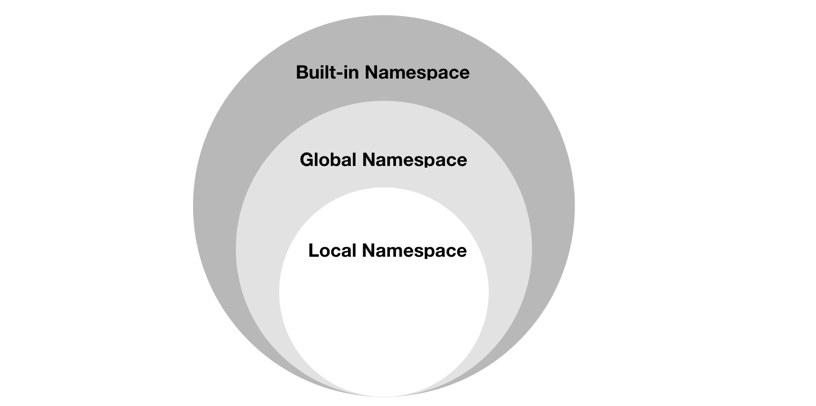
命名空间关系图
命名空间系统可以防止 Python 模块名称之间产生冲突。
延展阅读:
11.6 【代码美化】择优选择 EAFP 和 LBYL 代码风格
1. EAFP 风格
Python 有一套自己的哲学,其中 EAFP 是其中比较有名的。它的全称是
Easier to Ask for Forgiveness than Permission
强行翻译一下,就是 寻求原谅比获得授权更容易。
对于第一次接触这个 EAFP 名词的同学,可能不好理解这句话的意思。
没有关系,咱先看一下 EAFP 风格的代码是什么样的,你就能立马 get 了。
下面这段代码,我在 try 里使用 [key] 的方法获取字典一个 value 值,但是由于 profile 并没有 age 的键。所以会抛出异常。
1 | |
像这种,先相信代码本身没有问题,任其执行,有问题了再通过捕获进行处理的代码风格,就叫做 EAFP 风格。
我个人把这种写法,称之为 面向崩溃编程。
2. LBYL 风格
LBYL 的全称是
Look Before You Leap
翻译一下,就是 你跳之前先看看,这是一种比较保守的写法。这种写法可能会有让你写很多的 if 判断语句来规避可能出现错误的各种场景。
还是以上面的代码为例,使用 LBYL 风格来写的话,是这样的
1 | |
3. 选择哪种风格?
用一个生动的例子来描述他们的区别。
有一对小伙伴一起约去某名山游玩,由于这座山比较险峻,有各种各校的悬崖。
伙伴A,是一个比较大胆开放的人,他自己穿上了降落伞,所以在游玩的时候,无所顾忌,都不看路,一旦不小心跌落悬崖了也有降落伞保命。 – 这是 EAFP 风格
而伙伴B,是一个比较保守的人,他没有穿降落伞,所以每走一走都要看一看,前面是不是悬崖。– 这是 LBLY 风格
EAFP虽然是 Python 比较推荐的一种编码风格,但更多情况下,这两种风格会同时存在于你的代码中代码风格的目的是增强代码的可读性和健壮性,在有些场景下 EAFP 风格更加易读,在有些场景下 LBLY 风格更加易读,因此不必纠结使用哪种风格,具体情况应该具体分析。## 11.7 【代码美化】使用 flake8 保证代码风格
pep8 是Python 语言的一个代码编写规范。如若你是新手,目前只想快速掌握基础,而不想过多去注重代码的的编写风格(虽然这很重要),那你可以尝试一下这个工具 - autopep8
首先在全局环境中(不要在虚拟环境中安装),安装一下这个工具。
1 | |
然后在 PyCharm 导入这个工具,具体设置如下图
1 | |
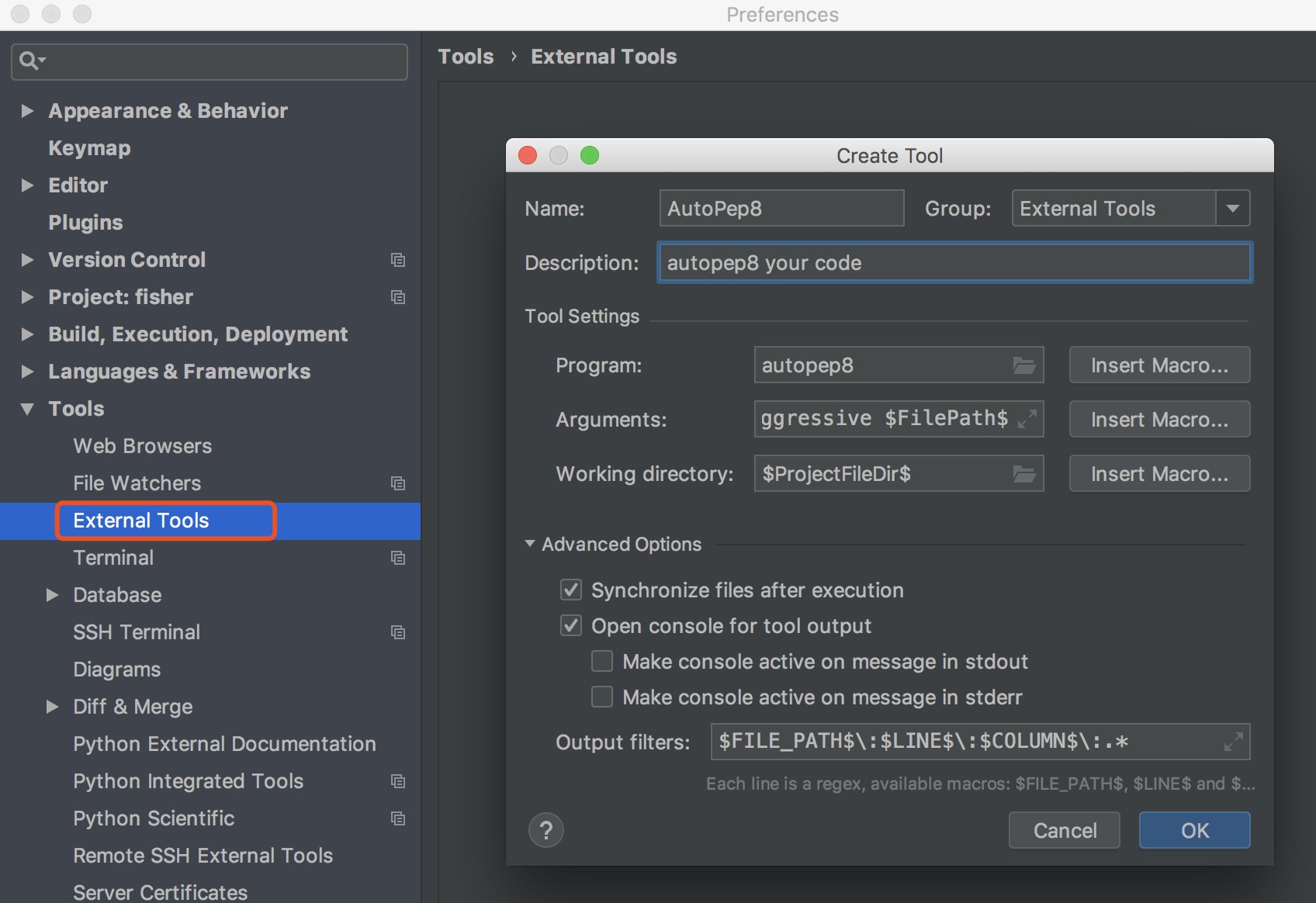
我随意写了一段不符合 pep8 规范的代码。
点击右键,选择 External Tools -> AutoPep8
看一下效果,还是挺明显的。

你可能会说,Pycharm 本身就自带这个功能了呀,快捷键 Command+Option+L ,就可以实现一键pep8了。你可以对比一下,Pycharm 自带的代码 pep8 化功能 并没有像这个autopep8 来得彻底。 我相信你最终的选择肯定是后者。
第十二章:虚拟环境
12.1 【虚拟环境】为什么要有虚拟环境?
虚拟环境的意义,就如同虚拟机 一样,它可以实现不同环境中Python依赖包相互独立,互不干扰。
举个例子吧。
假设我们的电脑里有两个项目,他们都用到同一个第三方包,本来一切都顺利。但是由于某种原因,项目B由于某些原因要使用这个第三方包的一些新特性(新版本才有),而如果就这样贸然升级了,对项目A的影响我们无法评估,这个时候我们就特别需要有一种解决方案可以让项目A和B,处于两个不同的Python环境中。互不影响。
为了方便大家对虚拟环境有个认识,我列举了下其优点:
- 使不同应用开发环境独立
- 环境升级不影响其他应用,也不会影响全局的python环境
- 可以防止系统中出现包管理混乱和版本的冲突
市场上管理 Python 版本和环境的工具有很多,这里列举几个:
p:非常简单的交互式 python 版本管理工具。pyenv:简单的 Python 版本管理工具。Vex:可以在虚拟环境中执行命令。virtualenv:创建独立 Python 环境的工具。virtualenvwrapper:virtualenv 的一组扩展。
工具很多,但个人认为最好用的,当属 virtualenvwrapper,推荐大家也使用。 ## 12.2 【虚拟环境】方案一:使用 virtualenv
1. 安装virtualenv
由于 virtualenvwrapper 是 virtualenv 的一组扩展,所以如果要使用 virtualenvwrapper,就必须先安装 virtualenv。
基本使用
由于virtualenv创建虚拟环境是在当前环境下创建的。所以我们要准备一个专门存放虚拟环境的目录。(以下操作在Linux在完成,windows相对简单,请自行完成,有不明白的请微信与我联系。)
创建
1 | |
进入/退出
1 | |
删除
删除虚拟环境,只需删除对应的文件夹就行了。并不会影响全局的Python和其他环境。
1 | |
注意:
创建的虚拟环境,不会包含原生全局环境的第三方包,其会保证新建虚拟环境的干净。
如果你需要和全局环境使用相同的第三方包。可以使用如下方法:
1 | |
2. 使用 virtualenvwrapper
virtualenv 虽然已经相当好用了,可是功能还是不够完善。
你可能也发现了,要进入虚拟环境,必须得牢记之前设置的虚拟环境目录,如果你每次按规矩来,都将环境安装在固定目录下也没啥事。但是很多情况下,人是会懒惰的,到时可能会有很多个虚拟环境散落在系统各处,你将有可能忘记它们的名字或者位置。
还有一点,virtualenv 切换环境需要两步,退出 -> 进入。不够简便。
为了解决这两个问题,virtualenvwrapper就诞生了。
安装
1 | |
配置
先find一下virtualenvwrapper.sh文件的位置
1 | |
若是 windows 则使用everything 查找 virtualenvwrapper.bat 脚本
1 | |
在~/.bashrc 文件新增配置
1 | |
若是 windows 则新增环境变量:WORKON_HOME
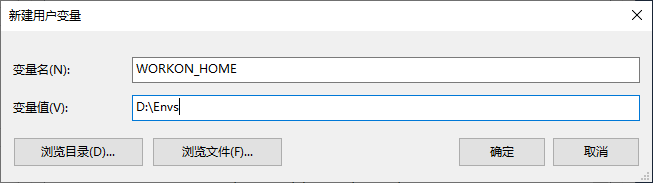
基本语法:
mkvirtualenv [-a project_path] [-i package] [-r requirements_file] [virtualenv options] ENVNAME
常用方法
1 | |
其他命令
1 | |
更多内容,可查看 官方文档
https://virtualenvwrapper.readthedocs.io/en/latest/command_ref.html
3. 实战演示
以上内容,是一份使用指南。接下来,一起来看看,如何在项目中使用虚拟环境。
如何使用在我们的开发中使用我们的虚拟环境呢
通常我们使用的场景有如下几种
- 交互式中
- PyCharm中
- 工程中
接下来,我将一一展示。
3.1 交互式中
先对比下,全局环境和虚拟环境的区别,全局环境中有requests包,而虚拟环境中并未安装。
当我们敲入 workon my_env01,前面有my_env01的标识,说明我们已经处在虚拟环境中。后面所有的操作,都将在虚拟环境下执行。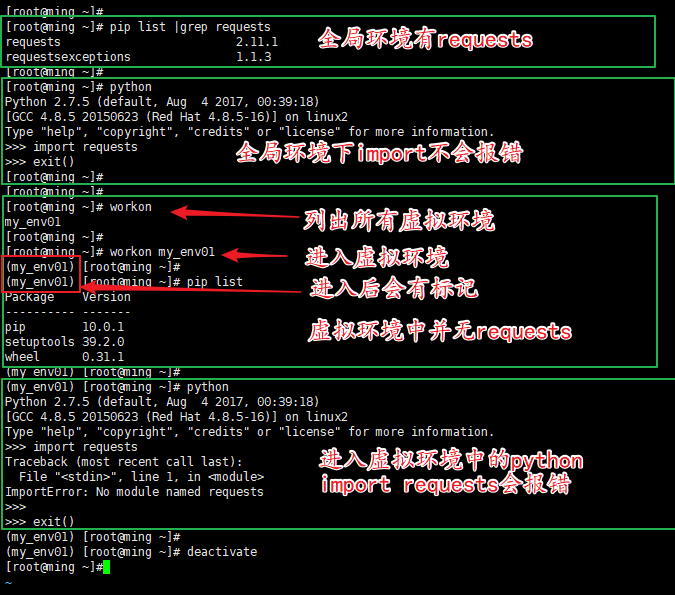
3.2 工程项目中
我们的工程项目,都有一个入口文件,仔细观察,其首行可以指定Python解释器。
倘若我们要在虚拟环境中运行这个项目,只要更改这个文件头部即可。
现在我还是以,import requests 为例,来说明,是否是在虚拟环境下运行的,如果是,则和上面一样,会报错。
文件内容:
1 | |
运行前,注意添加执行权限。
1 | |
好了。来执行一下
1 | |
发现和预期一样,真的报错了。说明我们指定的虚拟环境有效果。
3.3 PyCharm中
点击 File - Settings - Project - Interpreter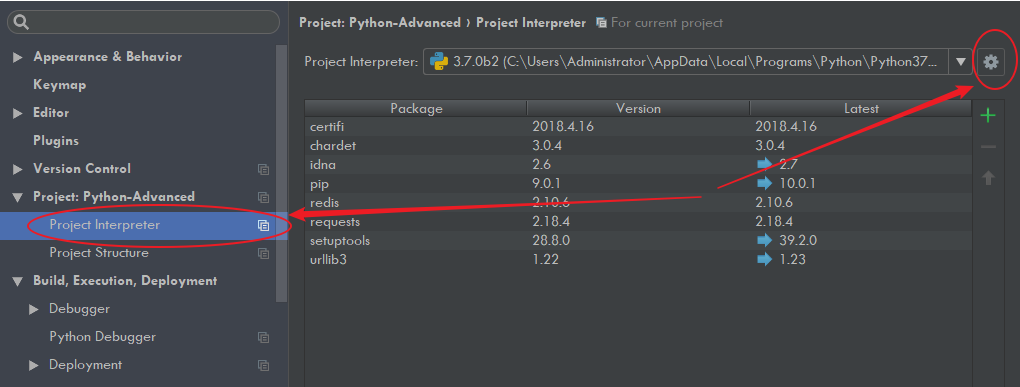
点击小齿轮。如图点击添加,按提示添加一个虚拟环境。然后点 OK 就可以使用这个虚拟环境,之后的项目都会在这个虚拟环境下运行。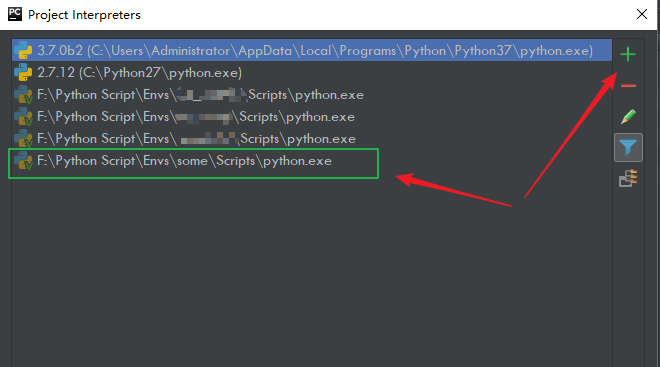
12.3 【虚拟环境】方案二:使用 pipenv
以前一直使用pip+virtualenv+virtualwrapper管理模块和环境, 但是virtualwrapper在windows上使用不太方便,而且包和环境分开管理确实经常不记得哪个是哪个了。
为什么 会推荐 pipenv 呢?
- 它是
virtualenv和pip的合体,可以合起来使用; - 使用
Pipfile和Pipfile.lock替代requirements.txt - 可以使用
pipenv graph很方便的看出包的依赖关系。 - 通过加载
.env文件简化开发工作流程
1. 安装pipenv
如果你的电脑上没有安装 pipenv,可以使用如下方法安装
1 | |
如果你的电脑是 windows 的。
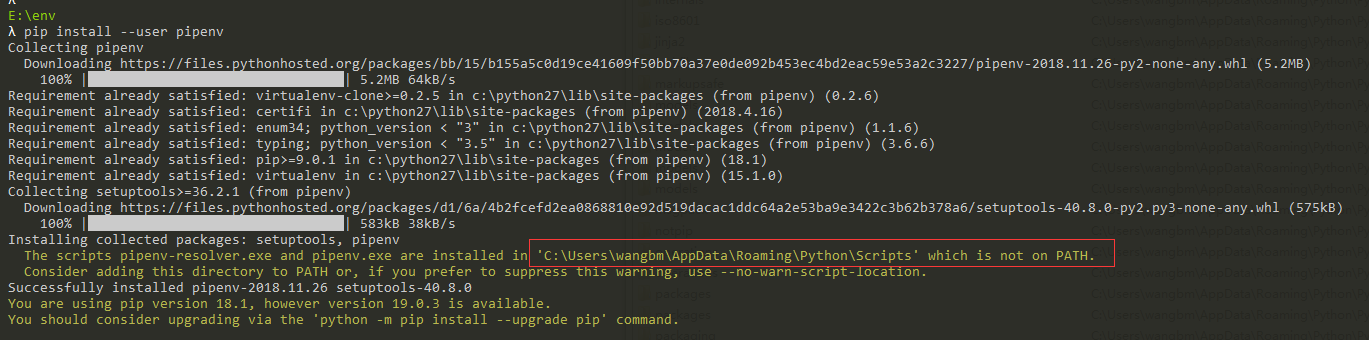
需要将如标示路径,加入到 环境变量 PATH 中。
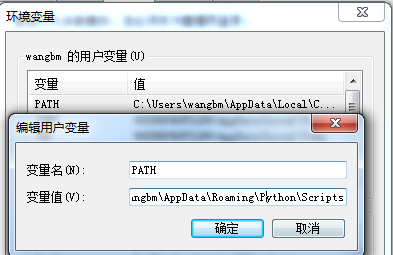
然后需要重启一下,CMD 终端才能够刷新环境变量。
2. 创建虚拟环境
DjangoWebBlog 是我们的项目目录,进入这个目录下创建虚拟环境
1 | |
你也可以指定版本创建
1 | |
这边以安装 python2 版本的虚拟环境为例说明。
如果你原项目使用的是 requirements.txt 这个管理包的方式,这时候执行 pipenv --tow 创建一个虚拟环境后,会找到 requirements.txt ,并根据这里面的依赖包生成 Pipfile文件。

3. 查询虚拟环境
1 | |
演示如下:
4. 操作虚拟环境
1 | |
执行 pipenv shell 就可以进入这个虚拟环境,在头部会有虚拟环境的标识名称。有这个标识,说明已经进入虚拟环境。
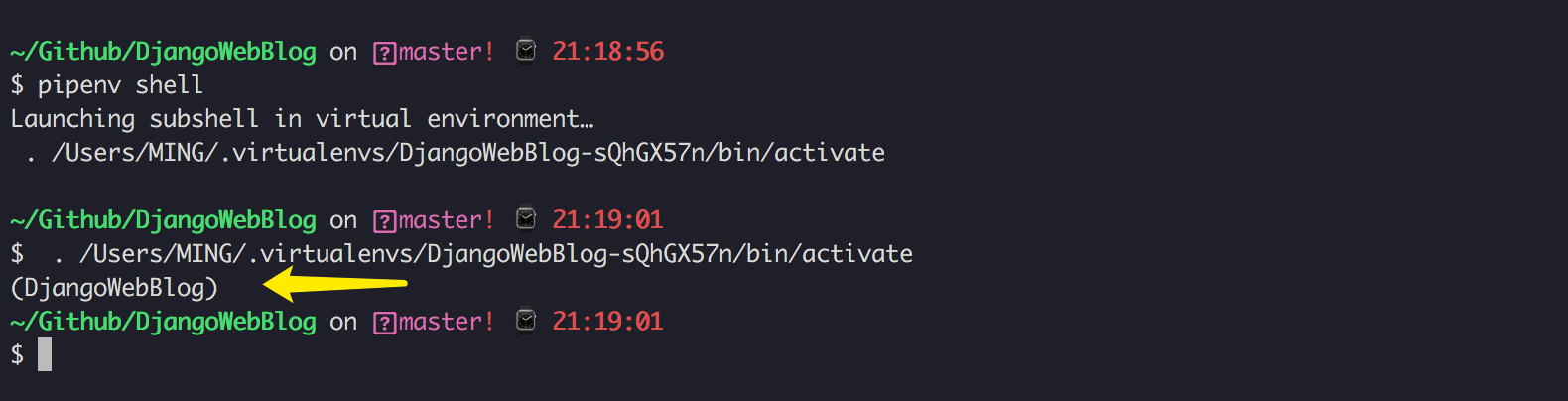
1 | |
5. 虚拟环境包管理
1 | |
6. 其他命令
1 | |
打印该虚拟环境下所有包的依赖关系图

有的python第三方包旧版本会有安全漏洞,使用 pipenv check 可以检查安全漏洞。

12.4 【虚拟环境】方案三:使用 pipx
1. 什么是 pipx
pipx 是一款用于帮助你安装和运行那些用 python 编写的终端程序,它类似于 macOS 上的 brew,Ubuntu 上的 apt,CentOS 上的 yum。
pipx 依赖 pip 和 venv,它只能在 python 3.6+ 的 Python 版本中才能使用。
默认情况下,pipx 和 pip 一样会从 pypi 上安装包,同时 pipx 也能像 pip 一样从本地、git仓库、wheel 文件中安装包。
为了避免你在安装 python app时,由于多版本而导致冲突,通常我们会使用 venv 或者 virtualenv 新建一个虚拟环境,然后将 app 安装到虚拟环境中。
后续你对这个 app 的管理操作,都得先进入这个虚拟环境。
发现没有?好像有点麻烦。
pipx 的存在使这个流程变得更加舒畅,使用 pipx 你可以无需关注虚拟环境的存在,并在你的机器上安装多个版本的 python app。
2. 安装使用
安装 pipx
1 | |
使用 Pipx 需要注意两个路径
- 二进制文件的保存位置:默认是
~/.local/bin,可使用环境变量PIPX_BIN_DIR进行更改,或者执行如下命令(python3 -m userpath append ${you_path}) - 虚拟环境的保存位置:默认是
~/.local/pipx,可使用环境变量PIPX_HOME进行更改
在我安装好 pipx ,准备使用的时候,发现全局找不到 pipx 这个命令。
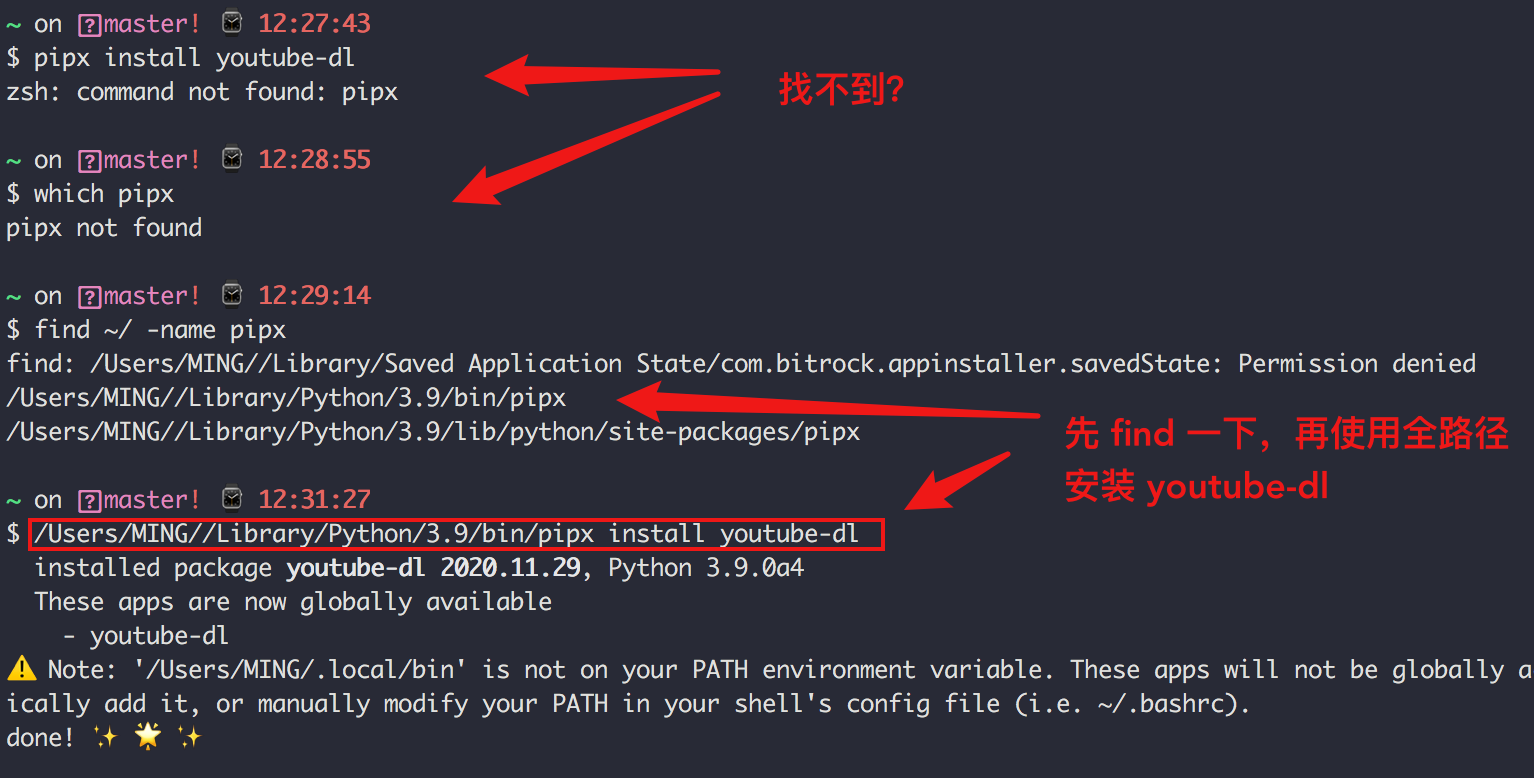
按照如上图所示,难道使用全路径执行命令?
不,怎么都觉得不太对劲。。
想要解决这个问题,其实很简单,有两种方法(两种都可以,我演示使用的第一种方法):
- 添加个软链接指向刚刚那个全路径就好啦
- 将这个路径添加到 PATH 中
/Users/MING/Library/Python/3.9/bin/
1 | |
软链接建好后,就可以直接使用 pipx 的命令啦。

刚刚我使用 pipx 安装了 youtube-dl 后,其实并没有将这个 youtube-dl 安装到系统全局的 Python 环境中。
还记得最开始,我强调过两个非常重要的路径吗?
现在来看一下,这个路径下面都有哪些东西?
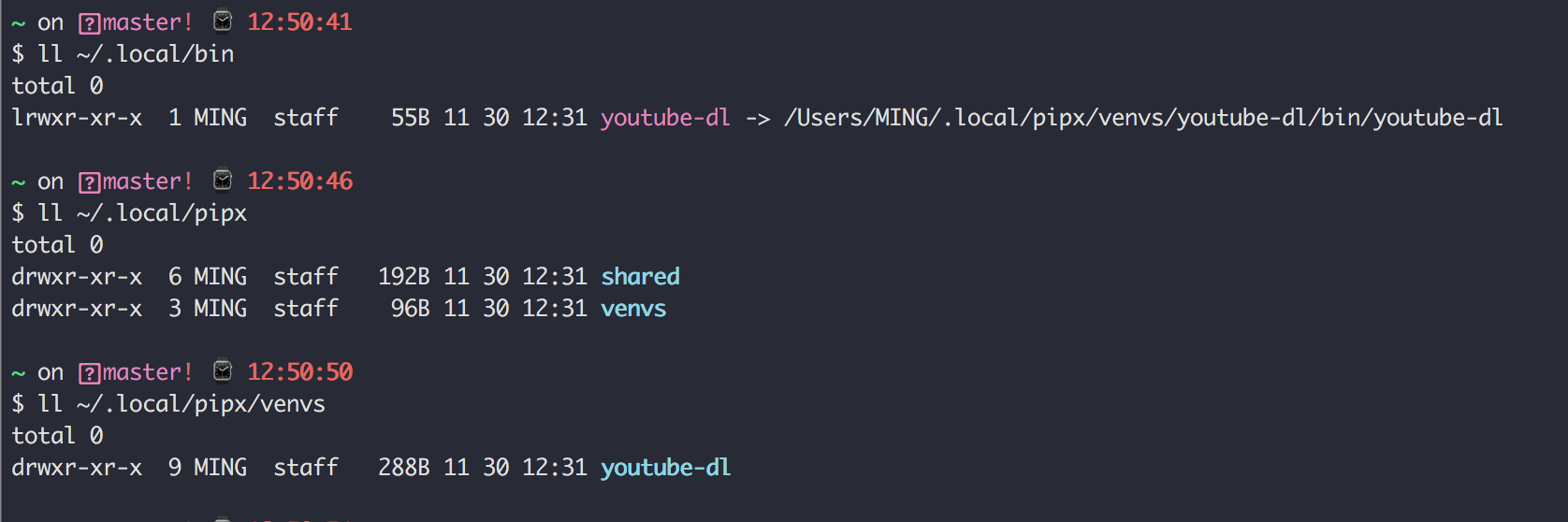
从截图上可以看出
- pipx 在
~/.local/pipx/venvs目录下新建了个名叫youtube-dl的虚拟机环境 - 并将
youtube-dl安装到这个虚拟机环境中 - 然后在
~/.local/bin的目录下新建一个软链接,指向这个虚拟环境中 - 这样
youtube-dl就变成全局的工具啦。
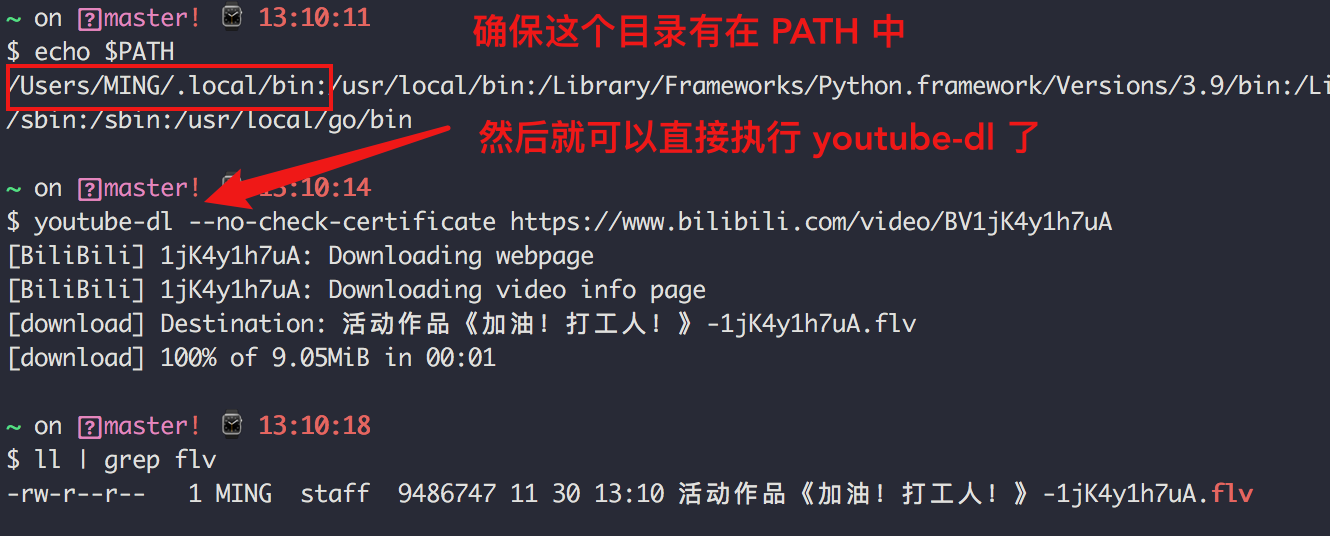
为了避免你新安装的 youtube-dl 与全局的冲突,你也可以指定 pipx 的命令来运行 youtube-dl
1 | |
运行效果如下:

pip run 也可以直接执行在线的 python 脚本
1 | |
3. 查看包
查看已安装过的包
1 | |
4. 安装包
下载最新版本的 python 包,并安装到新建的虚拟环境中
1 | |
4. 运行APP
pipx run 后面可接一个包的 url 链接,会将这个包下载下来并运行,也可以接已安装过的应用名来直接运行它
1 | |
如果一个 app 有多个版本,那么可以通过 spec 指定版本号
1 | |
更神奇的是,pipx 支持指定 git 代码仓库直接运行
1 | |
5. 升级包
升级某个包
1 | |
升级全部包
1 | |
6. 卸载包
卸载某个包
1 | |
卸载全部包
1 | |
重装全部包
1 | |
7. 使用 pip
每执行一次 pipx install 就会新建一个虚拟环境,那我们有没有办法管理这些虚拟机环境呢?
比如我想看这个虚拟环境里安装了哪些包?
使用如下命令就可以像使用 pip 一样,来管理 pipx 的虚拟环境
1 | |
效果如下
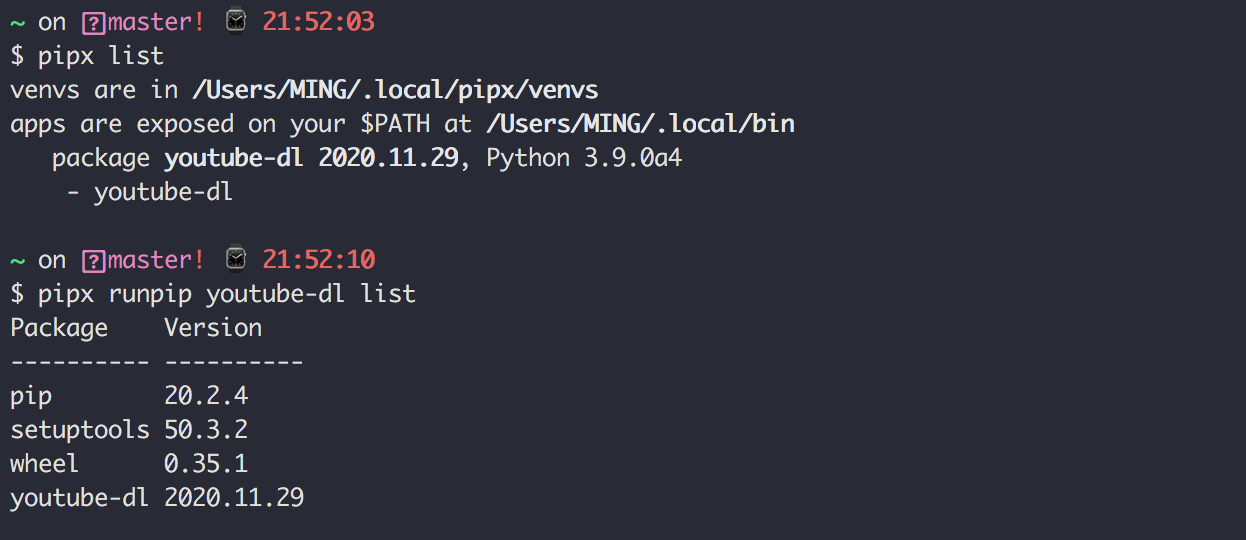
8. 其他
执行 pipx completions 可以启用 pipx 的补全说明。
对于不同的终端开启方式不一样,我使用的是 zsh,方法是
1 | |
我安装好后,可以使用 tab 键进行命令补全。
执行 pipx ensurepath 可以确保 ~/.local/bin 这个重要的目录,已经放入到 $PATH 的变量中。
9. pipx vs pip
pipx 只是解决 pip 的一个痛点,因此他的适用场景比较单一,它只适用于安装和运行那些有提供命令行入口的app。
- pip 适用于大多数的 Python 版本,而 pipx 需要 Python 3.6+ 才可以使用
- pipx 依赖 pip 和 venv,可以使用 pip 安装pipx ,反过来则不行。
- pip 和 pipx 默认都是从 pypi 上安装包
- pipx 在安装和管理 cli 应用程序时,比 pip 更灵活,它可以在允许在隔离环境中安装和运行 Python 应用
10. 参考文章
- https://github.com/pipxproject/pipx
- https://pipxproject.github.io/pipx/comparisons/## 12.5 【虚拟环境】方案四:使用 poetry
1. 安装 poetry
poetry提供多种安装方式,个人推荐从以下2种方式中选择:
方式一:(推荐)使用在线脚本进行安装,是最为推荐的安装方式
1 | |
方式二:(pip) 官方不建议这么做,因为有可能会造成依赖冲突,可以考虑用 pipx 或 pipsi
1 | |
安装后,可以使用如下命令检测是否可用
1 | |
如果不可用,可能是环境变量没有设置
1 | |
我使用第一种方法,安装后,会自动把设置环境变量的命令写入 .zshrc,要使之立即生效,需要手动 source 下
1 | |
2. 创建项目
如果你是在一个已有的项目里使用 Poetry,你只需要执行 poetry init 命令来创建一个 pyproject.toml 文件:
1 | |
而如果是新建 一个项目,可以使用这个命令
1 | |
运行完后,在当前目录下就会多一个 demo-project 的目录,这个目录下的文件结构如下
1 | |
如果要把项目代码放入到 src 目录下,在创建项目时,可以加上 --src 参数。
3. 创建虚拟环境
使用 poetry install 命令创建虚拟环境(确保当前目录有 pyproject.toml 文件):
1 | |
这个命令会读取 pyproject.toml 中的所有依赖(包括开发依赖)并安装,如果不想安装开发依赖,可以附加 –no-dev 选项。如果项目根目录有 poetry.lock 文件,会安装这个文件中列出的锁定版本的依赖。如果执行 add/remove 命令的时候没有检测到虚拟环境,也会为当前目录自动创建虚拟环境。
4. 使用虚拟环境
创建虚拟环境后,如果想要在虚拟环境下执行命令,比如去执行脚本,去使用 pip list 等等。
可以在项目目录下,使用如下命令
1 | |
比如我查看该虚拟环境中安装了哪些包
1 | |
再比如我想在该虚拟环境下执行 app.py
1 | |
每次在虚拟环境下做点啥事,命令前面都要加上 poetry run,有点太麻烦了。
这时可以使用下面这条命令,直接激活当前的虚拟环境
1 | |
5. 包的管理
安装包
1 | |
添加 –dev 参数可以指定为开发依赖
1 | |
查看所有安装的依赖包
1 | |
加上 --tree 可以查看他们的依赖关系
1 | |
加上 --outdated 可以查看可以更新的依赖
1 | |
如果要更新依赖可以执行这个命令
1 | |
想卸载某个包,用这个命令
1 | |
6. 常用配置
Poetry 的配置存储在单独的文件中,比 Pipenv 设置环境变量的方式要方便一点。配置通过 poetry config 命令设置,比如下面的命令可以写入 PyPI 的账号密码信息:
1 | |
下面的命令设置在项目内创建虚拟环境文件夹:
1 | |
另一个常用的配置是设置 PyPI 镜像源,以使用豆瓣提供的 PyPI 镜像源为例,你需要在 pyproject.toml 文件里加入这部分内容:
1 | |
7. 参考文章
- 相比 Pipenv,Poetry 是一个更好的选择
- 从国内的 PyPI 镜像(源)安装 Python 包## 12.6 【虚拟环境】方案五:使用 venv
在前面介绍的几种方法中,都需要借助第三方模块来完成虚拟环境的管理。
但其实在 Python 3 中就自带了一个专门用门管理虚拟环境的模块,它叫 venv。
1. 创建虚拟环境
venv 后可以接一个目录(如果此目录不存在,会自动创建)用于创建你的虚拟环境,他可以是绝对路径,也可以是相对路径。
1 | |
使用 venv 创建虚拟环境的速度非常快,大概只需要两三秒的样子。
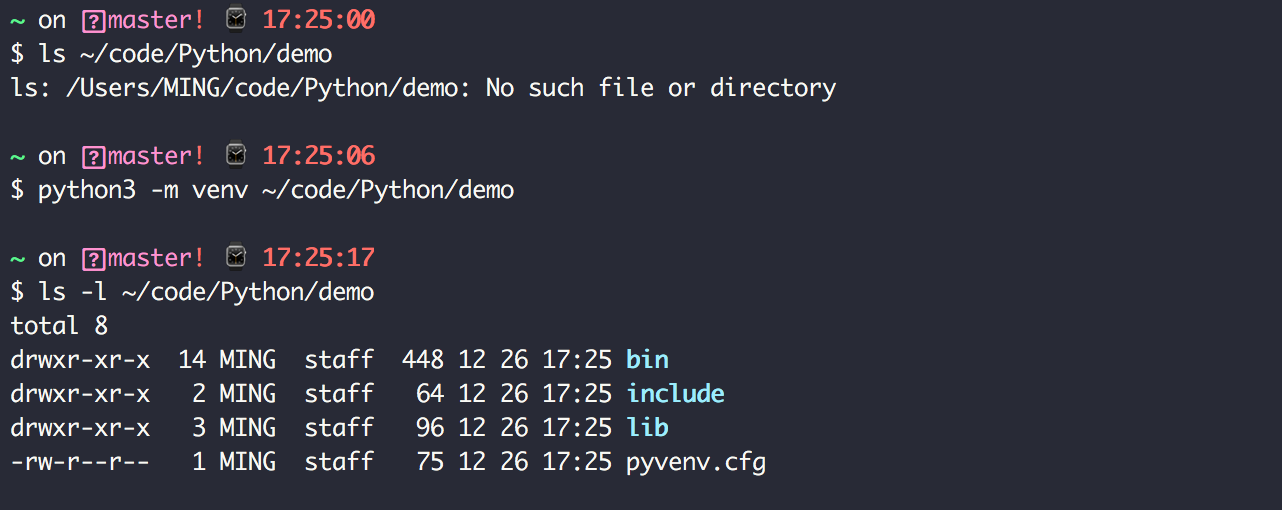
创建完成后,在你所指定的目录下会有一个 pyvenv.cfg 的配置文件,它记录着虚拟环境的基本信息,包括你使用的 Python 的家目录,还有当前虚拟环境的 Python 版本,是否开启使用系统的 site-packages 模块,如果开启了,那么当你就可以直接使用系统中已经装过的第三方模块,但是你在虚拟环境下装的模块就不能被其他地方的程序使用。
1 | |
如果你的环境中有 Python 3.8 也有 Python 3.9 ,那该怎么办呢?
只要你在创建时,用你预期版本的 Python 去执行就好啦
1 | |
可如果你的环境中有两个 Python 3.9 呢?你想使用不在 PATH 的中的 Python 去创建,就要用绝对路径去创建了。
1 | |
2. 进入创建环境
进入虚拟环境的方法,对比之前介绍的方案,venv 的方法就相当原始了。
如果你使用 Windows ,那么在 cmd 下进行 Scripts 目录,执行 activate.bat
1 | |
如果你使用PowserShell激活虚拟环境出现如下错误,那要先执行这个命令:Set-ExecutionPolicy RemoteSigned,再按 Y
而如果你使用的 Mac 或者 Linux,那么直接执行下面命令就行
1 | |
执行完后,若在你的命令行下有 demo 字样(之所以是 demo ,因为我们创建时的目录名就是 demo),说明你已经处于虚拟环境下。 由于虚拟环境是全新的干净环境,此时你使用 pip list ,会看到啥包都没有,只有最基本的 pip 和 setuptools 。
3. 退出虚拟环境
退出虚拟环境,无论是 Windows 、 Mac 、 还是 Linux ,方法都是同一条命令。退出后,你的虚拟环境名称(如上面的 demo )也会消失。
1 | |
4. 总结一下
venv 是 Python3 中自带的虚拟环境管理工具,不需要额外安装,功能简单,用法也简单。但是它不能像 poetry 和 pipenv 用于项目的管理,因此 venv 建议只做了解,在一些简单的场景中可以使用,如果是复杂的项目中,可以直接上 poetry 和 pipenv。
12.7 【本地环境】方案六:使用 PDM
PDM 是一个新的 Python 的包管理器,也许你还未知晓它的存在,但实际上PDM 已经诞生两年,并在 2021 年发布 1.0 版本,目前最高的版本是 1.12.8。
在刚听到 PDM 时,我下意识认为它是 Python Development Manager,又一个和 Pipenv 和 Poetry 一样换汤不换药的虚拟环境管理工具。
一直到我翻到了作者的博客,才知道 PDM 的全称是 Python Development Master,比我想像的还要牛逼一个档次。
值得一提的是,PDM 的作者是 PyPa 成员、Pipenv 目前主要的维护者之一,最重要的是,是他是中国人,因此这是一款国人开发的工具。
1. Why PDM?
早期的包管理器(如 Pipevn,Poetry),都是基于虚拟环境的,虚拟环境主要是为了隔离项目开发环境,但如果涉及到虚拟 环境嵌套虚拟环境,问题就难搞了,经常会出现问题。
PDM 得益于一个 2018 年的 PEP 提案(PEP582,Python local packages directory),完全摒弃了虚拟环境。
从作者的博客上来看,当初之所以要重复造个轮子,完全是因为 Pipenv 和 Poetry 都不够好用,正好有 PEP582 ,可以开发一个划时代的 Python 包管理工具,它就是 PDM 。
PDM 包含如下特性:
- PEP 582 本地项目库目录,支持安装与运行命令,完全不需要虚拟环境。
- 一个简单且相对快速的依赖解析器,特别是对于大的二进制包发布。
- 兼容 PEP 517 的构建后端,用于构建发布包(源码格式与 wheel 格式)
- 拥有灵活且强大的插件系统(有插件系统直接就拉开一个档次)
- PEP 621 元数据格式
- 像 pnpm 一样的中心化安装缓存,节省磁盘空间
尽管 PDM 是国人开发,但考虑到国际化,官网文档是全英文的。
我花了整整一天,通读完文档,消化了 70% 的 PDM 用法,现将心得整理分享出来,会对你上手 PDM 有帮助。
关于 PDM,内容挺多的,打算分两篇文章来完整地介绍它:
- 面向新手的入门级教程
- 面向骨灰级选手的教程
本篇是第一篇,先让大家对 pdm 的基本用法有一个框架性的理解,而 pdm 真正竞争力请持续关注后续文章。
2. 安装 PDM
PDM 的安装方法有很多种,在官网上就有 6 种,比如 pip、pipx、homebrew 等
在以前的文章中,我推荐过 pipx 工具,在安装那种命令行应用的包时非常好用。
而此时 PDM 就是一个命令行工具,因此我也推荐使用 pipx 安装,方便统一对命令行进行管理
执行 pipx install pdm 即可安装
PDM 只有 Python 3.7+ 的版本才能使用,使用其他的方法安装,要先保证你的 Python 版本,但使用 pipx 则不需要你去操心。
3. 初始化 PDM
执行 pdm init 就会开始初始化,初始化的时候,会让你选择项目的一些信息
- 是否要上传 PyPI
- 依赖的 Python 版本
- License 类型
- 作者信息
- 邮箱信息
我机器上有 Python 2.7 和 Python 3.10 两个版本,在初始化项目时会把机器上的所有 Python 版本都扫描出来了,会让选择项目的 Python 版本。
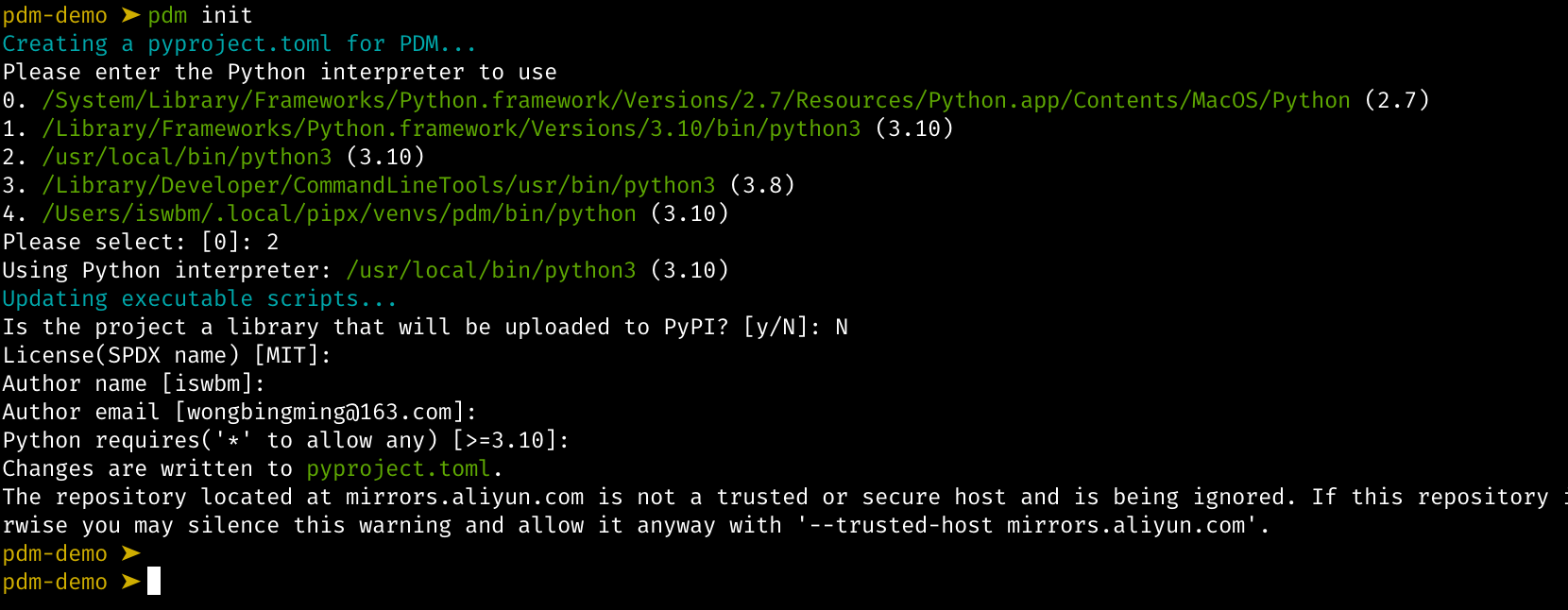
完成之后,PDM 会将你的选择以 toml 格式写入 pyproject.toml 配置文件中。
4. PDM 用法
pdm 有非常多的命令,使用 -h 可以看到帮助菜单
4.1 安装包
和 Poetry 一样,安装使用的是 add 命令,但 pdm 的 add 比 poetry 好用,主要体现在分组,具体请关注后续文章
4.2 查看包
使用 pdm list 可以以列表形式列出当前环境已安装的包
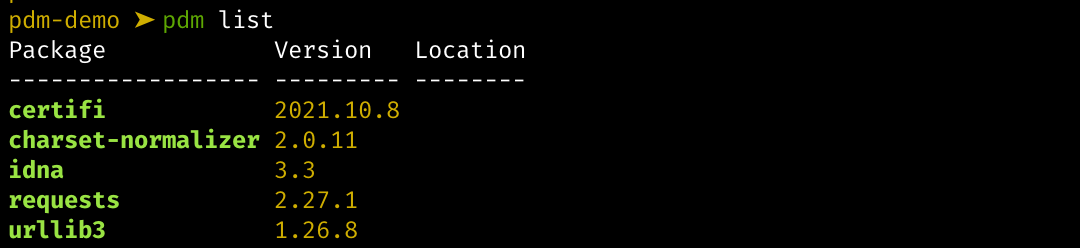
再加个 --graph 就能以树状形式查看,直接依赖包和间接依赖包关系的层级一目了然
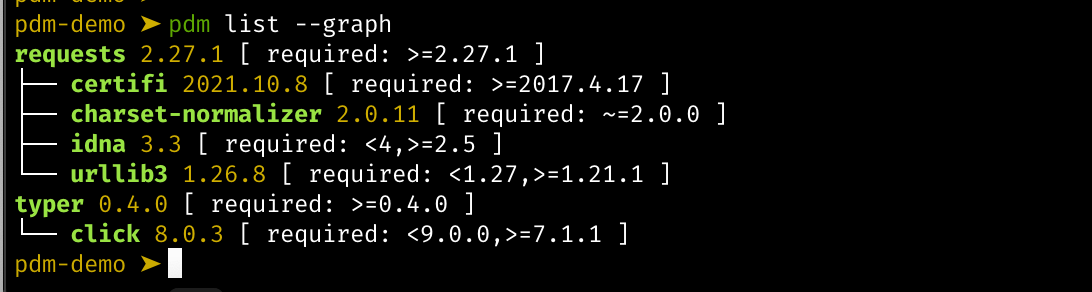
pdm list 还有两个选项:
--freeze:以 requirements.txt 的格式列出已安装的包--json:以 json 的格式列出已安装的包,但必须与--graph同时使用
要查看某个包的某体详情,直接用 pdm show 即可
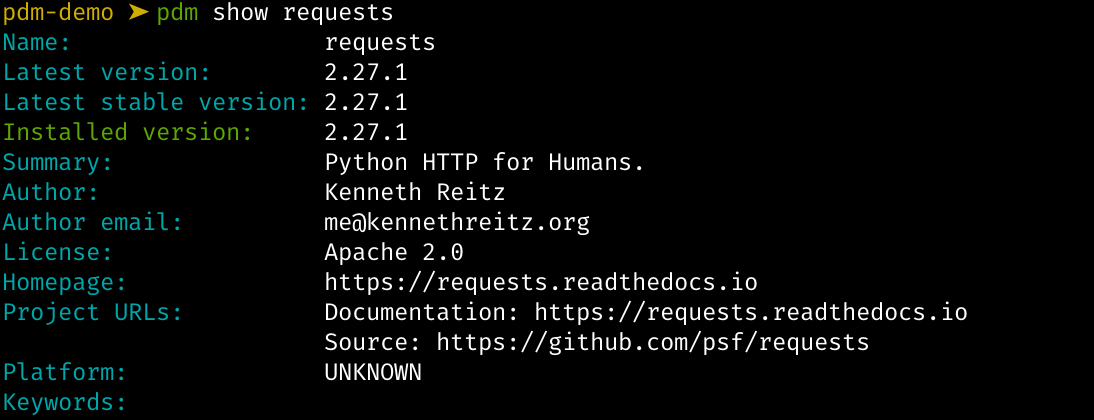
4.3 删除包
删除包使用的是 remove 命令
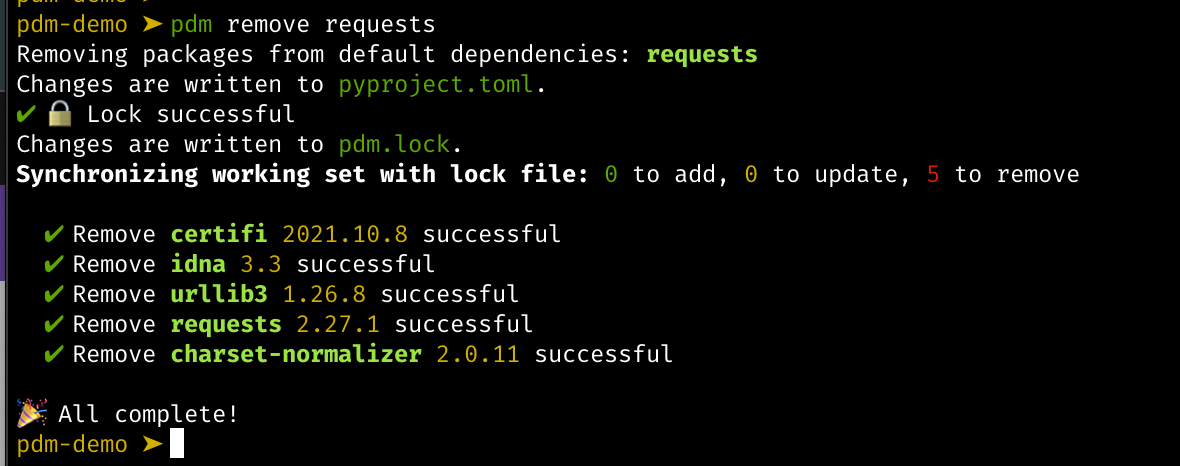
4.4 项目配置
不加任何参数,可以打印出该项目的环境配置
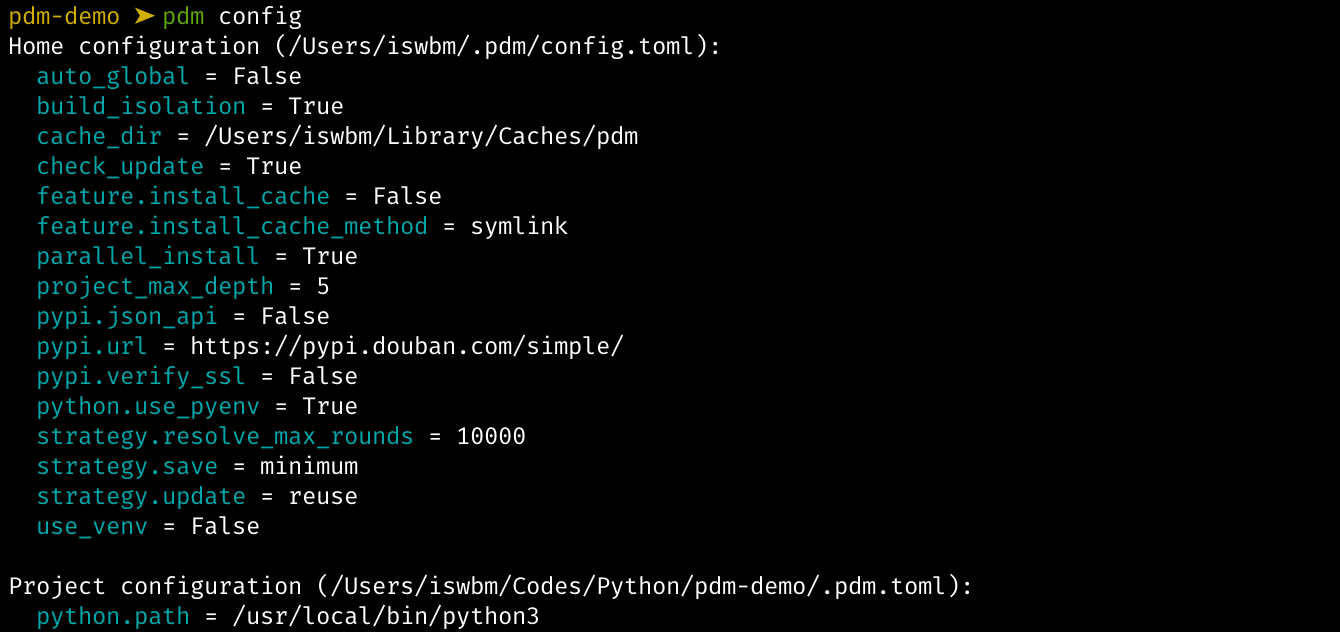
想要修改的话,只要加 key 和 value 做为参数即可,以修改 pypi 镜像代理为例
原来上面是豆瓣源,现在我要改成阿里源,只需要执行如下命令,可比 poetry 方便多啦~

pdm config 里面有非常多的配置,想要一一搞清楚的可以去官网查阅:https://pdm.fming.dev/configuration/
4.5 运行命令
想要在 pdm 的环境中执行命令或者项目,可以使用 run 命令,若是执行项目时,有诸多参数,可以在 pyproject.toml 配置命令别名,具体用法,请往后看

4.6 查看环境
使用 info 命令,可以查看当前项目的环境信息
4.7 更新包
更新的话,简单的场景下,使用下面这两条即可
1 | |
复杂的场景,pdm 也都为你考虑到了,它提供了很多选项,可以根据需要使用(以下如有解释错误,请帮忙指正)
--save-compatible:项目依赖可兼容的版本--save-wildcard:保存通配符版本(暂不明白)--save-exact:保存有指定确切版本的包--save-minimum:保持最小版本的包--update-reuse:尽量只更新命令行中指定的包,其依赖包能不更新则不更新--update-eager:更新某个包顺带更新其依赖包(递归升级)--prerelease:允许提前释放(暂不明白)--unconstrained:忽略包版本的约束,可将包升级至最新版本--top:仅更新有在 pyproject.toml 的包--dry-run:试运行,而不去修改 lock 文件--no-sync:只更新 lock 文件,但不更新包
如果你的依赖包有设置分组,还可以指定分组进行更新
1 | |
也可以指定分组更新分组里的某个包
1 | |
再加个 -d 就可以再指定 dev 依赖
1 | |
同样地,也可以指定 --prod 或者 --production 升级非 dev (即生产)的包。
4.8 切换 py
当你在初始化 pdm 项目时,就已经选定了当前的 Python 版本和可用的 Python 版本范围,后面如果想更改,可以使用 use 命令,但版本要受之前设定的版本范围约束。
假设允许范围是 python 3.9+,当前使用的是 python 3.10,可以直接切换过去。
1 | |
5. 命令别名
在 pyproject.toml 添加 [tool.pdm.scripts] 可以设置快捷命令别名,若项目的执行有非常多的参数,这种设定别名的方法将很有用。
[tool.pdm.scripts] 有两种形式
1 | |
但若想在参数中加注释,就必须得使用第二种方法,例如这样
1 | |
除了 cmd 之外,还有两个参数
一个是 shell 参数,从输出来看你应该和看出和 cmd 的区别,和 subprocess.Popen() with shell=True 差不多一个意思
一个是 env_file 参数,可以指定配置环境变量的文件
1 | |
如果想要把这个环境变量的文件不仅限于某个命令,而是 pdm run 全局,可以这样配置
1 | |
加 --list 或者 -l可以查看所有设置的快捷别名

对于每一个快捷命令,都可以设置 pre 和 post 命令:
- pre 命令:在每次快捷命令执行前会执行
- post 命令:在每次快捷命令执行后会执行
1 | |
6. 自动补全
pdm 的命令虽多,但并不复杂,并不太需要使用自动补全,若你真的需要补全,也可以实现。
对于不同的 shell,自动补全的配置方式都不太一样,这个在官网上有详细的说明。
如果你和我一样使用的 zsh,可以参照我的配置方式。
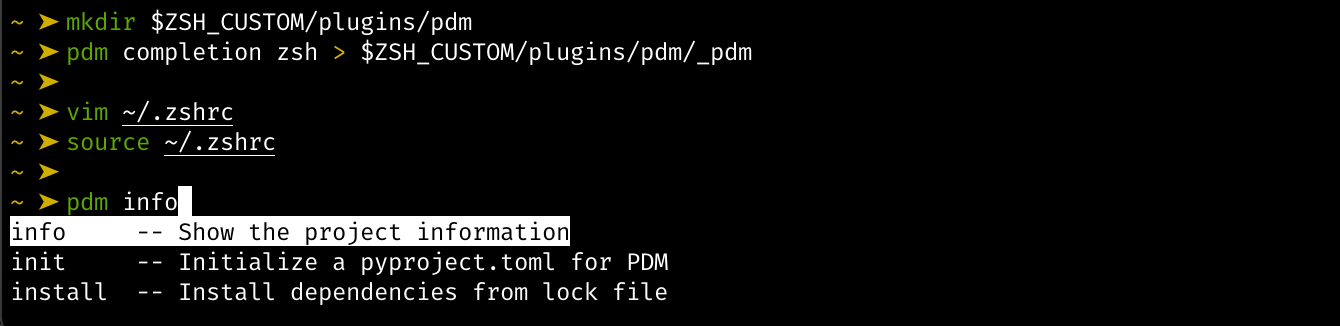
截图中间有一步是 vim ~/.zshrc ,是将 pdm 插件配置到 zsh 中
1 | |
7. 方案兼容
其他方案迁移到 pdm
pdm 足够好用,也足够开放,如果你当前使用的是其他的包管理器,比如 pipenv ,poetry,或者还在用最原始的 requirements.txt ,你也可以很方便的迁移到 pdm 中来:
- 使用 pdm import -f {file} 无需初始化,直接转换
- 执行 pdm init 或者 pdm install 的时候,会自动识别你当前的依赖情况并转换
pdm 迁移到其他方案
同样的,你也可以当 pdm 管理的项目,导出为其他方案
pyproject.toml 和 pdm.lock是 pdm 的两个核心文件。
pdm 做为一个后起之秀,也没有忘记向前兼容,它支持:
将 pyproject.toml 转成 setup.py
1
pdm export -f setuppy -o setup.py将 pdm.lock 转成 requirements.txt
1
pdm export -o requirements.txt
8. 总结一下
花了很大的力气,终于把 PDM 的基本用法给介绍完毕,相信一定会有人会提出质疑:这就是你所谓的 划时代的包管理器 ?
实际上,上面仅仅是入门操作,而 PDM 的一些核心知识,考虑到篇幅有限,我将这些进阶类的内容安排在后续文章,它将包括但不仅限于:
- PDM 的原理剖析:PEP 582 提案
- 发布包的构建:PEP 517 提案
- Hook 脚本的定义与使用
- 插件管理系统与自定义插件
- 缓存管理系统的介绍
这些内容是 PDM 的核心,只有理解了这些,你才能真正用好 PDM,到那时你会感慨:为什么 Guido 还不把这样的工具收编成标准的包管理工具?
12.7 【最强工具】方案六:pyenv
前面介绍过非常地 Python 包管理工具,有 pip、 venv、pipenv、poetry、pdm 等
今天来介绍一个更高层次的管理工具,可以直接管理 Python 解释器的版本,同时也可以管理虚拟环境,它就是 pyenv。
pyenv 的一个典型使用场景就是,比如一个老项目需要使用 Python 2.x ,而另一个新项目需要 Python 3.x 。而 virtualenv 主要是用来管理相同版本 Python 不同项目的包的依赖不同的问题,就无法解决这个问题,这个时候就需要 pyenv。
有了 pyenv,你可以一键安装、切换到任意你需要的 python 版本,从 2.1.3 -> 3.12-dev(稿前为止最新版本)。
除了常规的 CPython 之外,它还可以管理其他的 python 和 工具,包括:
- graalpython
- ironpython
- jython
- micropython
- pypy
- miniconda
- anaconda
- pyston
- stackless
- 等等
好家伙,我愿称之为 Python Env Master,而上面每个工具,还有细分的版本,不用担心,pyenv 全部都有收录,可以满足你几乎所有需求了。
1. 安装与配置
先安装 pyenv,由于我使用 macOS,使用 brew 可以很方便的安装它
1 | |
安装 pyenv 会安装相当多的依赖包,包括:
pyenv: pyenv 工具自身pyenv-update: 用来更新 pyenv 的插件pyenv-doctor: 验证 pyenv 和依赖是否安装的插件pyenv-which-ext: 用来寻找相同命令的插件
使用 pyenv help 查看一下帮助命令,如果没有报错,说明安装成功
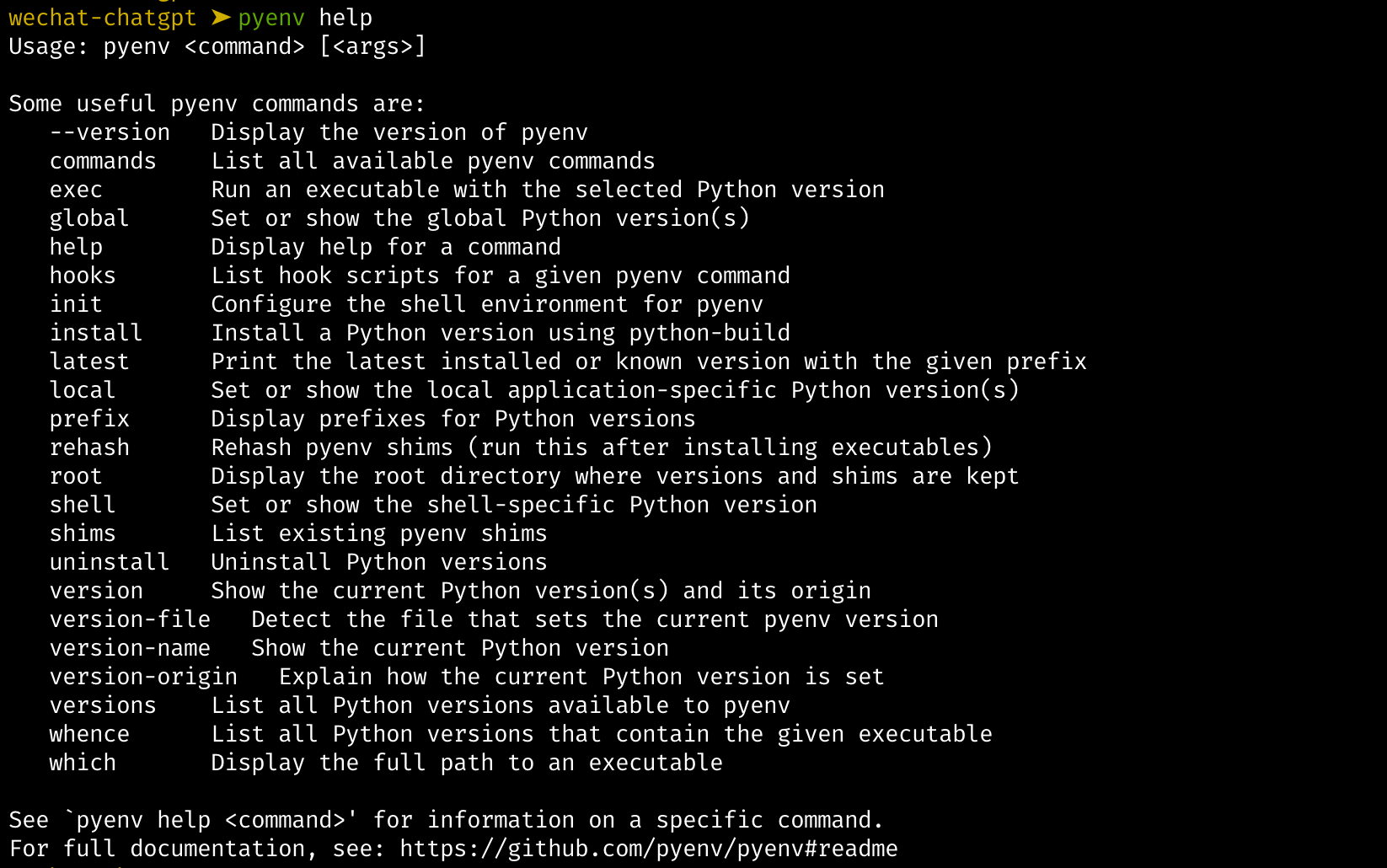
另外,除了 pyenv,还要安装一个插件 pyenv-virtualenv,它是专门用来管理 vitual environments 的
1 | |
安装好后,还要进行一下初始化。
为了下次新开终端也可以立马使用 pyenv,可以将下面两条初始化命令写入 .bash_profile或 .zshrc(根据自己实际情况而定)
1 | |
然后再次执行 source 使之立即执行
1 | |
2. 基本使用
环境配置好后,那如何知道有哪些版本可以安装呢?
可以使用如下命令查询所有可安装的项
1 | |
比如我现在需要安装的是 python3.8,但我不知道最新的小版本是多少,就可以使用上面命令查询一下

发现最新的版本是 3.8.16,于是直接使用 install 来安装它,再使用 pyenv versions 就可以看到我们安装的版本了。
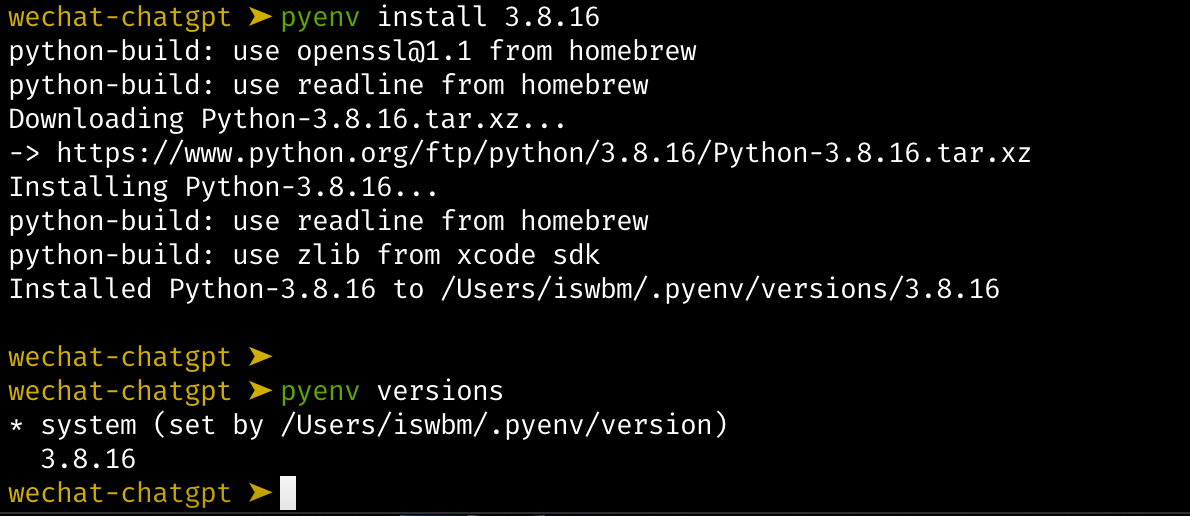
从上面截图可以看到,安装完后并不会自动切换过去,目前还是指向系统自带的 Python,需要手动进行版本的切换,切换方法有如下两种:
1 | |
那这种有什么区别呢?简单来说:
- global:设置全局的 Python 解释器,不管你在任何路径下都是使用该版本的 Python
- local: 设置的是某特定目录(或项目)的 Python 解释器,只有在该目录下才能用该版本的 Python
我们使用 pyenv versions 可以观察下指向的 Python 版本,可以发现
- 只要进入 wechat-chatgpt 目录,就会使用
.python-version里的解释器 - 一旦离开 wechat-chatgpt 目录,就又会使用全局的 Python 解释器
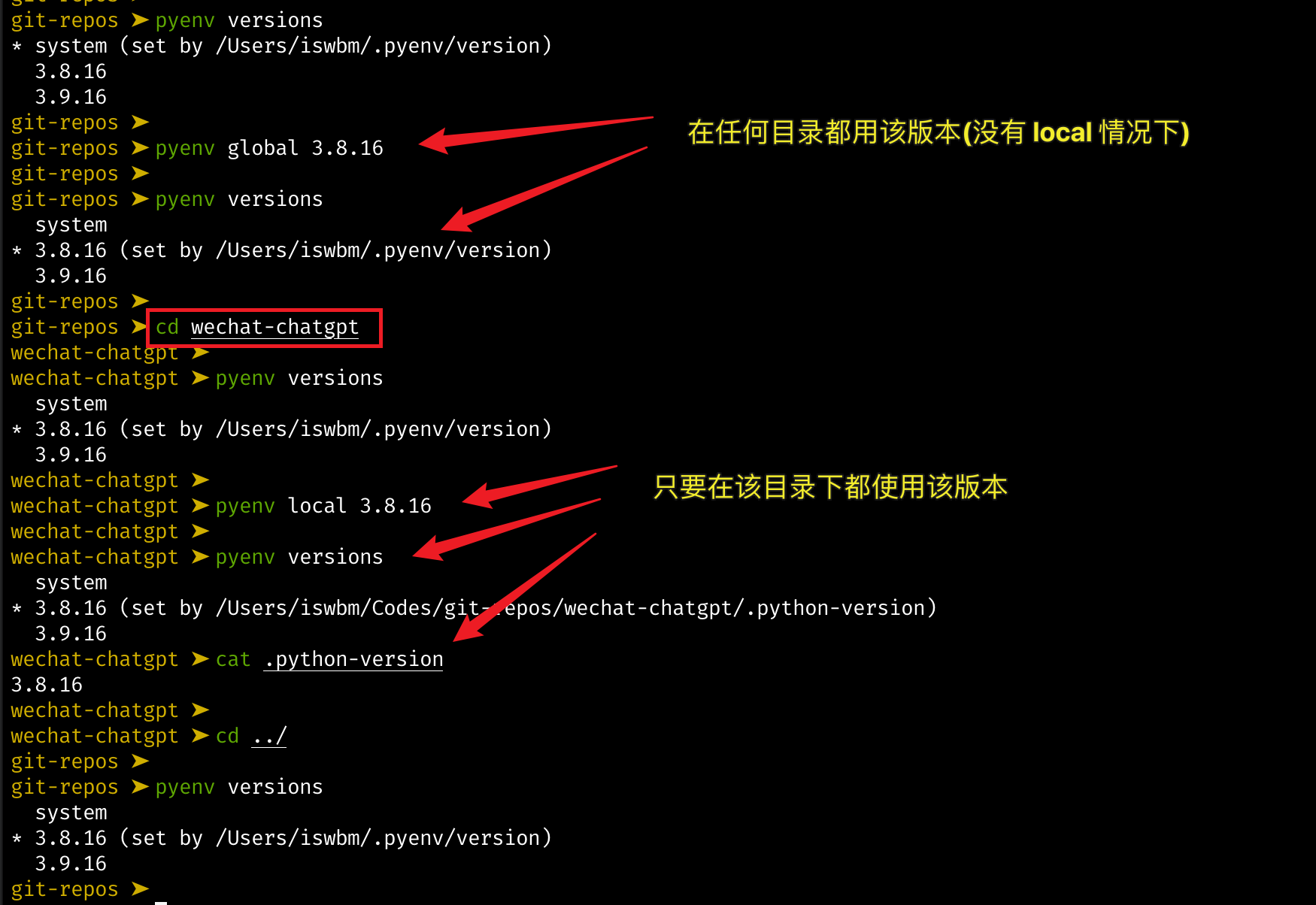
想要切换回系统自带的 Python ,也是同样道理,将版本换成 system 即可
1 | |
3. 虚拟环境
pyenv 管理的每一个版本在 ~/.pyenv/versions 下都有对应的目录
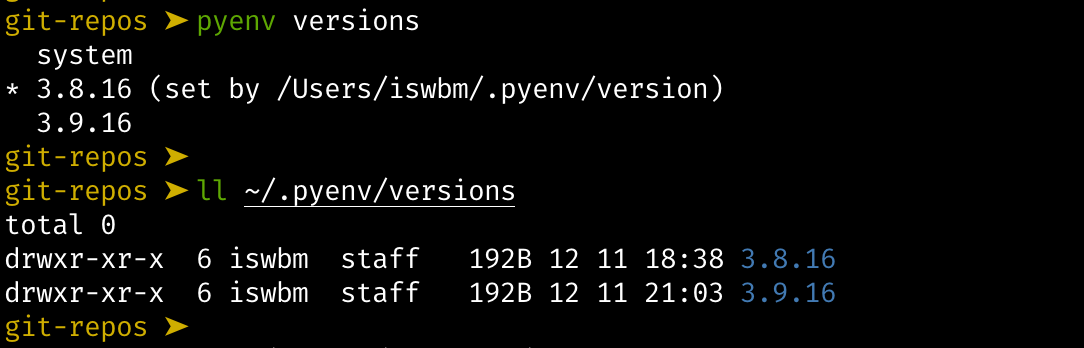
当然 pyenv 创建的虚拟环境也是在这下面,只不过我还没有创建过虚拟环境。
现在使用使用如下命令创建一个
1 | |
可以发现不管在 ~/.pyenv/versions目录下还是 pyenv versions都会新增一个环境
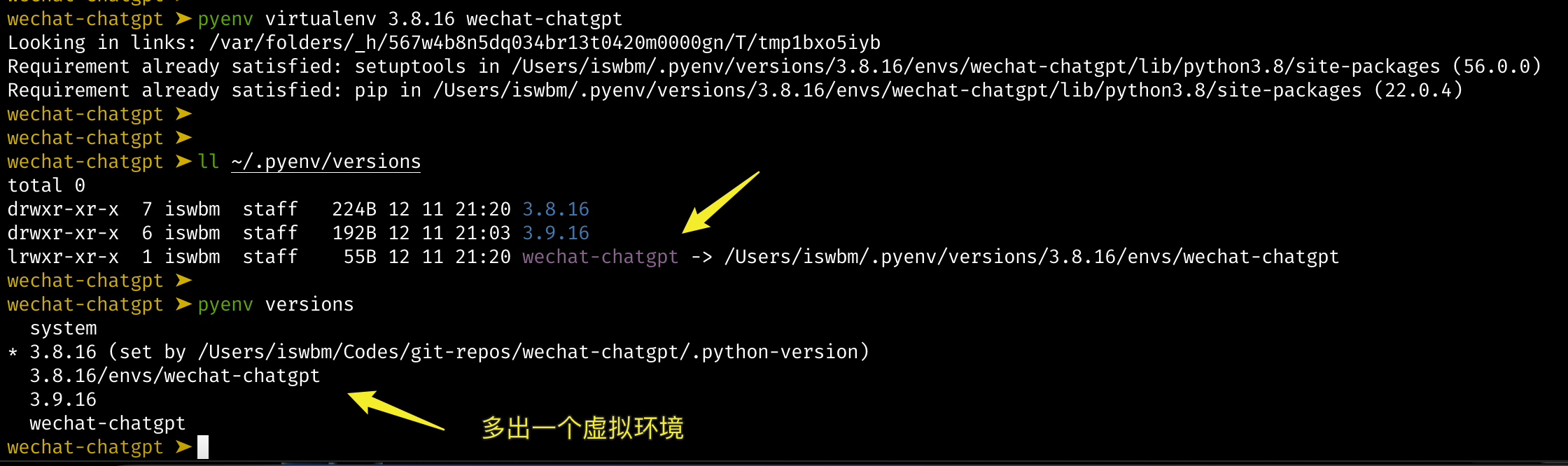
只要在对应的目录下使用 local 指定 Python 版本,就实现了项目与 Python 版本的绑定。实在是太友好啦~
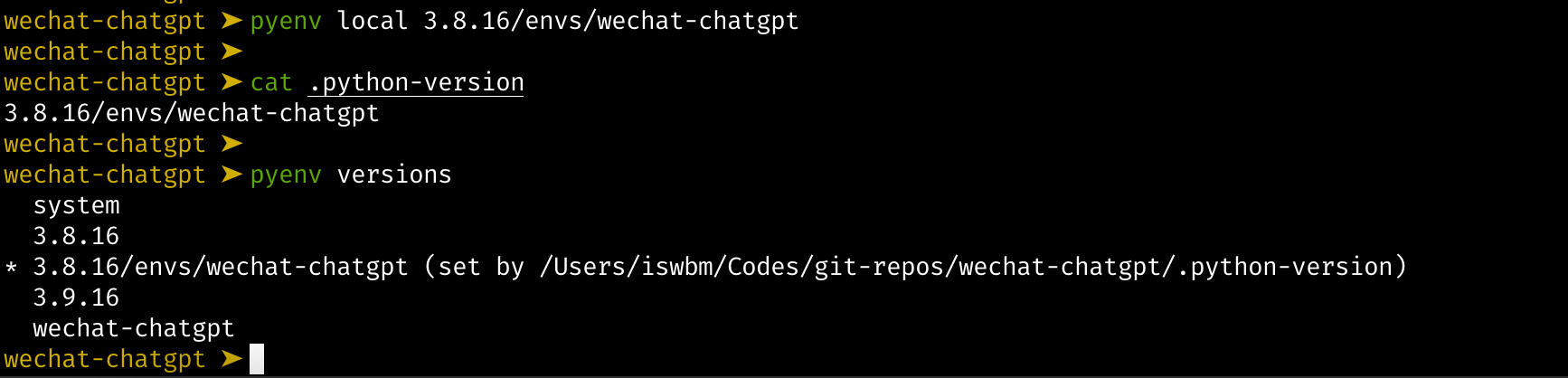
另外列几个虚拟环境管理的命令
- 查看所有虚拟环境:pyenv virtualenvs
- 删除指定虚拟环境:pyenv virtualenv-delete
- 查看虚拟环境的真实的 Python 环境:pyenv virtualenv-prefix
4. 总结一下
pyenv 从解释器管理到虚拟环境管理,给了 Python 工程师一站式的体验,对于那些需要维护很多项目并且有些项目依赖了不同的 Python 版本的人来说,请一定在你的电脑上安装 pyenv,因为它实在太方便了。
目前我发现的唯一的不足,可能就是它只能管理通过 pyenv 安装的解释器,而对于系统上早已存在的 Python 解释器,并不会去扫描纳管,但这问题实在太小,小到可以忽略不计。
第十三章:绝佳工具
13.1 【静态检查】mypy 的使用
Python 3.6以后,允许为参数和函数返回类型添加类型标注(type hinting)。
这就为程序进行静态类型检查提供了可能,mypy就是一个利用类型注解对python代码进行静态类型检查的工具。
使用pip安装
1 | |
1. 有问题的代码
下面的代码在执行时不会报任何错误,但严格来讲是存在问题的。
1 | |
在创建Stu实例时,age参数应该传入int类型数据。但由于python是动态类型语言,因此,传入float或者字符串都不会引发错误,除非在后续的属性使用中对类型有明确要求。
这样的代码是不安全的,在程序运行前,可以通过静态类型检查来发现问题,这需要类型标注的帮助
2. 添加类型标注
将上面的代码修改成如下
1 | |
仅仅是添加了类型标注,我所使用的pycharm就已经提示我创建Stu实例时的age参数有问题,这种提示是委婉的,你可以不用理会。
接下来使用mypy进行静态类型检查
1 | |
mypy准确的找出了两处类型与参数预期不符的情况## 13.2 【代码测试】pytest 的使用
Pytest 是一个比较成熟且功能完备的 Python 测试框架。其提供完善的在线文档,并有着大量的第三方插件和内置帮助,适用于许多小型或大型项目。Pytest 灵活易学,打印调试和测试执行期间可以捕获标准输出,适合简单的单元测试到复杂的功能测试。还可以执行 nose, unittest 和 doctest 风格的测试用例,甚至 Django 和 trial。支持良好的集成实践, 支持扩展的 xUnit 风格 setup,支持非 python 测试。支持生成测试覆盖率报告,支持 PEP8 兼容的编码风格。
1. 基本使用
1 | |
用例查找规则
如果不带参数运行 pytest,那么其先从配置文件(pytest.ini,tox.ini,setup.cfg)中查找配置项 testpaths 指定的路径中的 test case,如果没有则从当前目录开始查找,否者,命令行参数就用于目录、文件查找。查找的规则如下:
- 查找指定目录中以
test开头的目录 - 递归遍历目录,除非目录指定了不同递归
- 查找文件名以
test_开头的文件 - 查找以
Test开头的类(该类不能有 init 方法) - 查找以
test_开头的函数和方法并进行测试
如果要从默认的查找规则中忽略查找路径,可以加上 --ingore 参数,例如:
1 | |
调用 pytest
- py.test:
Pytest 提供直接调用的命令行工具,即 py.test,最新版本 pytest 和 py.test 两个命令行工具都可用
- python -m pytest:
效果和 py.test 一样, 这种调用方式在多 Python 版本测试的时候是有用的, 例如测试 Python3:
1 | |
部分参数介绍
1 | |
执行选择用例
- 执行单个模块中的全部用例:
1 | |
- 执行指定路径下的全部用例:
1 | |
- 执行字符串表达式中的用例:
1 | |
比如 “MyClass?and not method”,选择 TestMyClass.test_something,排除了TestMyClass.test_method_simple。
- 导入 package,使用其文件系统位置来查找和执行用例。执行 pkg 目录下的所有用例:
1 | |
- 运行指定模块中的某个用例,如运行 test_mod.py 模块中的 test_func 测试函数:
1 | |
- 运行某个类下的某个用例,如运行 TestClass 类下的 test_method 测试方法:
1 | |
2. 断言
通常情况下使用 assert 语句就能对大多数测试进行断言。对于异常断言,可以使用上下文管理器 pytest.raises:
1 | |
对于警告断言,可以使用上下文管理器 pytest. warns:
1 | |
如果仅需断言 DeprecationWarning 或者 PendingDeprecationWarning 警告,可以使用 pytest.deprecated_call:
1 | |
对于自定义类型的 assert 比较断言,可以通过在 conftest.py 文件中实现pytest_assertrepr_compare 函数来实现:
1 | |
如果需要手动设置失败原因,可以使用 pytest.fail:
1 | |
使用 pytest.skip 和 pytest.xfail 能够实现跳过测试的功能,skip 表示直接跳过测试,而 xfail 则表示存在预期的失败,但两者的效果差不多:
1 | |
pytest.importorskip 可以在导入失败的时候跳过测试,还可以要求导入的包要满足特定的版本:
1 | |
断言近似相等可以使用 pytest.approx:
1 | |
3. conftest.py
从广义理解,conftest.py 是一个本地的 per-directory 插件,在该文件中可以定义目录特定的 hooks 和 fixtures。py.test 框架会在它测试的项目中寻找 conftest.py 文件,然后在这个文件中寻找针对整个目录的测试选项,比如是否检测并运行 doctest 以及应该使用哪种模式检测测试文件和函数。
总结起来,conftest.py 文件大致有如下几种功能:
- Fixtures: 用于给测试用例提供静态的测试数据,其可以被所有的测试用于访问,除非指定了范围
- 加载插件: 用于导入外部插件或模块:
1 | |
- 定义钩子: 用于配置钩子(hook),如 pytest_runtest_setup、pytest_runtest_teardown、pytest_config 等:
1 | |
再比如添加命令行选项的钩子:
1 | |
- 测试根路径: 如果将 conftest.py 文件放在项目根路径中,则 pytest 会自己搜索项目根目录下的子模块,并加入到 sys.path 中,这样便可以对项目中的所有模块进行测试,而不用设置 PYTHONPATH 来指定项目模块的位置。
可以有多个 conftest.py 文件同时存在,其作用范围是目录。例如测试非常复杂时,可以为特定的一组测试创建子目录,并在该目录中创建 conftest.py 文件,并定义一个 futures 或 hooks。就像如下的结构:
1 | |
4. Fixtures
fixture 是 pytest 特有的功能,它用 pytest.fixture 标识,定义在函数前面。在编写测试函数的时候,可以将此函数名称做为传入参数,pytest 将会以依赖注入方式,将该函数的返回值作为测试函数的传入参数。
1 | |
作为参数
fixture 可以作为其他测试函数的参数被使用,前提是其必须返回一个值:
1 | |
一个更加实用的例子:
1 | |
作为 setup
fixture 也可以不返回值,这样可以用于在测试方法运行前运行一段代码:
1 | |
这种方式与 setup_method、setup_module 等的用法相同,其实它们也是特殊的 fixture。
在上例中,有一个测试用了 pytest.mark.usefixtures 装饰器来标记使用哪个 fixture,这中用法表示在开始测试前应用该 fixture 函数但不需要其返回值。使用这种用法时,通过 addfinallizer 注册释放函数,以此来做一些“善后”工作,这类似于 teardown_function、teardown_module 等用法。示例:
1 | |
作用范围
fixtrue 可以通过设置 scope 参数来控制其作用域(同时也控制了调用的频率)。如果 scope='module',那么 fixture 就是模块级的,这个 fixture 函数只会在每次相同模块加载的时候执行。这样就可以复用一些需要时间进行创建的对象。fixture 提供三种作用域,用于指定 fixture 初始化的规则:
- function:每个测试函数之前执行一次,默认
- module:每个模块加载之前执行一次
- session:每次 session 之前执行一次,即每次测试执行一次
反向请求
fixture 函数可以通过接受 request 对象来反向获取请求中的测试函数、类或模块上下文。例如:
1 | |
有时需要全面测试多种不同条件下的一个对象,功能是否符合预期。可以通过设置 fixture 的 params 参数,然后通过 request 获取设置的值:
1 | |
设置 params 参数后,运行 test 时将生成不同的测试 id,可以通过 ids 自定义 id:
1 | |
运行以上实例会有如下结果:
1 | |
自动执行
有时候需要某些 fixture 在全局自动执行,如某些全局变量的初始化工作,亦或一些全局化的清理或者初始化函数。这时可以通过设置 fixture 的 autouse 参数来让 fixture 自动执行。设置为 autouse=True 即可使得函数默认执行。以下例子会在开始测试前清理可能残留的文件,接着将程序目录设置为该目录,:
1 | |
5. setup/teardown
setup/teardown 是指在模块、函数、类开始运行以及结束运行时执行一些动作。比如在一个函数中测试一个数据库应用,测需要在函数开始前连接数据库,在函数运行结束后断开与数据库的连接。setup/teardown 是特殊的 fixture,其可以有一下几种实现方式:
1 | |
有时候,还希望有全局的 setup 或 teardown,以便在测试开始时做一些准备工作,或者在测试结束之后做一些清理工作。这可以用 hook 来实现:
1 | |
也可以用 fixture 的方式实现:
1 | |
6. Markers
marker 的作用是,用来标记测试,以便于选择性的执行测试用例。Pytest 提供了一些内建的 marker:
1 | |
例如一个使用参数化测试的例子:
1 | |
除了内建的 markers 外,pytest 还支持没有实现定义的 markers,如:
1 | |
通过使用 -m 参数可以让 pytest 选择性的执行部分测试:
1 | |
更详细的关于 marker 的说明可以参考官方文档:
7. 第三方插件
- pytest-randomly: 测试顺序随机
- pytest-xdist: 分布式测试
- pytest-cov: 生成测试覆盖率报告
- pytest-pep8: 检测代码是否符合 PEP8 规范
- pytest-flakes: 检测代码风格
- pytest-html: 生成 html 报告
- pytest-rerunfailures: 失败重试
- pytest-timeout: 超时测试
8. 参考资料
- https://docs.pytest.org/en/latest/example/
- https://docs.pytest.org/en/latest/assert.html
- https://docs.pytest.org/en/latest/reference.html
- http://doc.pytest.org/en/latest/xunit_setup.html
- https://docs.pytest.org/en/latest/skipping.html
- https://docs.pytest.org/en/latest/fixture.html
- http://senarukana.github.io/2015/05/29/pytest-fixture/
- https://docs.pytest.org/en/latest/parametrize.html
- https://docs.pytest.org/en/latest/plugins.html## 13.3 【代码提交】pre-commit hook
代码规范、测试是开发中很重要的一环,重要性无需我多说。我们需要一些自动化工具,来帮助我们更轻松地管理项目。本文推荐几个实用的自动化工具。
pre-commit 我在之前的一篇文章 推荐一些维护大型 Python 项目的工具中简要提到过,这里再稍微讲一下。
pre-commit 用到一个配置文件:.pre-commit-config.yaml,官方文档在这里。这里针对 Python 项目,希望 git precommit hooks 能够实现以下功能:能找出不符合 pep8规范的代码,并且能够自动格式化。这需要用到两个工具:black和flake8,black自动格式化,flake8检测代码不规范的地方。
整个的 workflow 如下图所示:

具体的执行步骤如下:
- 安装 pre-commit :
pip install pre-commit - 写
.pre-commit-config.yaml配置文件 - 用
pre-commit install安装git hooks到你的.git/目录
我们的.pre-commit-config.yaml很简单,如下:
1 | |
然后我们下一次提交 commit 的时候,会先运行black和flake8,检查出哪有不规范的地方,并且能自动帮你格式化。你修改之后重新提交 commit,就能顺利提交了。
实际操作一下:
新建一个测试文件:bad_pep8.py:

有好几处不符合 pep8规范,我们试着 commit 一下:
可以看到两个 hook 都没有通过,另外 black帮我们把代码格式化了。

同时flake8提示我们x变量定义了但是没有使用,把这一行删掉,然后重新add 并 commit:
如果你觉得没有必要强制要求不能定义变量而不使用(从输出可以看出这个规范的编号为F841),可以在项目根目录建一个.flake8配置文件,如下图。更加详细的配置请看官方文档。
1 | |
13.4 【项目生成】cookiecutter 的使用
IDE都会有一套生成新项目的向导(Wizard),通过点点点,就可以得到一个可以运行的某类程序。 这样的程序,具备了推荐的项目结构,配置的基本的编译、打包、测试,尽管功能只是一个helloworld。 这个功能,极大地降低了初学者的进入门槛,也统一了某类项目的文件结构,是一个了不起的进步。 最早使用这类手段的,似乎是Visual Studio。
令人惋惜的是,Python的IDE——PyCharm并不自带这个功能。 这其中,也有Python项目千变万化的因素。 Python的适用范围太广,从桌面到服务器,从游戏到数据分析,都做一套显然投入太大。 而Python又是一门解释型语言,随便写个文件也能直接执行,似乎没有这个必要。
然而,我要说,还是有必要的!
因为Python系缺失一个Wizard,也缺少项目结构的标准,于是出现了cookiecutter。 这是一个项目生成器,也可称为引擎,因为它只完成了最核心的功能。 真正决定一个项目长什么样的模板,却可以自由定制。 也因此,它能生成任何一种语言的项目。
1. 快速安装
1 | |
cookiecutter就是一个已经发布的Python包,因此用Python的手段可以直接安装。
对于非Python系的程序员来说,也可以使用包管理器的方式安装。
1 | |
2. 如何使用
首先,寻找一个合适的cookiecutter项目。 最主要的方式,就是访问其GitHub主页的A Pantry Full of Cookiecutters。
如果挑选完毕(这里以cookiecutter-pypackage为例),则可直接执行cookiecutter生成项目。
1 | |
在项目生成过程中,会产生一些提示,需要输入对应信息。 这和各类Wizard的GUI中,填写项目名、包名什么的,是同类操作。 以上是,除了项目名叫trycookie,基本都选默认的一个结果。
查看项目结构:
1 | |
如此庞大而复杂的一个项目结构,融合了作者audreyr对一个开源PyPI项目的理解。 虽然未必适用于任何一个人,但对于什么也不懂的菜鸟来说,却无疑是福音。
3. 基本原理
cookiecutter的工作原理,是先下载一个模板项目,然后替换模板项目的某些内容,生成新的项目。 在以上的示例中,https://github.com/audreyr/cookiecutter-pypackage.git就是一个项目的Git链接。 这可以换成任何一个可以用git clone来下载的链接,包括各种私有Git托管平台。
如果是GitHub,还可以用以下的等效形式:
1 | |
cookiecutter的简短形式,支持以下三种平台。
| Platform | abbreviation |
|---|---|
| GitHub | gh |
| BitBucket | bb |
| GitLab | gl |
cookiecutter也支持Mercurial(hg)。
1 | |
使用过模板的项目,默认都已经被下载到~/.cookiecutter目录下。 如果需要再次使用,而又无需更新,可以直接用项目名。
1 | |
利用这个特点,可以先用各种手段,把模板项目下载到~/.cookiecutter目录下,再来使用。
参考:Usage — cookiecutter 1.6.0 documentation
4. 配置文件
默认情况下,~/.cookiecutterrc就是配置文件。 它实际上是一个YAML文件。 以下是孤的配置文件示例。
1 | |
可配置项中,default_context是设置生成项目时,一些提示信息的默认参数。 cookiecutters_dir则是项目的下载位置,一般默认就好。 abbreviations是自定义简短形式,属于高级定制功能,仅适用于重度用户。 通常,填一填default_context就好。
如果对~/.cookiecutterrc这个配置文件的名称和位置不满意, 可以通过环境变量COOKIECUTTER_CONFIG, 或者在命令行指定参数--config-file来指定新的配置文件。
参考:User Config (0.7.0+) — cookiecutter 1.6.0 documentation
5. 总结一下
cookiecutter是一个简单好用的项目生成器引擎,并且已经有很多各种类型的模板。 除了Python项目,还有很多其它语言的项目模板。 它可以极大地省去一个项目初始化的重复劳动,也可以帮助菜鸟程序员成长。
当然,如果不满意,还是可以自己修改、定制模板的。